Ограничения апплета
Программирование апплетов настолько ограничено, что часто рассматривается как пребывание “внутри песочницы”, так как вы всегда есть кто-то — то есть, система безопасности Java времени выполнения — наблюдающий за вами.
Однако вы можете выйти из песочницы и писать обычные приложения, а не апплеты, в этом случае вы можете получить доступ к другим возможностям вашей OS. Мы писали обычные приложения на протяжении всей книги, но они были консольными приложениями без каких-то графических компонентов. Swing также можно использовать для построения GUI обычных приложений.
Обычно вы можете ответить на вопрос, что позволено делать апплету, взглянув на то, для чего он предназначен: расширить функциональность Web страницы в броузере. Так как, как тот, кто бродит по Internet, вы никогда реально не знаете, расположена ли Web страница дружественно к вам или нет, вам нужен код, запуск которого безопасен. Так что вы, вероятно, заметите огромные ограничения:
Апплет не может касаться локального диска. Это означает запись или чтение, так как вы не захотите, чтобы апплет прочел и передал приватную информацию через Internet без вашего разрешения. Запись, конечно, предотвращается, так как это открывает доступ вирусам. Java предлагает цифровую подпись для апплетов. Многие ограничения апплетов освобождаются, когда вы согласитесь доверить апплету (который подписан источником, которому вы доверяете) доступ к вашей машине. Апплеты занимают много времени при отображении, так как вы должны загрузить все вещи каждый раз, включая разные обращения к серверам для разных классов. Ваш броузер может кэшировать апплеты, но это не гарантируется. Поэтому, вы всегда пакуйте ваши апплеты в JAR (Java Archive) файл, который комбинирует все компоненты апплета (включая другие .class файлы наряду с картинками и звуками) вместе в единственный компрессированный файл, который может быть загружен в одном обращении сервера. “Цифровая подпись” возможна для каждого индивидуального вхождения в JAR файл.
Ограничения исключений
Когда вы перегружаете метод, вы можете выбросить только те исключения, которые указаны в версии базового класса этого метода. Это полезное ограничение, так как это означает, что код, работающий с базовым классом, будет автоматически работать с любым другим объектом, наследованным от базового класса (конечно, это фундаментальная концепция ООП), включая исключения.
Этот пример демонстрирует виды налагаемых ограничений (времени компиляции) на исключения:
//: c10:StormyInning.java
// Перегруженные методы могут выбрасывать только те
// исключения, которые указаны в версии
// базового класса, или унаследованное от
// исключения базового класса.
class BaseballException extends Exception {} class Foul extends BaseballException {} class Strike extends BaseballException {}
abstract class Inning { Inning() throws BaseballException {} void event () throws BaseballException { // На самом деле ничего не выбрасывает
} abstract void atBat() throws Strike, Foul; void walk() {} // Ничего не выбрасывает
}
class StormException extends Exception {} class RainedOut extends StormException {} class PopFoul extends Foul {}
interface Storm { void event() throws RainedOut; void rainHard() throws RainedOut; }
public class StormyInning extends Inning implements Storm { // можно добавить новое исключение для
// конструкторов, но вы должны работать
// с базовым исключеним конструктора:
StormyInning() throws RainedOut, BaseballException {} StormyInning(String s) throws Foul, BaseballException {} // Обычный метод должен соответствовать базовому классу:
//! void walk() throws PopFoul {} //Ошибка компиляции
// Интерфейс НЕ МОДЕТ добавлять исключения к существующим
// методам базового класса:
//! public void event() throws RainedOut {}
// Если метод еще не существует в базовом классе
// исключение допустимо:
public void rainHard() throws RainedOut {} // Вы можете решить не выбрасывать исключений вообще,
// даже если версия базового класса делает это:
public void event() {} // Перегруженные методы могут выбрасывать
// унаследованные исключения:
void atBat() throws PopFoul {} public static void main(String[] args) { try { StormyInning si = new StormyInning(); si.atBat(); } catch(PopFoul e) { System.err.println("Pop foul"); } catch(RainedOut e) { System.err.println("Rained out"); } catch(BaseballException e) { System.err.println("Generic error"); } // Strike не выбрасывается в унаследованной версии.
try { // Что случится при обратном приведении?
Inning i = new StormyInning(); i.atBat(); // Вы должны ловить исключения от метода
// версии базового класса:
} catch(Strike e) { System.err.println("Strike"); } catch(Foul e) { System.err.println("Foul"); } catch(RainedOut e) { System.err.println("Rained out"); } catch(BaseballException e) { System.err.println( "Generic baseball exception"); } } } ///:~
В Inning вы можете увидеть, что и конструктор, и метод event( ) говорят о том, что они будут выбрасывать исключение, но они не делают этого. Это допустимо, потому что это позволяет вам заставить пользователя ловить любое исключение, которое может быть добавлено и перегруженной версии метода event( ). Эта же идея применена к абстрактным методам, как видно в atBat( ).
Интересен interface Storm, потому что он содержит один метод (event( )), который определен в Inning, и один метод, которого там нет. Оба метода выбрасывают новый тип исключения: RainedOut. Когда StormyInning расширяет Inning и реализует Storm, вы увидите, что метод event( ) в Storm не может изменить исключение интерфейса event( ) в Inning. Кроме того, в этом есть здравый смысл, потому что, в противном случае, вы никогда не узнаете, что поймали правильную вещь, работая с базовым классом. Конечно, если метод, описанный как интерфейс, не существует в базовом классе, такой как rainHard( ), то нет проблем, если он выбросит исключения.
Ограничения для исключений не распространяются на конструкторы. Вы можете видеть в StormyInning, что конструктор может выбросить все, что хочет, не зависимо от того, что выбрасывает конструктор базового класса. Но, так как конструктор базового класса всегда, так или иначе, должен вызываться (здесь автоматически вызывается конструктор по умолчанию), конструктор наследованного класса должен объявить все исключения конструктора базового класса в своей спецификации исключений. Заметьте, что конструктор наследованного класса не может ловить исключения, выброшенные конструктором базового класса.
Причина того, что StormyInning.walk( ) не будет компилироваться в том, что она выбрасывает исключение, которое Inning.walk( ) не выбрасывает. Если бы это допускалось, то вы могли написать код, вызывающий Inning.walk( ), и не иметь обработчика для любого исключения, а затем, когда вы заменили объектом класса, унаследованного от Inning, могло начать выбрасываться исключение и ваш код сломался бы. При ограничивании методов наследуемого класса в соответствии со спецификацией исключений методов базового класса замена объектов допустима.
Перегрузка метода event( ) показывает, что версия метода наследованного класса может не выбрасывать исключение, даже если версия базового класса делает это. Опять таки это хорошо, так как это не нарушит ни какой код, который написан с учетом версии базового класса с выбрасыванием исключения. Сходная логика применима и к atBat( ), которая выбрасывает PopFoul - исключение, унаследованное от Foul, выбрасываемое версией базового класса в методе atBat( ). Таким образом, если кто-то напишет код, который работает с классом Inning и вызывает atBat( ), он должен ловить исключение Foul. Так как PopFoul наследуется от Foul, обработчик исключения также поймает PopFoul.
Последнее, что нас интересует - это main( ). Здесь вы можете видеть, что если вы имеете дело с объектом StormyInning, компилятор заставит вас ловить только те исключения, которые объявлены для этого класса, но если вы выполните приведение к базовому типу, то компилятор (что совершенно верно) заставит вас ловить исключения базового типа. Все эти ограничения производят более устойчивый код обработки исключений [55].
Полезно понимать, что хотя спецификация исключений навязываются компилятором во время наследования, спецификация исключений не является частью метода типа, который включает только имя метода и типы аргументов. Поэтому вы не можете перегрузить метод, основываясь на спецификации исключений. Кроме того, только потому, что спецификация исключений существует в версии метода базового класса, это не означает, что она должна существовать в версии метода наследованного класса. Это немного отличается от правил наследования, по которым метод базового класса должен также существовать в наследуемом классе. Есть другая возможность: “спецификации исключения интерфейса” для определенного метода может сузиться во время наследования и перегрузки, но он не может расшириться — это точно противоречит правилам для интерфейса класса при наследовании.
Ограничивание
Большинство процедурных языков имеют концепцию границ. Они определяют и видимость, и время жизни имен, определенных в таких границах. В C, C++ и Java границы определяются расстановкой фигурных скобок {}. Так, например:
{ int x = 12; /* доступно только x */
{ int q = 96; /* доступны и x, и q */
} /* Доступно только x */
/* q “за границами” */
}
Переменная, определенная внутри границ доступна только до конца этой границы.
Выравнивание делает Java код легким для чтения. Так как Java - это язык свободной формы, дополнительные пробелы, табуляции и возврат каретки не влияют на результат программы.
Обратите внимание, что в не можете сделать следующее, хотя это разрешено в С и C ++:
{ int x = 12; { int x = 96; /* недопустимо */
} }
Компилятор объявит, что переменная x уже определена. Таким образом, C и C++ способны “прятать” переменные в больших границах, что не позволяется в Java, поскольку разработчики подумали, что это будет запутывать программы.
Окна диалогов
Окна диалогов - это окна, которые всплывают из других окон. Их назначение состоит в решении специфических проблем без изменения деталей оригинального окна. Окна диалогов часто используются в оконной среде программ, и менее часто используются в апплетах.
Для создания диалога вы наследуете от JDialog, который является просто видом окна, как и JFrame. JDialog имеет менеджер компоновки (по умолчанию это BorderLayout) и вы добавляете слушатель событий для работы с событиями. Одно значительное отличие возникает при вызове windowClosing( ). Оно состоит в том, что вам не нужно завершать приложение. Вместо этого вы освобождаете ресурсы, используемые окном диалога, вызывая dispose( ). Вот простой пример:
//: c13:Dialogs.java
// Создание и использование диалогов.
// <applet code=Dialogs width=125 height=75>
// </applet>
import javax.swing.*; import java.awt.event.*; import java.awt.*; import com.bruceeckel.swing.*;
class MyDialog extends JDialog { public MyDialog(JFrame parent) { super(parent, "My dialog", true); Container cp = getContentPane(); cp.setLayout(new FlowLayout()); cp.add(new JLabel("Here is my dialog")); JButton ok = new JButton("OK"); ok.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e){ dispose(); // Закрытие диалога.
} }); cp.add(ok); setSize(150,125); } }
public class Dialogs extends JApplet { JButton b1 = new JButton("Dialog Box"); MyDialog dlg = new MyDialog(null); public void init() { b1.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e){ dlg.show(); } }); getContentPane().add(b1); } public static void main(String[] args) { Console.run(new Dialogs(), 125, 75); } } ///:~
Как только JDialog создан, должен быть вызван метод show( ) для его отображения и активации. Для закрытия диалога должен быть вызван метод dispose( ).
Вы увидите, что ко всему, что всплывает из апплета, включая диалоги, нет доверия. То есть, вы получите всплывающее окно предупреждения. Это происходит потому, что, теоретически, есть возможность одурачить пользователя и заставить его думать, что он имеет дело с обычным местным приложением и дать ему напечатать номер его кредитной карточки, который будет передан через Web. Апплет всегда присоединяется в Web странице и его видно внутри вашего Web броузера, а диалог не присоединен, поэтому, теоретически, это становится возможным. В результате, не часто можно увидеть апплеты, использующие окна диалога.
Следующий пример сложнее; окно диалога сделано в виде решетки (используется GridLayout) кнопок специального рода, которые определены здесь, как класс ToeButton. Эти кнопки рисуют рамку вокруг себя и, в зависимости от состояния, остаются пустыми, рисуют “x” или “o” в середине. Изначально они пустые, а затем, в зависимости от того, кто включен, меняются на “x” или “o”. Однако также есть обратная и прямая связь между “x” и “o”, когда вы нажимаете кнопку. (Здесь воссоздается концепция tic-tac-toe, только немного более надоедливая, чем существующая.) Кроме того, диалог может быть установлен на любое число колонок и строк, путем изменения чисел в главном окне приложения.
//: c13:TicTacToe.java
// Демонстрация диалогов
// и создание ваших собственных компонент.
// <applet code=TicTacToe
// width=200 height=100></applet>
import javax.swing.*; import java.awt.*; import java.awt.event.*; import com.bruceeckel.swing.*;
public class TicTacToe extends JApplet { JTextField rows = new JTextField("3"), cols = new JTextField("3"); static final int BLANK = 0, XX = 1, OO = 2; class ToeDialog extends JDialog { int turn = XX; // Начинается с включения x
// w = число ячеек в ширину
// h = число ячеек в высоту
public ToeDialog(int w, int h) { setTitle("The game itself"); Container cp = getContentPane(); cp.setLayout(new GridLayout(w, h)); for(int i = 0; i < w * h; i++) cp.add(new ToeButton()); setSize(w * 50, h * 50); // JDK 1.3 закрытие диалога:
//#setDefaultCloseOperation(
//# DISPOSE_ON_CLOSE);
// JDK 1.2 закрытие диалога:
addWindowListener(new WindowAdapter() { public void windowClosing(WindowEvent e){ dispose(); } }); } class ToeButton extends JPanel { int state = BLANK; public ToeButton() { addMouseListener(new ML()); } public void paintComponent(Graphics g) { super.paintComponent(g); int x1 = 0; int y1 = 0; int x2 = getSize().width - 1; int y2 = getSize().height - 1; g.drawRect(x1, y1, x2, y2); x1 = x2/4; y1 = y2/4; int wide = x2/2; int high = y2/2; if(state == XX) { g.drawLine(x1, y1, x1 + wide, y1 + high); g.drawLine(x1, y1 + high, x1 + wide, y1); } if(state == OO) { g.drawOval(x1, y1, x1 + wide/2, y1 + high/2); } } class ML extends MouseAdapter { public void mousePressed(MouseEvent e) { if(state == BLANK) { state = turn; turn = (turn == XX ? OO : XX); } else
state = (state == XX ? OO : XX); repaint(); } } } } class BL implements ActionListener { public void actionPerformed(ActionEvent e) { JDialog d = new ToeDialog( Integer.parseInt(rows.getText()), Integer.parseInt(cols.getText())); d.setVisible(true); } } public void init() { JPanel p = new JPanel(); p.setLayout(new GridLayout(2,2)); p.add(new JLabel("Rows", JLabel.CENTER)); p.add(rows); p.add(new JLabel("Columns", JLabel.CENTER)); p.add(cols); Container cp = getContentPane(); cp.add(p, BorderLayout.NORTH); JButton b = new JButton("go"); b.addActionListener(new BL()); cp.add(b, BorderLayout.SOUTH); } public static void main(String[] args) { Console.run(new TicTacToe(), 200, 100); } } ///:~
Поскольку static может быть только на внешнем уровне класса, внутренний класс не может иметь статических данный или статических внутренних классов.
Метод paintComponent( ) рисует прямоугольник вокруг панели и “x” или “o”. Здесь выполняются достаточно скучные, но понятные вычисления.
Щелчок мыши захватывает MouseListener, который сначала проверяет, написано ли что-нибудь на панели. Если нет, опрашивается родительское окно, чтобы определить, что нужно включить, и это используется для установки состояния ToeButton. Через механизм внутреннего класса ToeButton обращается назад к своему родителю и меняется. Если кнопка в данный момент отображает “x” или “o”, то знак меняется. Вы можете видеть в расчетах последовательное использование тернарного оператора if-else, описанного в Главе 3. После смены состояния происходит перерисовка ToeButton.
Конструктор ToeDialog достаточно прост: он добавляет в GridLayout столько кнопок, сколько вы запросили, затем изменяет их размер до 50 пикселей на сторону для каждой кнопки.
TicTacToe устанавливает все приложение, создавая JTextField (для ввода числа строк и колонок кнопок в сетке) и кнопку “go” с присоединенным ActionListener. Когда нажимается кнопка, извлекаются данные из JTextField, и, так как они имеют форму String, они переводятся в int, используя статический метод Integer.parseInt( ).
Окна сообщений
Оконная среда часто содержит стандартный набор окон сообщений, которые позволяют вам быстро посылать сообщения пользователю или получать информацию от пользователя. В Swing эти окна сообщений содержаться в JOptionPane. Вы имеете много различных возможностей (некоторые из них достаточно изощренные), но, наверное, одна из наиболее часто использующихся, это окно сообщения и диалог подтверждения, вызывающийся при использовании JOptionPane.showMessageDialog( ) и JOptionPane. showConfirmDialog( ). Следующий пример показывает подмножество окон сообщения, поддерживаемых JOptionPane:
//: c13:MessageBoxes.java
// Демонстрация JoptionPane.
// <applet code=MessageBoxes
// width=200 height=150> </applet>
import javax.swing.*; import java.awt.event.*; import java.awt.*; import com.bruceeckel.swing.*;
public class MessageBoxes extends JApplet { JButton[] b = { new JButton("Alert"), new JButton("Yes/No"), new JButton("Color"), new JButton("Input"), new JButton("3 Vals") }; JTextField txt = new JTextField(15); ActionListener al = new ActionListener() { public void actionPerformed(ActionEvent e){ String id = ((JButton)e.getSource()).getText(); if(id.equals("Alert")) JOptionPane.showMessageDialog(null, "There's a bug on you!", "Hey!", JOptionPane.ERROR_MESSAGE); else if(id.equals("Yes/No")) JOptionPane.showConfirmDialog(null, "or no", "choose yes", JOptionPane.YES_NO_OPTION); else if(id.equals("Color")) { Object[] options = { "Red", "Green" }; int sel = JOptionPane.showOptionDialog( null, "Choose a Color!", "Warning", JOptionPane.DEFAULT_OPTION, JOptionPane.WARNING_MESSAGE, null, options, options[0]); if(sel != JOptionPane.CLOSED_OPTION) txt.setText( "Color Selected: " + options[sel]); } else if(id.equals("Input")) { String val = JOptionPane.showInputDialog( "How many fingers do you see?"); txt.setText(val); } else if(id.equals("3 Vals")) { Object[] selections = { "First", "Second", "Third" }; Object val = JOptionPane.showInputDialog( null, "Choose one", "Input", JOptionPane.INFORMATION_MESSAGE, null, selections, selections[0]); if(val != null) txt.setText( val.toString()); } } }; public void init() { Container cp = getContentPane(); cp.setLayout(new FlowLayout()); for(int i = 0; i < b.length; i++) { b[i].addActionListener(al); cp.add(b[i]); } cp.add(txt); } public static void main(String[] args) { Console.run(new MessageBoxes(), 200, 200); } } ///:~
Чтобы быть способным написать единственный ActionListener, я использую несколько рискованный подход проверки String метки кнопки. Проблема при этом в том, что легко получить слегка искаженную кнопку, обычно с большой буквы, и эта ошибка может быть трудна для обнаружения.
Обратите внимание, что showOptionDialog( ) и showInputDialog( ) обеспечивают возврат объекта, который содержит введенное пользователем значение.
Online документация
Язык Java и библиотеки от Sun Microsystems (доступные для свободной загрузки) идут вместе с документацией в электронном виде, которые можно прочитать в любом Web-броузере и, практически, любая реализация языка Java третьих фирм имеет ту же или аналогичную документацию. Практически каждая книга, изданная про Java повторяет эту документацию. То есть, либо она уже у вас есть, либо вы можете ее свободно загрузить, поэтому, до тех пор пока в этом не будет крайней необходимости, эта книга не будет повторять документацию, так как вы гораздо быстрее найдете описание класса используя свой Web-броузер, чем листая книгу (и скорее всего on-line документация будет более современна). Книга будет давать дополнительное, к существующему, описание классов только в том случае, если это необходимо для понимания конкретного примера.
Оператор запятая
Запятая используется в C и C++ нетолько как разделитель в списке аргументов функции, но также как оператор последовательности вычислений. Единственное место, где оператор запятая используется в Java - это цикл for, который будет описан позже в этой главе.
Ранее в этой главе я заявил, что оператор запятая (не разделитель запятая, который используется для разделения определений и аргументов функции) имеет в Java только один тип использования: в управляющих выражениях цикла for. И в разделе инициализации, и в разделе шага управляющего выражения вы можете использовать несколько инструкций, разделенных запятыми, и эти инструкции будут вычисляться последовательно. Предыдущий кусок кода использует эту возможность. Вот другой пример:
//: c03:CommaOperator.java
public class CommaOperator { public static void main(String[] args) { for(int i = 1, j = i + 10; i < 5; i++, j = i * 2) { System.out.println("i= " + i + " j= " + j); } } } ///:~
Вот вывод:
i= 1 j= 11 i= 2 j= 4 i= 3 j= 6 i= 4 j= 8
Вы можете заметить, что и в инициализации, и в часте шага инструкции вычисляются в последовательном порядке. Также раздел инициализации может иметь любое число определений одного типа.
Операторы приведения
Слово приведение используется в смысле “приведение к шаблону”. Java будет автоматически менять тип данных на другой при присвоении. Например, если вы присваиваете целочисленное значение переменной с плавающей точкой, компилятор автоматически конвертирует int в float. Приведение позволяет вам сделать такой тип преобразования более точным или форсировать его, когда оно не может выполнится нормально.
Для выполнения приведения поместите нужный тип данный (включая все модификаторы) внутри круглых скобок с левой стороны от любого значения. Вот пример:
void casts() { int i = 200; long l = (long)i; long l2 = (long)200; }
Как вы можете видеть, возможно выполнить приведение для числового значения так же как и для переменной. Однако, вобоих показанных здесь приведениях излишне, так как компилятор автоматически переводит значение int в long, когда это необходимо. Но вам позволено применять излишнее преобразование, чтобы сделать какое-то место или сделать ваш код более понятным. В остальных ситуациях приведение может быть очень важно просто для того, чтобы код скомпилировался.
В C и C++ приведение может стать причиной головной боли. В Java приведение безопасно, за исключением тех случаев, когда вы выполняете так называемое сужающее преобразование (то есть, когда вы переходите от одного типа данных, который содержит больше информации, к другому, который не содержит так много), вы рискуете потерять информацию. Здесь компилятор заставляет вас выполнить преобразование и при этом говорит: “выполнение это может быть опасным — если вы хотите от меня, чтобы я все равно сделал это, вы должны выполнить явное преобразование”. При расширенном преобразовании в явном приведении нет необходимости, потому что новый тип будет содержать больше информации, в отличае от старого типа, так что не будет потерь в информации.
Java позволяет вам выполнить приведение любого примитивного типа к любому другому примитивному типу, за исключением boolean, для которого не допускается любое приведение. Типы классов не позволяют приведение. Для преобразования одного к другому должны быть специальные методы. (String - особый случай и вы позже найдете в этой книге, что объекты могут приводится в пределах семейства типов; Oak может быть преобразован к Tree и наоборот, но не к постороннему типу, такому как Rock.)
Операторы сдвига
Операторы сдвига также манипулируют битами. Они могут использоваться исключительно с примитивными, целыми типами. Оператор сдвига влево (<<) производит действия над операндом, расположенным слева от оператора, сдвигая влева на число бит, указанное после оператора (вставляя нули в биты младшего порядка). Оператор сдвига вправо с учетом знака (>>) производит действия над операндом, расположенным слева от оператора, сдвигаяя вправо на число бит, указанное после оператора. Сдвиг в право с учетом знака >> использует знаковое дополнение: если значение положительное в биты старшего порядка вставляются нули; если значение отрицательное, в старшие биты вставляются единицы. Java также добавлен беззнаковый сдвиг вправо >>>, который использует дополнение нулями: независимо от знака, в старшие биты вставляются нули. Этот оператор не существует ни в C, ни в C++.
Если вы сдвигаете char, byte или short, это переводится в int перед сдвигом, а результат будет типа int. Будут использоваться только пять младших бит с правой стороны. Это предохранит вас от сдвига на болешее число бит, чем есть в int. Если вы работаете с long, в результате вы получите long. Будут использоваться только шесть младших бит с правой стороны, так что вы не сможете сдвинуть на большее число бит, чем есть в long.
Сдвиг может быть скомбинирован со знаком равенства (<<= или >>= или >>>=). lvalue заменяется на lvalue, сдвинутое на правое rvalue. Однако, есть проблема с беззнаковым правым сдвигом, скомбинированным с присваиванием. Если вы используете byte или short, вы не получаете корректный результат. Вместо этого происходит преобразование к int и правый сдвиг, но затем происходит усечение, так как результат снова присваивается к той же переменной, так что в этих случаях вы получите -1. Приведенный пример демонстрирует это:
//: c03:URShift.java
// Проверка беззнакового правого сдвига.
public class URShift { public static void main(String[] args) { int i = -1; i >>>= 10; System.out.println(i); long l = -1; l >>>= 10; System.out.println(l); short s = -1; s >>>= 10; System.out.println(s); byte b = -1; b >>>= 10; System.out.println(b); b = -1; System.out.println(b>>>10); } } ///:~
В последней строке результирующее значение не присваивается назат переменной b, а сразу выводится на печать, поэтому мы видим правильное поведение.
Здесь мы видим пример, который демонстрирует использование всех операторов, использующих биты:
//: c03:BitManipulation.java
// Использование битовых операторов.
import java.util.*;
public class BitManipulation { public static void main(String[] args) { Random rand = new Random(); int i = rand.nextInt(); int j = rand.nextInt(); pBinInt("-1", -1); pBinInt("+1", +1); int maxpos = 2147483647; pBinInt("maxpos", maxpos); int maxneg = -2147483648; pBinInt("maxneg", maxneg); pBinInt("i", i); pBinInt("~i", ~i); pBinInt("-i", -i); pBinInt("j", j); pBinInt("i & j", i & j); pBinInt("i | j", i | j); pBinInt("i ^ j", i ^ j); pBinInt("i << 5", i << 5); pBinInt("i >> 5", i >> 5); pBinInt("(~i) >> 5", (~i) >> 5); pBinInt("i >>> 5", i >>> 5); pBinInt("(~i) >>> 5", (~i) >>> 5);
long l = rand.nextLong(); long m = rand.nextLong(); pBinLong("-1L", -1L); pBinLong("+1L", +1L); long ll = 9223372036854775807L; pBinLong("maxpos", ll); long lln = -9223372036854775808L; pBinLong("maxneg", lln); pBinLong("l", l); pBinLong("~l", ~l); pBinLong("-l", -l); pBinLong("m", m); pBinLong("l & m", l & m); pBinLong("l | m", l | m); pBinLong("l ^ m", l ^ m); pBinLong("l << 5", l << 5); pBinLong("l >> 5", l >> 5); pBinLong("(~l) >> 5", (~l) >> 5); pBinLong("l >>> 5", l >>> 5); pBinLong("(~l) >>> 5", (~l) >>> 5); } static void pBinInt(String s, int i) { System.out.println( s + ", int: " + i + ", binary: "); System.out.print(" "); for(int j = 31; j >=0; j--) if(((1 << j) & i) != 0) System.out.print("1"); else
System.out.print("0"); System.out.println(); } static void pBinLong(String s, long l) { System.out.println( s + ", long: " + l + ", binary: "); System.out.print(" "); for(int i = 63; i >=0; i--) if(((1L << i) & l) != 0) System.out.print("1"); else
System.out.print("0"); System.out.println(); } } ///:~
Два метода в конце: pBinInt( ) и pBinLong( ) tполучают int или long соответственно, и печатают их в бинарном формате вместе с описательной строкой. Вы можете пока проигнорировать их реализацию.
Вы обратите внимание на использование System.out.print( ) вместо System.out.println( ). Метод print( ) не вызывает появление новой строки, так что это позволяет вам выводить строку по кусочкам.
Заодно здесь демонстрируется эффект для всех битовых операций для int и long, этот пример также показывает минимальное, максимальное, +1 и -1 значения для int и long, так что вы можете увидить как они выглядят. Обратите внимание на битовое представление знака: 0 означает положительное число, 1 означает отрицательное. Вывод для части int выглядит так:
-1, int: -1, binary: 11111111111111111111111111111111 +1, int: 1, binary: 00000000000000000000000000000001 maxpos, int: 2147483647, binary: 01111111111111111111111111111111 maxneg, int: -2147483648, binary: 10000000000000000000000000000000 i, int: 59081716, binary: 00000011100001011000001111110100 ~i, int: -59081717, binary: 11111100011110100111110000001011 -i, int: -59081716, binary: 11111100011110100111110000001100 j, int: 198850956, binary: 00001011110110100011100110001100 i & j, int: 58720644, binary: 00000011100000000000000110000100 i | j, int: 199212028, binary: 00001011110111111011101111111100 i ^ j, int: 140491384, binary: 00001000010111111011101001111000 i << 5, int: 1890614912, binary: 01110000101100000111111010000000 i >> 5, int: 1846303, binary: 00000000000111000010110000011111 (~i) >> 5, int: -1846304, binary: 11111111111000111101001111100000 i >>> 5, int: 1846303, binary: 00000000000111000010110000011111 (~i) >>> 5, int: 132371424, binary: 00000111111000111101001111100000
Битовое представление чисел называется двоичным представлением.
Операторы сравнения
Операторы сравнения генерируют булевый результат. Они вычисляют отношения между значениями и операндами. Выражение отношения производит true, если выражение истинное, а false, если выражение ложное. Выражения отношения, это: меньше чем (<), больше чем (>), меньше либо равно, чем (<=), больше либо равно, чем (>=), равно (==) и не равно (!=). Равно и неравно работает со всеми встроенными типами данных, но другие сравнения работают только с типом boolean.
Операторы унарного минуса и плюса
Унарный минус (-) и унарный плюс (+) это такие же операции, как и бинарный минус и плюс. компилятор вычисляет какое использование имеется в виду по спообу записи выражения. Например, выражение
x = -a;
имеет очевидный смысл. Компилятор способен вычислить:
x = a * -b;
но читатель может быть сконфужен, так что лучше сказать:
x = a * (-b);
Унарный минус производит отрицательное значение. Унарный плюс производится симметрично унарному минусу, хотя не производит никакого эффекта.
Описатель развертывания
Описатель развертываия является XML файлом, который содержит информацию относительно вашего EJB. Исползование XML позволяет установщику легко менять атрибуты вашего EJB. Конфигурационные атрибуты, определеные в описателе развертывания, включают:
Имена Домашнего и Удаленного интерфейса, которые требуются для вашего EJB Имя для публикации в JNDI для вашего Домашнего интерфейса EJB Транзакционные атрибуты для каждого метода вашего EJB Контрольный Список Доступа для авторизации
Ошибка?
Если вы взглянете на раздел 5, вы увидите, что данные записываются перед текстом. Дело в том, что эта проблема была представлена в Java 1.1 (и сохранилась в Java 2), я был уверен, что это ошибка. Когда я сообщил об этом людям, занимающимся ошибками в JavaSoft, они сказали мне, что это, Проблема показана в следующем коде:
//: c11:IOProblem.java
// Java 1.1 и высшая проблема ввода/вывода.
import java.io.*;
public class IOProblem { // Исключение выбрасывается на консоль:
public static void main(String[] args) throws IOException { DataOutputStream out = new DataOutputStream( new BufferedOutputStream( new FileOutputStream("Data.txt"))); out.writeDouble(3.14159); out.writeBytes("That was the value of pi\n"); out.writeBytes("This is pi/2:\n"); out.writeDouble(3.14159/2); out.close();
DataInputStream in = new DataInputStream( new BufferedInputStream( new FileInputStream("Data.txt"))); BufferedReader inbr = new BufferedReader( new InputStreamReader(in)); // Double, записанное ПЕРЕД текстом
// считывается правильно:
System.out.println(in.readDouble()); // Читаем строки текста:
System.out.println(inbr.readLine()); System.out.println(inbr.readLine()); // Попытка читать double после строки
// производит исключение конца файла:
System.out.println(in.readDouble()); } } ///:~
Кажется что все, что вы пишите после вызова writeBytes( ) не возвращаемо. Ответ, очевидно, тот же, что и в случае старой шутки водителя: “Доктор, мне больно, когда я делаю это!” “Так не делайте этого!”
Ошибки
Не важно какие ухищрения использует автор для поиска ошибок, некоторые все равно проскакивают и вылезают при повторном прочтении. В начале каждой главы в HTML формате (а также на CD-ROM или на сайте www.BruceEckel.com) находиться специальная форма для отправки сообщения об ошибках. Если вы что-то обнаружите и решите что это есть ошибка используйте данную форму для отправки сообщения, а также ваше мнение об ее исправлении. По необходимости, включайте файл с оригинальным исходным текстом и комментируйте любые предложенные изменения. Я буду вам благодарен за помощь.
(То же самое касается русского перевода книги. - Прим. перев.)
Основные исключения
Исключительное состояние - это проблема, которая мешает последовательное исполнение метода или ограниченного участка, в котором вы находитесь. Важно различать исключительные состояния и обычные проблемы, в которых вы имеете достаточно информации в текущем контексте, чтобы как-то справиться с трудностью. В исключительном состоянии вы не можете продолжать обработку, потому что вы не имете необходимой информации, чтобы разобраться с проблемой в текущем контексте. Все, что вы можете сделать - это выйти из текущего контекста и отослать эту проблему к высшему контексту. Это то, что случается, когда вы выбрасываете исключение.
Простой пример - деление. Если вы делите на ноль, стоит проверить, чтобы убедиться, что вы пройдете вперед и выполните деление. Но что это значит, что делитель равен нулю? Может быть, вы знаете, в контексте проблемы вы пробуете решить это в определенном методе, как поступать с делителем, равным нулю. Но если это не ожидаемое значение, вы не можете это определить внутри и раньше должны выбросить исключение, чем продолжать свой путь.
Когда вы выбрасываете исключение, случается несколько вещей. Во-первых, создается объект исключения тем же способом, что и любой Java объект: в куче, с помощью new. Затем текущий путь выполнения (который вы не можете продолжать) останавливается, и ссылка на объект исключения выталкивается из текущего контекста. В этот момент вступает механизм обработки исключений и начинает искать подходящее место для продолжения выполнения программы. Это подходящее место - обработчик исключения, чья работа - извлечь проблему, чтобы программа могла попробовать другой способ, либо просто продолжиться.
Простым примером выбрасывания исключения является рассмотрение ссылки на объект, называемой t. Возможно, что вы можете передать ссылку, которая не была инициализирована, так что вы можете пожелать проверить ее перед вызовом метода, использующего эту ссылку на объект. Вы можете послать информацию об ошибке в больший контекст с помощью создания объекта, представляющего вашу информацию и “выбросить” его из вашего контекста. Это называется выбрасыванием исключения. Это выглядит так:
if(t == null) throw new NullPointerException();
Здесь выбрасывается исключение, которое позволяет вам — в текущем контексте — отказаться от ответственности, думая о будущем решении. Оно магически обработается где-то в другом месте. Где именно будет скоро показано.
Основы апплета
Одна из целей разработки Java - это создание апплетов, которые являются маленькими программами, запускаемыми внутри Web броузера. Поскольку они должны быть безопасны, апплеты ограничены в своих возможностях. Однако апплеты являются мощным инструментом для поддержки программирования на стороне клиента - главной способности для Web.
Основы сервлетов
Архитектура API сервлетов состоит в том, что классический сервис обеспечивается методом service( ), через который сервлету посылаются все клиентские запросы, и методами жизненного цикла init( ) и destroy( ), которые вызываются только при загрузке и выгрузке сервлета (это исключительные стуации).
public interface Servlet { public void init(ServletConfig config) throws ServletException; public ServletConfig getServletConfig(); public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException; public String getServletInfo(); public void destroy(); }
Изюминка getServletConfig( ) состоит в том, что он возвращает объект ServletConfig, который содержит параметры инициализации и запуска для этого сервлета. getServletInfo( ) возвращает строку, содержащую информацию о сервлете, такую, как имя автора, версию и авторское право.
Класс GenericServlet является реализацией оболочки этого интерфейса и обычно не используется. Класс HttpServlet является расширением GenericServlet и предназначен специально для обработки протокола HTTP — HttpServlet один из тех классов, которые вы будете использовать чаще всего.
Наиболее удобным инструментом сервлетного API является внешние объекты, которые идут вместе с классом HttpServlet для его поддержки. Если вы взглянете на метод service( ) из интерфейса Servlet, вы увидите, что он имеет два параметра: ServletRequest и ServletResponse. У класса HttpServlet эти два объекта расширяются на HTTP: HttpServletRequest и HttpServletResponse. Вот простой пример, который показывает использование HttpServletResponse:
//: c15:servlets:ServletsRule.java
import javax.servlet.*; import javax.servlet.http.*; import java.io.*;
public class ServletsRule extends HttpServlet { int i = 0; // Servlet "persistence"
public void service(HttpServletRequest req, HttpServletResponse res) throws IOException { res.setContentType("text/html"); PrintWriter out = res.getWriter(); out.print("<HEAD><TITLE>"); out.print("A server-side strategy"); out.print("</TITLE></HEAD><BODY>"); out.print("<h1>Servlets Rule! " + i++); out.print("</h1></BODY>"); out.close(); } } ///:~
ServletsRule настолько прост, насколько может быть прост сервлет. Сервлет инициализиуется только однажды путем вызова своего метода init( ) при загрузке сервлета после того, как сначала загрузиться контейнер сервлетов. Когда клиент делает запрос к URL, соответствующий представленному сервлету, контейнер сервлетов перехватывает этот запрос и делает вызов метода service( ), затем устанавливает объекты HttpServletRequest и HttpServletResponse.
Главная забота метода service( ) состоит во взаимодействии с HTTP запросом, посланным клиентом, и построение HTTP ответа, основываясь на аттрибутах, содержащихся в запросе. ServletsRule манипулирует объектом ответа не зависимот от того, что мог послать клиент.
После установки типа содержимого ответа (что всегда должно быть сделано перед созданием Writer или OutputStream), метод getWriter( ) объекта ответа производит объект PrintWriter, который используется для написания символьного ответа (другой подход: getOutputStream( ) производит OutputStream, используемы для бинарного ответа, который походит только для специальных решений).
Оставшаяся часть программы просто посылает клиенту HTML (тут предполагается, что вы понимаете HTML, так что эта часть не объясняется) в виде последователности String. Однако, обратите внимание на включение “счетчика посещений”, представленного переменной i. Здесь выполняется автоматическая конвертация в String в инструкции print( ).
Когда вы запустите программу, вы увидите, что значение i сохраняется между запросами к сервлету. Это важное свойство сервлетов: так как только один сервлет определенного класса загружается в контейнер, и он никогда не выгружается (только в случае, если контейнер сервлетов завершает работу, что обычно случается, если вы перезагружаете машину), любые поля сервлета этого класса загружаются в контейнер и становятся устойчивыми объектами! Это означает, что вы можете без особого труда сохранять значения между запросами к сервлету, а при использовании CGI вы должны записывать значения на диск, чтобы сохранить его, что требует некоторое количество искусственности, а в результате получаем ен кросс-платформенное решение.
Конечно иногда Web сервер и, соответственно, контейнер сервлетов должен быть перегружен как часть процесса поддержки или из-за проблем с питанием. Для предотвращения потери любой пристутствующей информации автоматически вызываются методы сервлета init( ) и destroy( ) при любой загрузке или выгрузке сервлета, что дает вам возможность сохранить данные при выключении и восстановить их после перезагрузки. Контейнер сервлетов вызывает метод destroy( ), как только он прекращает работу, так что вы всегда имеете удобный случай сохранить важные данные.
Есть еще одна проблема при использовании HttpServlet. Этот класс имеет методы doGet( ) и doPost( ), которые отличаются от метода “GET” CGI получения от клиента, и метода CGI “POST”. GET и POST отличаются только в деталях способами, которыми они передают данные, что лично я предпочитаю игнорировать. Однако чаще всего публикуется информация, из того, что видел я, которая одобряет создание отдельных методов doGet( ) и doPost( ) вместо единого общего метода service( ), который обрабатывает оба случая. Это предпочтение кажется достаточно общим, но я никогда не видел объяснения, которое заставило бы меня поверить, что это не просто интертность мышления CGI программистов, которые привыкли обращать внимание, используется ли GET или POST. Так что в духе “упрощения всего насколько это возможно”[75], я буду использовать метод service( ) в этих примерах, и пусть он сам заботиться о GET'ах и POST'ах. Однако держите в уме, что я что-то упустил, что, возможно, является хорошей причиной в польху использования doGet( ) и doPost( ).
В любое время, когда форма передается сервлету, HttpServletRequest предварительно загружает все данные формы, хранящиеся в виде пар ключ-значение. Если вы знаете имена полей, вы можете просто использовать их напрямую с помощью метода getParameter( ) для получения значения. Вы также можете получить Enumeration (старая форма Iterator) на имена полей, как показано в следующем примере. Этот пример также демонстрирует как один сервлет может быть использован для генерации страницы, которая содержит форму, и для ответа на страницу (более удобное решение будет показано позже, при рассмотрении JSP). Если Enumeration пустое, значит полей нет. Это значит, что никакой формы не было передано. В этом случае содается форма, а кнопка посылки повторно вызывает этот же сервлет. Если же поля существуют, они показываются.
//: c15:servlets:EchoForm.java
// Дамп пар имен-значений из любой формы HTML
import javax.servlet.*; import javax.servlet.http.*; import java.io.*; import java.util.*;
public class EchoForm extends HttpServlet { public void service(HttpServletRequest req, HttpServletResponse res) throws IOException { res.setContentType("text/html"); PrintWriter out = res.getWriter(); Enumeration flds = req.getParameterNames(); if(!flds.hasMoreElements()) { // Форма не передавалась - создание формы:
out.print("<html>"); out.print("<form method=\"POST\"" + " action=\"EchoForm\">"); for(int i = 0; i < 10; i++) out.print("<b>Field" + i + "</b> " + "<input type=\"text\""+ " size=\"20\" name=\"Field" + i + "\" value=\"Value" + i + "\"><br>"); out.print("<INPUT TYPE=submit name=submit"+ " Value=\"Submit\"></form></html>"); } else { out.print("<h1>Your form contained:</h1>"); while(flds.hasMoreElements()) { String field= (String)flds.nextElement(); String value= req.getParameter(field); out.print(field + " = " + value+ "<br>"); } } out.close(); } } ///:~
Здесь виден один из недостатков, заключающийся в том, что Java не кажеться предназначенной для обработки строк в уме — форматирование возвращаемой страницы достаточно неприятно из-за переводов строки, выделение знаков кавычки и символов “+”, необходимых для построения объекта String. С большими HTML страницами становится неразумно вносить этот код прямо в Java. Одо из решений - держать страницу в виде отдельного текстового файла, затем открывать и обрабатывать его на Web сервере. Если вы выполняете любые подстановки в содержимом страницы, это не лучший подход, так как Java плохо выполняет обработку строк. В этом случае для вас, вероятно, лучше будет использовать более подходящее решение (Python может быть вашим выбором. Есть версии, которые встраиваются в Java, называемые JPython) для генерации ответной страницы.
Особенности строк
Теперь вы видите что класс String - не совсем обычный класс Java. У String много особенностей, не последней из них является тот факт что String является одним из встроенных и фундаментальных классов Java. Кроме того, заключенные в кавычки символы автоматически преобразуются компилятором в String, и с ним допускается применение специальных перегруженных операторов + и +=. В этом приложении вы рассмотрели и другие специальные особенности: тщательной реализации неизменности используя компаньон StringBuffer, а также дополнительные особенности компиляции.
Особый случай: примитивные типы
Есть группа типов, имеющих особое обращение; вы можете думать о них, как о “примитивных” типах, которые вы достаточно часто используете в вашем программировании. Причина специального использования в том, что создание объектов с помощью new —особенно маленьких, простые переменных — не очень существенно, поскольку new помещает объекты в кучу. Для этих типов Java возвращается к подходу, принятому в C и C++. Так что, вместо создания переменной с использованием new, “автоматические” переменные создаются не по ссылке. Переменная хранит значение, и оно помещается в стек, так как это более эффективно.
Java определяет размер каждого примитивного типа. Размеры не меняются при переходе от одной архитектуры машины к другой, как это сделано во многих языках. Этот размер инвариантен - это причина того, что программирование на Java так переносимо.
| boolean | — | — | — | Boolean |
| char | 16-бит | Unicode 0 | Unicode 216- 1 | Character |
| byte | 8-bit | -128 | +127 | Byte |
| short | 16-bit | -215 | +215 — 1 | Short |
| int | 32-bit | -231 | +231 — 1 | Integer |
| long | 64-bit | -263 | +263—1 | Long |
| float | 32-bit | IEEE754 | IEEE754 | Float |
| double | 64-bit | IEEE754 | IEEE754 | Double |
| void | — | — | — | Void |
Все числовые типы знаковые, так что не ищите беззнаковые типы.
Размер boolean типов точно не определено; только указано, что они способны принимать литерные значения true или false.
Примитивные типы данных также имеют классы “оболочки” для них. Это означает, что если вы хотите создать не примитивный объект в куче для представления примитивного типа, вы используете ассоциированную оболочку. Например:
char c = 'x'; Character C = new Character(c);
Или вы также моги использовать:
Character C = new Character('x');
Обоснования для этого действия будет дано в последующих главах.
Особый случай RuntimeException
Первый пример в этой главе был:
if(t == null) throw new NullPointerException();
Это может быть немного пугающим: думать, что вы должны проверять на null каждую ссылку, передаваемую в метод (так как вы не можете знать, что при вызове была передана правильная ссылка). К счастью вам не нужно это, поскольку Java выполняет стандартную проверку во время выполнения за вас и, если вы вызываете метод для null ссылки, Java автоматически выбросит NullPointerException. Так что приведенную выше часть кода всегда излишняя.
Есть целая группа типов исключений, которые относятся к такой категории. Они всегда выбрасываются Java автоматически и вам не нужно включать их в вашу спецификацию исключений. Что достаточно удобно, что они все сгруппированы вместе и относятся к одному базовому классу, называемому RuntimeException, который является великолепным примером наследования: он основывает род типов, которые имеют одинаковые характеристики и одинаковы в поведении. Также вам никогда не нужно писать спецификацию исключения, объявляя, что метод может выбросить RuntimeException, так как это просто предполагается. Так как они указывают на ошибки, вы, фактически, никогда не выбрасываете RuntimeException — это делается автоматически. Если вы заставляете ваш код выполнять проверку на RuntimeExceptions, он может стать грязным. Хотя вы обычно не ловите RuntimeExceptions, в ваших собственных пакетах вы можете по выбору выбрасывать некоторые из RuntimeException.
Что случится, если вы не выбросите это исключение? Так как компилятор не заставляет включать спецификацию исключений для этого случая, достаточно правдоподобно, что RuntimeException могут принизывать насквозь ваш метод main( ) и не ловится. Чтобы увидеть, что случится в этом случае, попробуйте следующий пример:
//: c10:NeverCaught.java
// Игнорирование RuntimeExceptions.
public class NeverCaught { static void f() { throw new RuntimeException("From f()"); } static void g() { f(); } public static void main(String[] args) { g(); } } ///:~
Вы уже видели, что RuntimeException ( или любое, унаследованное от него) - это особый случай, так как компилятор не требует спецификации этих типов.
Вот что получится при выводе:
Exception in thread "main"
java.lang.RuntimeException: From f() at NeverCaught.f(NeverCaught.java:9) at NeverCaught.g(NeverCaught.java:12) at NeverCaught.main(NeverCaught.java:15)
Так что получим такой ответ: Если получаем RuntimeException, все пути ведут к выходу из main( ) без поимки, для такого исключения вызывается printStackTrace( ), и происходит выход из программы.
Не упускайте из виду, что вы можете только игнорировать RuntimeException в вашем коде, так как вся другая обработка внимательно ограничивается компилятором. Причина в том, что RuntimeException представляют ошибки программы:
Ошибка, которую вы не можете поймать (получение null ссылки, передаваемой в ваш метод клиентским программистом, например).
Ошибки, которые вы, как программист, должны проверять в вашем коде (такие как ArrayIndexOutOfBoundsException, где вы должны обращать внимание на размер массива).
Вы можете увидеть какая огромная выгода от этих исключений, так как они помогают процессу отладки.
Интересно заметить, что вы не можете классифицировать обработку исключений Java, как инструмент с одним предназначением. Да, он предназначен для обработки этих надоедливых ошибок времени выполнения, которые будут случаться, потому что ограничения накладываются вне кода управления, но он также важен для определенных типов ошибок программирования, которые компилятор не может отследить.
Отделение бизнес логики от логики пользовательского интерфейса
В общем случае вы захотите разработать ваши классы так, чтобы каждый из них выполнял только одно. Это особенно важно, когда код интерфейса пользователя является связанным, так как легче связать “то, что вы делаете” с тем, “как вы это отображаете”. Такой род связывания мешает повторному использованию кода. Поэтому желательно разделить вашу “бизнес логику” и GUI. Этим способом вы сможете не только с легкостью повторно использовать бизнес логику, но и с легкостью повторно использовать GUI.
Другим подходом является многосвязные системы, где “бизнес объекты” располагаются полностью отдельной машине. Такое централизованное расположение бизнес правил позволяет изменениям происходить мгновенно для всех новых транзакций, и поэтому оно является лучшим способом построения системы. Однако такие бизнес объекты могут использоваться во многих различный приложениях и, поэтому, не должны привязываться к определенному режиму отображения. Они просто должны выполнять бизнес операции и ничего более.
Следующий пример показывает, как легко разделяется бизнес логика и GUI код:
//: c13:Separation.java
// Разделение GUI логики и бизнес объектов.
// <applet code=Separation
// width=250 height=150> </applet>
import javax.swing.*; import java.awt.*; import javax.swing.event.*; import java.awt.event.*; import java.applet.*; import com.bruceeckel.swing.*;
class BusinessLogic { private int modifier; public BusinessLogic(int mod) { modifier = mod; } public void setModifier(int mod) { modifier = mod; } public int getModifier() { return modifier; } // Какие-то бизнес операции:
public int calculation1(int arg) { return arg * modifier; } public int calculation2(int arg) { return arg + modifier; } }
public class Separation extends JApplet { JTextField t = new JTextField(15), mod = new JTextField(15); BusinessLogic bl = new BusinessLogic(2); JButton calc1 = new JButton("Calculation 1"), calc2 = new JButton("Calculation 2"); static int getValue(JTextField tf) { try { return Integer.parseInt(tf.getText()); } catch(NumberFormatException e) { return 0; } } class Calc1L implements ActionListener { public void actionPerformed(ActionEvent e) { t.setText(Integer.toString( bl.calculation1(getValue(t)))); } } class Calc2L implements ActionListener { public void actionPerformed(ActionEvent e) { t.setText(Integer.toString( bl.calculation2(getValue(t)))); } } // Если вы хотите, чтобы что-то происходило при
// изменении JTextField, добавьте слушатель:
class ModL implements DocumentListener { public void changedUpdate(DocumentEvent e) {} public void insertUpdate(DocumentEvent e) { bl.setModifier(getValue(mod)); } public void removeUpdate(DocumentEvent e) { bl.setModifier(getValue(mod)); } } public void init() { Container cp = getContentPane(); cp.setLayout(new FlowLayout()); cp.add(t); calc1.addActionListener(new Calc1L()); calc2.addActionListener(new Calc2L()); JPanel p1 = new JPanel(); p1.add(calc1); p1.add(calc2); cp.add(p1); mod.getDocument(). addDocumentListener(new ModL()); JPanel p2 = new JPanel(); p2.add(new JLabel("Modifier:")); p2.add(mod); cp.add(p2); } public static void main(String[] args) { Console.run(new Separation(), 250, 100); } } ///:~
Вы можете видеть, что BusinessLogic является четко очерченным классом, который выполняет свои операции даже не подозревая, что может быть GUI окружение. Он просто делает свою работу.
Separation следит за всеми деталями UI, и общается с BusinessLogic только через публичный интерфейс. Все операции собираются вокруг обмена информацией между интерфейсом пользователя и объектом BusinessLogic. Таким образом, Separation, в итоге, просто делает свою работу. Так как Separation знает только то, что он общается с объектом BusinessLogic (то есть, они не сильно связаны), он может общаться с другими типами объектов без особых затруднений.
Думая в терминах разделения UI от бизнес логики, можно облегчить жизнь, когда вы адаптируете унаследованный код для работы с Java.
Отношения ЯВЛЯЕТСЯ против ПОХОЖ НА
Здесь приведена некоторая дискуссия, которая может случиться по поводу наследования: Должно ли наследование только перегружать функции базового класса (и не добавлять новые функции-члены, которых нет в базовом классе)? Это означает, что наследуемый тип точно того же типа, что и базовый класс, так как он имеет точно такой же интерфейс. В результате вы можете заменить объект наследуемого класса на объект базового класса. Это может означать чистую замену и это часто называется принципиальной заменой. Это идеальный способ использования наследования. Мы часто ссылаемся на взаимосвязи между базовым классом и наследуемыми классами. В этом случае мы имеем взаимоотношение ЯВЛЯЕТСЯ, так как вы можете сказать, что “окружность является формой”. Проверьте наследование, чтобы определить, можете ли вы сказать о классе, что имеется взаимоотношение ЯВЛЯЕТСЯ.
Иногда, когда вы должны добавить к наследуемому типу новый элемент интерфейса, так что расширение интерфейса создает новый тип. Новый тип все равно может быть представлен базовым типом, но представление не точное, поскольку новые функции не доступны у базового типа. Это может быть описано как взаимоотношение ПОХОЖ НА[6]. Новый тип имеет интерфейс старого типа, а так же содержит другие функции, так что вы не можете реально сказать, что он такой же. Например, рассмотрим кондиционеры. Предполагая, что ваш дом имеет все регуляторы для охлаждения, так что вам нужен интерфейс, который позволит вам регулировать охлаждение. Вообразите, что кондиционер упал и разбился и вы заменили его на такой же, но с нагревающим вентилятором, который может производить и холод и тепло. Такой аппарат ПОХОЖ НА кондиционер, но он может делать больше. Поскольку система управления в вашем доме предназначена только для регулировки охлаждения, это ограничивает коммуникацию с охлаждающей частью нового объекта. Интерфейс нового объекта был расширен, а существующая система не знает ничего, за исключением оригинального интерфейса.
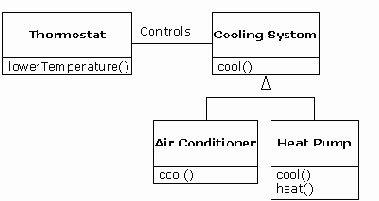
Конечно, как вы видите, становиться достаточно ясно, что базовый класс “система охлаждения” не достаточно общий, и должен быть переименован в “систему управления температурой”, чтобы он также мог включать нагреватели — после чего замена принципиально сможет работать. Однако приведенная выше диаграмма является примером того, что случается при разработке и в реальном мире.
Как вы видите, замену принципиальную легче почувствовать в этом подходе (чистая замена) - это только способ делать вещи, а фактически это лучшие, если вы делаете работу не этим способом. Но вы найдете, что существуют задачи, когда совершенно ясно, что вы должны добавить новые функции к интерфейсу наследуемого класса. При просмотре оба класса должны быть достаточно понятны.
Отображение рабочего пространства
Хотя тот код, который, который делает программу запускаемой и как апплет, и как приложение, предоставляет ценные результаты, если его использовать везде, он сбивает с толку и впустую тратит бумагу. Вместо этого приведенное ниже отображение рабочего пространства будет использоваться для примеров Swing в оставшейся части книги:
//: com:bruceeckel:swing:Console.java
// Инструмент для запуска демонстрации Swing
// из консоли и доя апплета, и для JFrames.
package com.bruceeckel.swing; import javax.swing.*; import java.awt.event.*;
public class Console { // Создание строки заголовка из имени класса:
public static String title(Object o) { String t = o.getClass().toString(); // Удаление слова "class":
if(t.indexOf("class") != -1) t = t.substring(6); return t; } public static void setupClosing(JFrame frame) { // Решение JDK 1.2 - это
// анонимный внутренний класс:
frame.addWindowListener(new WindowAdapter() { public void windowClosing(WindowEvent e) { System.exit(0); } }); // улучшенное решение в JDK 1.3:
// frame.setDefaultCloseOperation(
// EXIT_ON_CLOSE);
} public static void run(JFrame frame, int width, int height) { setupClosing(frame); frame.setSize(width, height); frame.setVisible(true); } public static void run(JApplet applet, int width, int height) { JFrame frame = new JFrame(title(applet)); setupClosing(frame); frame.getContentPane().add(applet); frame.setSize(width, height); applet.init(); applet.start(); frame.setVisible(true); } public static void run(JPanel panel, int width, int height) { JFrame frame = new JFrame(title(panel)); setupClosing(frame); frame.getContentPane().add(panel); frame.setSize(width, height); frame.setVisible(true); } } ///:~
Этот инструмент вы можете использовать сами, так как он помещен в библиотеке com.bruceeckel.swing. Класс Console полностью состоит из статических методов. Первый используется для получения имени класса (используя RTTI) из любого объекта и удаления слова “class”, которое обычно присоединяется спереди методом getClass( ). Здесь используется метод indexOf( ) из String для определения присутствия слова “class” и substring( ) для получения новой строки без приставки “class” или заключающих пробелов. Это имя используется для метки окна, которая отображается в методах run( ).
setupClosing( ) используется для упрятывания кода, являющегося причиной выхода из программы при закрытии JFrame. По умолчанию при этом ничего не делается, так что если вы не вызовите setupClosing( ) или не напишите аналогичный код для своего JFrame, приложение не закроется. Причина упрятывания этого кода, а не помещения его прямо в последовательность метода run( ), частично в том, что это позволяет вам использовать этот метод сам по себе, когда вы захотите сделать что-то более сложное по сравнению с тем, что обеспечивает run( ). Однако это изолирует фактор изменения: Java 2 имеет два пути для закрытия некоторых видов окон. В JDK 1.2 решение состоит в создании нового класса WindowAdapter и реализации windowClosing( ), как показано выше (значение этого будет полностью объяснено позже в этой главе). Однако во время создания JDK 1.3 разработчики библиотеки заметили, что вам обычно нужно закрывать окна в любом случае, если вы создаете не апплет, и поэтому они добавили setDefaultCloseOperation( ) в JFrame и JDialog. С точки зрения написания кода, новый метод более приятный в использовании, но эта книга была написана в то время, когда еще не было реализации JDK 1.3. для Linux и других платформ, поэтому в интересах совместимости версий изменения были изолированы в методе setupClosing( ).
Методы run( ) перегружены для работы с JApplet, JPanel и JFrame. Обратите внимание, что только для JApplet вызывается init( ) и start( ).
Теперь любой апплет может быть запущен из консоли путем создания main( ), содержащей строку, подобную этой:
Console.run(new MyClass(), 500, 300);
в которой последние два аргумента показывают ширину и высоту. Здесь приведена Applet1c.java измененная для использования Console:
//: c13:Applet1d.java
// Console запускает апплет из командной строки.
// <applet code=Applet1d width=100 height=50>
// </applet>
import javax.swing.*; import java.awt.*; import com.bruceeckel.swing.*;
public class Applet1d extends JApplet { public void init() { getContentPane().add(new JLabel("Applet!")); } public static void main(String[] args) { Console.run(new Applet1d(), 100, 50); } } ///:~
Это позволяет уменьшить количество повторяющегося кода, одновременно обеспечивая великолепную гибкость в запуске примеров.
Отслеживание множественных событий
Чтобы убедится, что эти события действительно возбуждаются, и в качестве эксперимента, стоит создать апплет, который отслеживает дополнительное поведение JButton (а не только следит за его нажатием). Этот пример также показывает вам, как наследовать вашу собственный объект кнопки, потому что она будет использоваться как мишень для всех интересующих нас событий. Чтобы сделать это, вы просто наследуете от JButton.[69]
Класс MyButton - это внутренний класс TrackEvent, так что MyButton может получить доступ в родительское окно и управлять его текстовыми полями, что необходимо для записи информации статуса в поля родителя. Конечно это ограниченная ситуация, так как myButton может использоваться только в соединении с TrackEvent. Код такого рода иногда называется “глубоко связанный”:
//: c13:TrackEvent.java
// Показ возникающих событий.
// <applet code=TrackEvent
// width=700 height=500></applet>
import javax.swing.*; import java.awt.*; import java.awt.event.*; import java.util.*; import com.bruceeckel.swing.*;
public class TrackEvent extends JApplet { HashMap h = new HashMap(); String[] event = { "focusGained", "focusLost", "keyPressed", "keyReleased", "keyTyped", "mouseClicked", "mouseEntered", "mouseExited","mousePressed", "mouseReleased", "mouseDragged", "mouseMoved"
}; MyButton b1 = new MyButton(Color.blue, "test1"), b2 = new MyButton(Color.red, "test2"); class MyButton extends JButton { void report(String field, String msg) { ((JTextField)h.get(field)).setText(msg); } FocusListener fl = new FocusListener() { public void focusGained(FocusEvent e) { report("focusGained", e.paramString()); } public void focusLost(FocusEvent e) { report("focusLost", e.paramString()); } }; KeyListener kl = new KeyListener() { public void keyPressed(KeyEvent e) { report("keyPressed", e.paramString()); } public void keyReleased(KeyEvent e) { report("keyReleased", e.paramString()); } public void keyTyped(KeyEvent e) { report("keyTyped", e.paramString()); } }; MouseListener ml = new MouseListener() { public void mouseClicked(MouseEvent e) { report("mouseClicked", e.paramString()); } public void mouseEntered(MouseEvent e) { report("mouseEntered", e.paramString()); } public void mouseExited(MouseEvent e) { report("mouseExited", e.paramString()); } public void mousePressed(MouseEvent e) { report("mousePressed", e.paramString()); } public void mouseReleased(MouseEvent e) { report("mouseReleased", e.paramString()); } }; MouseMotionListener mml = new MouseMotionListener() { public void mouseDragged(MouseEvent e) { report("mouseDragged", e.paramString()); } public void mouseMoved(MouseEvent e) { report("mouseMoved", e.paramString()); } }; public MyButton(Color color, String label) { super(label); setBackground(color); addFocusListener(fl); addKeyListener(kl); addMouseListener(ml); addMouseMotionListener(mml); } } public void init() { Container c = getContentPane(); c.setLayout(new GridLayout(event.length+1,2)); for(int i = 0; i < event.length; i++) { JTextField t = new JTextField(); t.setEditable(false); c.add(new JLabel(event[i], JLabel.RIGHT)); c.add(t); h.put(event[i], t); } c.add(b1); c.add(b2); } public static void main(String[] args) { Console.run(new TrackEvent(), 700, 500); } } ///:~
В конструкторе MyButton устанавливается цвет вызовом SetBackground( ). Все слушатели устанавливаются простым вызовом метода.
Класс TrackEvent содержит HashMap для хранения строк, представляющих тип события, и поля JTextField, которые содержат информацию о событиях. Конечно, это должно создаваться статически перед помещением в HashMap, но я думаю, что вы согласитесь, что это гораздо легче использовать и изменять. Обычно, если вам нужно добавить или удалить новый тип события в TrackEvent, вы просто добавляете или удаляете строку в массиве event — все остальное происходит автоматически.
Когда вызывается report( ) он дает имя события и строку параметров события. Далее используется HashMap h из внешнего класса для поиска реального JTextField, ассоциированного с этим именем события, и происходит помещение строки параметров в это поле.
С этот примером забавно поиграть, так как вы на самом деле видите то, что происходит с событиями в вашей программе.
Отзывчивый пользовательский интерфейс
В качестве отправной точки рассмотрим программу выполняющую какие-либо интенсивные вычисления из-за чего совершенно не реагирует на ввод пользователя. Нижеприведенный код, являющийся апплетом/приложением одновременно, просто выводит показания счетчика:
//: c14:Counter1.java
// A non-responsive user interface.
// <applet code=Counter1 width=300 height=100>
// </applet>
import javax.swing.*; import java.awt.event.*; import java.awt.*; import com.bruceeckel.swing.*;
public class Counter1 extends JApplet { private int count = 0; private JButton start = new JButton("Start"), onOff = new JButton("Toggle"); private JTextField t = new JTextField(10); private boolean runFlag = true; public void init() { Container cp = getContentPane(); cp.setLayout(new FlowLayout()); cp.add(t); start.addActionListener(new StartL()); cp.add(start); onOff.addActionListener(new OnOffL()); cp.add(onOff); } public void go() { while (true) { try { Thread.sleep(100); } catch(InterruptedException e) { System.err.println("Interrupted"); } if (runFlag) t.setText(Integer.toString(count++)); } } class StartL implements ActionListener { public void actionPerformed(ActionEvent e) { go(); } } class OnOffL implements ActionListener { public void actionPerformed(ActionEvent e) { runFlag = !runFlag; } } public static void main(String[] args) { Console.run(new Counter1(), 300, 100); } } ///:~
Swing и апплеты должны быть вам уже знакомы по главе 13. Метод go() это то место программы где выполнение зацикливается: текущее значение count помещается в JTextField t, после чего count увеличивает значение.
Часть бесконечного цикла внутри go() вызов sleep(). Sleep() должен ассоциироваться с объектом Thread, и это должно показывать, что каждое приложение имеет несколько связанных с ним процессов. (Действительно, Java базируется на процессах и всегда есть один, запущенный с вашим приложением.) Таким образом, в зависимости от того где вы точно используете процессы, вы можете вызвать текущий процесс используемый программой при помощи Thread и статического sleep() метода.
Имейте ввиду, что sleep() может генерировать исключения InterruptedException, хотя генерация подобного исключения является неправильным путем выхода из процесса и должна быть отвергнут. (Повторю еще раз, исключения существуют только для особых ситуаций, а не для управления выполнения программы.) Вызов спящего потока включен для поддержки будущих расширений языка.
Когда нажата кнопка Strart выполняется go(). Глянув на код go() вы можете наивно предположить (как и я), что множественность процессов будет соблюдаться, так как процесс засыпает. Таким образом, когда данный метод заснул, CPU должен заниматься опросом других кнопок. На самом деле проблема в том, что go() никогда не завершиться, поскольку цикл бесконечный, а значит actionPerformed( ) не завершиться. Поскольку вы находитесь в actionPerformed( ) после первого нажатия, программа не сможет обработать другие события. (Для выхода необходимо каким-то образом завершить приложение, наиболее простой способ нажать Ctrl+C в консольном окне, если запущено в консоли. Если запущено в броузере, то придется убить броузер.)
Основная проблема заключается в том, что go() должна продолжить выполнение и в то же время завершить выполнение так, чтобы вызов actionPerformed( ) мог завершиться и пользовательский интерфейс мог снова среагировать на действия пользователя. Но обычный метод, похожий на go(), не может продолжить выполнение и вернуть управление основной программе одновременно. Это звучит как неразрешимая проблема, как будто CPU должен находиться сразу в двух местах, но это точно иллюзия создаваемая процессами.
Модель процессов (и ее программирование, поддерживаемое Java) удобное средство программирования для облегчения запуска нескольких операций в одно и то же время в одной программе. С процессами CPU обходит их всех и выделяет каждому квант времени. Каждый процесс считает, что выполняется на CPU единолично, на самом деле время процессора поделено между всеми процессами. Исключением является случай, когда программа запущено на многопроцессорной машине. Но одно важное обстоятельство насчет процессов заключается в том, что вам не нужно думать об этих уровнях, так что коду вашей программы не обязательно знать выполняется он на единственном CPU или на нескольких. Таким образом, процессы дают возможность создавать легко масштабируемые приложения.
Процессы немного уменьшают эффективность вычислений, но улучшенные сетевые возможности, т.к. сбалансированность ресурсов и удобство пользователя зачастую более важны. Конечно, если вы имеете более одного процессора, то операционная система позволяет выделить каждый CPU для нескольких процессов и вся программа будет выполняться значительно быстрее. Многозадачность и множественность процессов будут более предпочтительными для использования многопроцессорных систем.
Ожидание и уведомление
Из первых двух примеров очень важно понять, как sleep(), так и suspend() не освобождают блокировку во время своего вызова. Вы должны знать об этом когда работает с блокировками. С другой стороны, методwait( ) освобождает блокировку во время своего вызова, что означает, что другие, synchronized методы в объекте процесса могут быть вызваны во время wait(). В следующих двух классах видно, что метод run() полностью synchronized в обоих классах, однако Peeker все также имеет полный доступ к synchronized методам во время wait(). Это происходит из-за того, что wait() освобождает блокировку объекта после приостановки метода из которого он вызван.
Также видно, что существуют две формы wait(). Первая принимает аргумент в миллисекундах, что имеет то же значение как и в sleep(): остановку на это время. Различие в том, что в wait() блокировка объекта освобождается и вы можете выйти из wait() с помощью notify() так же как и после истечения времени.
Вторая форма без передачи параметров означает, что wait() будет выполняться до тех пор пока не будет вызвано notify() и не остановится автоматически по истечению времени.
Один, довольно уникальный аспект wait( ) и notify( ) в том, что оба метода являются частью базового класса Object, а не частью Thread, как sleep( ), suspend( ) и resume( ). Хотя это и выглядит немного странно в начале - сделать то, что должно относиться исключительно к процессу доступным для базового класса - это необходимо, так как он управляет блокировками, которые являются частью каждого объекта. В результате можно поместить wait() в любой syncronized метод, в зависимости от того, будет ли какой-либо процесс выполнять именно данный класс. Фактически, единственное применение для wait() быть вызванным из synchronized метода или блокировки. Если вызвать wait() или notify() в необъявленном как synchronuzed методе, то программа будет прекрасно компилироваться, но когда вы ее запустите, то получите IllegalMonitorStateException с каким-то не сразу понятным сообщением "current thread not owner" (текущий процесс не владелец). Запомните, что sleep(), suspend() и resume() могут быть вызваны из не-syncronized методов, поскольку они не управляют блокировкой.
Вы можете вызвать wait() или notify() только для вашей собственной блокировки. Еще раз, вы сможете скомпилировать код, который пытается использовать неверную блокировку, но это приведет вас к тому самому IllegalMonitorStateException сообщению как и прежде. Также ни чего не получиться с чужой блокировкой, но можно попросить другой объект выполнить операцию с его собственной блокировкой. Таким образом одна из попыток заключается в создании syncronized метода, который вызывает notify() для своего собственного объекта. Однако в Notifier видим вызов notify() из syncronized блока:
synchronized(wn2) { wn2.notify(); }
где wn2 объекта типа WaitNotify2. Этот, не являющийся частью WaitNotifier2, метод, имеет блокировку на объект wn2 и с этого момента он совершенно спокойно может вызвать notify() для wn2 и не получить IllegalMonitorStateException.
///:Continuing
/////////// Blocking via wait() ///////////
class WaitNotify1 extends Blockable { public WaitNotify1(Container c) { super(c); } public synchronized void run() { while(true) { i++; update(); try { wait(1000); } catch(InterruptedException e) { System.err.println("Interrupted"); } } } }
class WaitNotify2 extends Blockable { public WaitNotify2(Container c) { super(c); new Notifier(this); } public synchronized void run() { while(true) { i++; update(); try { wait(); } catch(InterruptedException e) { System.err.println("Interrupted"); } } } }
class Notifier extends Thread { private WaitNotify2 wn2; public Notifier(WaitNotify2 wn2) { this.wn2 = wn2; start(); } public void run() { while(true) { try { sleep(2000); } catch(InterruptedException e) { System.err.println("Interrupted"); } synchronized(wn2) { wn2.notify(); } } } } ///:Continued
wait( ) обычно используется тогда, когда вы пришли к той точке программы, в которой вы ожидаете каких-либо других состояний, изменяемых под воздействием из вне вашего процесса, и не хотите пустого ожидания внутри вашего процесса. То есть wait() позволяет вам перевести процесс в сонное состояние в ожидании изменения мира и его сможет разбудить только notify() или notifyAll(), после чего он проснется и посмотрит что изменилось. Таким образом обеспечивается способ синхронизации между процессами.
Package: модуль библиотеки
Пакет это что Вы используете, когда пишете ключевое слово import для подключения целой библиотеки, такой как
import java.util.*;
Это включает в программу библиотеку утилит, которая является частью стандартной поставки Java. Например, класс ArrayList находится в java.util, и Вы можете также указать полное имя java.util.ArrayList (которое Вы можете использовать без выражения import), либо просто написать ArrayList (при использовании import).
Если Вы хотите включить единичный класс, Вы можете указать этот класс в выражении import
import java.util.ArrayList;
После этого, Вы можете использовать ArrayList без ограничений. Однако, никакие другие классы из пакета java.util не будут доступны.
Использование импорта обусловлено необходимостью управления “пространством имен.” Имена всех членов класса изолированы друг от друга. Метод f( ) внутри класса A не будет конфликтовать с методом f( ) которой имеет такую же сигнатуру (список аргументов) в классе B. А что же насчет имен классов? Представьте, что Вы создаете класс stack и устанавливаете на машине, на которой уже есть класс stack, написанный кем-то другим? С Java в интернете такое вполне может произойти, и Вы об этом можете не узнать, т.к. классы часто загружаются автоматически в процессе запуска Java-приложения.
Из-за появления возможных конфликтов важно иметь полный контроль над пространством имен в Java, а также, иметь возможность создавать абсолютно уникальные имена.
До сих пор, большинство примеров в этой книге существовали в единичном файле и проектировались для локального использования, без упоминания о пакетах. (В этом случае класс располагался в “пакете по умолчанию.”) Ради упрощения такой подход будет использоваться, где это возможно, в оставшейся части книги. Однако, если Вы планируете создавать библиотеки и программы которые будут дружественными для других программ на Java на той же машине, Вам нужно будет подумать о предотвращении конфликтов с именами классов.
Когда Вы создаете файл исходного текста в Java, он обычно называется модулем компиляции (иногда модулем трансляции). Каждый модуль компиляции должен иметь расширение .java, и внутри него может быть расположен публичный класс, который должен иметь имя такое же, как имя файла (учитывая регистры, но без расширения .java). В каждом модуле компиляции может быть только один публичный класс, в противном случае, компилятор будет недоволен. Остальные классы в этом модуле компиляции, если они есть, скрыты от мира за пределами этого пакета, т.к. они не публичные, и представляют классы “поддержки” для главного публичного класса.
Когда Вы компилируете файл .java Вы получаете выходной файл с точно таким же именем и расширением .class для каждого класса в файле .java. Таким образом, из нескольких .java файлов Вы получаете несколько .class файлов. Если Вы работали с компилирующими языками, то Вы, возможно, получали от компилятора выходные файлы (обычно это “obj” файлы), которые, затем, объединялись вместе с другими файлами такого же типа с помощью линкера (для создания исполняемого файла) либо генератора библиотеки (для создания библиотеки). Но Java работает не так. Работающая программа это набор .class файлов, которые могут быть собраны в пакет и запакованы в JAR файл (с помощью Java архиватора jar). А интерпретатор Java способен находить, загружать и интерпретировать эти файлы[32].
Библиотека это также набор .class файлов. Каждый файл содержит один публичный класс (Вас не заставляют иметь публичный класс, но это типичная ситуация), так что для каждого файла есть один компонент. Если Вы хотите чтобы все эти компоненты хранились вместе (из различных .java и .class файлов), Вы используете ключевое слово package.
Когда Вы пишите:
package mypackage;
в начале файла (если Вы используете выражение package, перед ним могут быть только комментарии), этим Вы указываете, что этот модуль компиляции является частью библиотеки с названием mypackage. Или, другими словами, Вы говорите, что публичный класс внутри этого модуля компиляции скрыт под именем mypackage, и если кто-то захочет использовать этот класс он должен либо указать имя пакета, либо использовать ключевое слово import вместе с mypackage (используя варианты, показанные ранее). Заметьте, что в Java есть соглашение для имен пакетов, это - использование символов только нижнего регистра, даже для внутренних слов.
Например, предположим, что имя файла - MyClass.java. Это значит, что может быть только один публичный класс в этом файле, и имя этого класса должно быть - MyClass (включая регистры):
package mypackage; public class MyClass { // . . .
Теперь, если кто-то хочет использовать класс MyClass или любой другой публичный класс из пакета mypackage, ему нужно будет использовать ключевое слово import чтобы сделать доступными имена из пакета mypackage. Существует также альтернатива - использование имен с префиксами:
mypackage.MyClass m = new mypackage.MyClass();
А ключевое слово import может это упростить:
import mypackage.*; // . . .
MyClass m = new MyClass();
Это стоит запомнить, т.к. с помощью ключевых слов package и import, Вы можете, как разработчик библиотеки, разделять глобальное пространство имен, и, в результате, исключить конфликт имен, не зависимо от того, сколько людей подключаются к интернет и начинают писать классы на Java.
Пакет по умолчанию
Вы, возможно, удивитесь, когда узнаете, что следующий код компилируется, хотя Вам может показаться, что он нарушает правила языка Java:
//: c05:Cake.java
// Получает дочтуп к классу // в другом модуле комиляции
class Cake { public static void main(String[] args) { Pie x = new Pie(); x.f(); } } ///:~
Другой файл в том же каталоге содержит следующее:
//: c05:Pie.java
// Другой класс.
class Pie { void f() { System.out.println("Pie.f()"); } } ///:~
Вначале Вы можете посчитать эти файлы абсолютно чужими, и все же Cake может создать объект Pie и вызвать его метод f( )! (Конечно, Вам нужно, чтобы CLASSPATH содержал ".", иначе файлы не будут компилироваться.) Вы можете подумать, что и класс Pie и его метод f( ) являются дружественными и недоступны объекту Cake. То, что они дружественны - это верно! А причина, по которой они доступны в Cake.java в том, что они находятся в одном и том же каталоге и не имеют конкретного имени пакета. Java считает эти файлы частью “пакета по умолчанию” для этого каталога, и поэтому, дружественными всем остальным файлам в этом каталоге.
Пакетное предостережение
Необходимо запомнить, что когда Вы создаете пакет, Вы косвенно задаете структуру каталогов при задании имени пакета. Пакет должен находиться в каталоге, определенном в имени пакета, причем этот каталог должен быть доступен по переменной CLASSPATH. Экспериментирование с ключевым словом package может быть бесполезным вначале, поскольку пока Вы не будете придерживаться правила: имя пакета определяет путь к нему, Вы будете получать множество непонятных run-time сообщений, сообщающих о невозможности найти какой-нибудь класс, даже если он находится в том же самом каталоге. Если Вы получите подобное сообщение, попробуйте закомментировать выражение package, и, если все заработает, то Вы знаете, в чем проблема.
Панели скроллирования
Большую часть времени вам будет нужно позволять JScrollPane делать его работу, но вы можете также управлять, какая полоса прокрутки доступна — вертикальная, горизонтальная, обе или ни одной:
//: c13:JScrollPanes.java
//Управление полосами прокрутки в JScrollPane.
// <applet code=JScrollPanes width=300 height=725>
// </applet>
import javax.swing.*; import java.awt.*; import java.awt.event.*; import javax.swing.border.*; import com.bruceeckel.swing.*;
public class JScrollPanes extends JApplet { JButton b1 = new JButton("Text Area 1"), b2 = new JButton("Text Area 2"), b3 = new JButton("Replace Text"), b4 = new JButton("Insert Text"); JTextArea t1 = new JTextArea("t1", 1, 20), t2 = new JTextArea("t2", 4, 20), t3 = new JTextArea("t3", 1, 20), t4 = new JTextArea("t4", 10, 10), t5 = new JTextArea("t5", 4, 20), t6 = new JTextArea("t6", 10, 10); JScrollPane sp3 = new JScrollPane(t3, JScrollPane.VERTICAL_SCROLLBAR_NEVER, JScrollPane.HORIZONTAL_SCROLLBAR_NEVER), sp4 = new JScrollPane(t4, JScrollPane.VERTICAL_SCROLLBAR_ALWAYS, JScrollPane.HORIZONTAL_SCROLLBAR_NEVER), sp5 = new JScrollPane(t5, JScrollPane.VERTICAL_SCROLLBAR_NEVER, JScrollPane.HORIZONTAL_SCROLLBAR_ALWAYS), sp6 = new JScrollPane(t6, JScrollPane.VERTICAL_SCROLLBAR_ALWAYS, JScrollPane.HORIZONTAL_SCROLLBAR_ALWAYS); class B1L implements ActionListener { public void actionPerformed(ActionEvent e) { t5.append(t1.getText() + "\n"); } } class B2L implements ActionListener { public void actionPerformed(ActionEvent e) { t2.setText("Inserted by Button 2"); t2.append(": " + t1.getText()); t5.append(t2.getText() + "\n"); } } class B3L implements ActionListener { public void actionPerformed(ActionEvent e) { String s = " Replacement "; t2.replaceRange(s, 3, 3 + s.length()); } } class B4L implements ActionListener { public void actionPerformed(ActionEvent e) { t2.insert(" Inserted ", 10); } } public void init() { Container cp = getContentPane(); cp.setLayout(new FlowLayout()); // Создание бордюра для компонент:
Border brd = BorderFactory.createMatteBorder( 1, 1, 1, 1, Color.black); t1.setBorder(brd); t2.setBorder(brd); sp3.setBorder(brd); sp4.setBorder(brd); sp5.setBorder(brd); sp6.setBorder(brd); // Инициализация слушателей и добавление компонент:
b1.addActionListener(new B1L()); cp.add(b1); cp.add(t1); b2.addActionListener(new B2L()); cp.add(b2); cp.add(t2); b3.addActionListener(new B3L()); cp.add(b3); b4.addActionListener(new B4L()); cp.add(b4); cp.add(sp3); cp.add(sp4); cp.add(sp5); cp.add(sp6); } public static void main(String[] args) { Console.run(new JScrollPanes(), 300, 725); } } ///:~
При использовании различных аргументов, в конструкторе JScrollPane происходит управление доступностью полос прокрутки. Этот пример также немного красивее при использовании бордюров.
@Param
Эта форма:
@param parameter-name description
в которой parameter-name - это идентификатор в списке параметров, а description - текст, который может продолжаться на последующих строках. Описание считается законченным, когда обнаруживается новый ярлык документации. Вы можете иметь любое число таких ярлыков, предположительно, по одному для каждого параметра.
Параметризированные типы
Этот вид проблемы не обособлен — существуют многочисленные случаи, когда вам необходимо создавать новые типы, основываясь на других типах, и в которых полезно иметь определенную информацию во время компиляции. Это концепция параметризированного типа. В С++ это напрямую поддерживается языком с помощью шаблонов. Было бы хорошо, чтобы в будущих версиях Java поддерживала некоторые варианты параметризированных типов; текущий лидер автоматически создает классы, аналогичные MouseList.
Парное программирование
Парное программирование восстает против крепкого индивидуализма, с которым мы были познакомлены с самого начала через школу (где достигаем цели или терпим нашу собственную неудачу и работа с нашим окружением рассматривается как “обман”) и средства информации, особенно Голливудские фильмы, в которых герой обычно сражается против бессмысленного сходства [17]. Программисты тоже рассматривают образцы индивидуальности — “кодировщики - ковбои”, как любит говорить Larry Constantine. Теперь ЭП, которое само сражается против последовательного мышления, говорит, что код должен писаться двумя людьми за каждой рабочей станцией. И это должно быть выполнено для группы рабочих станций без барьеров, которые так любят люди, обслуживающие проект. Фактически, Beck говорит, что первая задача преобразования к ЭП - это прибыть с отвертками и выворачивать и демонтировать все, что мешает. [18] (Это будет требовать менеджера, который будет отводить ярость отдела обслуживания.)
Значение парного программирования в том, что один человек реально выполняет кодирования, пока другой думает об этом. Тот кто думает, держит в мозгу большую картину — не только картину решаемой проблемы, но и руководящие моменты ЭП. Если два человека работают, то менее вероятно, что один из них уйдет, говоря: “Я не хочу сначала писать тест”, например. И если кодировщик застопорится, они могут поменяться местами. Если они оба застопорятся, их раздумья могут решены кем-то еще из рабочего пространства, кто может посодействовать. Работа в паре держит ход работы в колее. Вероятно, более важно при создании программы больше вечеринок и веселья.
Я начал использовать парное программирование в период развития в некоторых моих семинарах и это значительно увеличивало опыт каждого.
Передача и использование Java объектов
В предыдущем примере мы передавали String в собственный метод. Можно также передавать ваши собственные Java объекты в собственные методы. Внутри вашего собственного метода вы имеете доступ к полям и методам полученного объекта.
Для передачи объектов используйте обычный Java синтаксис когда описываете собственные методы. В следующем примере MyJavaClass имеет одно public поле и один public метод. В классе UseObject объявлен собственный метод, который принимает объекты класса MyJavaClass. Для отображения того, что собственный метод использует эти аргументы передадим поле public, вызовем собственный метод и, затем, распечатаем это поле.
//: appendixb:UseObjects.java
class MyJavaClass { public int aValue; public void divByTwo() { aValue /= 2; } }
public class UseObjects { private native void changeObject(MyJavaClass obj); static { System.loadLibrary("UseObjImpl"); // Linux hack, если в вашей среде не установлен
// путь к библиотеке:
// System.load(
//"/home/bruce/tij2/appendixb/UseObjImpl.so");
} public static void main(String[] args) { UseObjects app = new UseObjects(); MyJavaClass anObj = new MyJavaClass(); anObj.aValue = 2; app.changeObject(anObj); System.out.println("Java: " + anObj.aValue); } } ///:~
После компиляции кода и использования javah можно реализовать собственные методы. В примере ниже, как только поле и ID метода получены они доступны чере JNI функции.
//: appendixb:UseObjImpl.cpp
//# Проверено с VC++ & BC++. Включенный путь
//# должен быть изменен для нахождения JNI заголовков. Смотрите
//# makefile для этой главы (в загруженном исходном коде)
//# для примера.
#include <jni.h> extern "C" JNIEXPORT void JNICALL Java_UseObjects_changeObject( JNIEnv* env, jobject, jobject obj) { jclass cls = env->GetObjectClass(obj); jfieldID fid = env->GetFieldID( cls, "aValue", "I"); jmethodID mid = env->GetMethodID( cls, "divByTwo", "()V"); int value = env->GetIntField(obj, fid); printf("Native: %d\n", value); env->SetIntField(obj, fid, 6); env->CallVoidMethod(obj, mid); value = env->GetIntField(obj, fid); printf("Native: %d\n", value); } ///:~
Игнорируя эквиваелент "this", функция С++ получает jobject, который является собственной частью Java объекта переданного нами из Java кода. Мы просто прочитали значение aValue, напечатали его, изменили, вызвали метод объекта divByTwo() и напечатали значение параметра еще раз.
Для доступа к полю или методу Java первоначально необходимо получить их дескриптор, используя GetFieldID() для полей и GetMethodID() для методов. Данные функции принимают объект класса, строку содержащую название элементов и строку с информацией о классах: тип данных поля или информацию с описанием для метода (подробности описаны в документации по JNI). Данные функции возвращают дескриптор, который потом используется для доступа к элементам.Данный подход может казаться запутанным, но ваши собственные методы не знают о внутренней компоновке Java объектов. Вместо этого, они должны обращаться к полям и методам через индексы, возвращаемые JVM.Это позволяет различным JVM реализовать различные сруктуры внутренних объектов, не влияя на ваши собственные методы.
Если запустить Java программу видно, что объекты передаваемые со стороны Java используют ваши собственные методы. Но что же передается в действительности? Указатель или значение Java? И что делает сборщик мусора при вызове собственных методов?
Сборщик мусора продолжает работать во время вызова собственных методов, но он гарантирует, что ваши объекты не будут собраны во время вызова собственных методов. Для достоверности, вначале создаются локальные ссылки, которые уничтожаются сразу после вызова собственного метода. Поскольку их время жизни включает и сам вызов, вы знаете, что объекты будут доступны в течении времени вызова собственного метода.
Поскольку данные ссылки создаются и потом уничтожаются при каждом вызове функции, вы не можете сделать локальную копию вашего собственного метода в static переменную. Если вам нужна ссылка, которая используется в течении вызова функции вам необходимо определить глобальную ссылку. Глобальная ссылка не создается JVM, но программист может создать глобальную ссылку вызовом специальных функций JVM. После создания глобальной ссылки вы отвечаете за время жизни и самого объекта. Глобальная ссылка (и объект к которому она относиться) должны находиться в памяти до тех пор пока программист явно не освободит память соответствующей JNI функцией. Это аналогично использованию malloc() и free() в С.
Передача параметров "по значению"
Тут необходимо внести ясность в понимание термина "передача параметров по значению" и то как он реализуется в программе. Суть метода заключается в использовании локальных копий параметров, передаваемых вашему методу. Камнем преткновения является различное отношение к передаваемым параметрам. Существуют два наиболее распространенных взгляда на параметры:
В Java все параметры передаются по значению. Передавая методу примитивы, вы получаете локальную копию примитивов, передавая методу ссылку, вы получаете локальную копию ссылки. Итак, все передается по значениям. Разумеется, при таком подходе требуется постоянно помнить о том, что вы работаете лишь с ссылками. Однако Java разработан таким образом, что (в большинстве случаев) позволяет вам забыть о том что вы работаете лишь с ссылками и думать о ссылках как об "объектах", но лишь до тех пор, пока вы не попытаетесь вызвать какой-нибудь метод.
Примитивы в Java передаются по значению, а объекты передаются как ссылки. Это общепринятый взгляд на ссылки. При таком подходе вам не надо думать о параметрах как о ссылках. В таком случае вы можете утверждать: "Я передаю объект". Поскольку при передаче объекта в метод вы не создаете его локальную копию, нельзя сказать что объекты передаются по значению. Возможно в будущем компания Sun предложит какое-нибудь решение этой проблемы. В Java зарезервировано, но пока не использовано ключевое слово byvalue (по значению), но на сегодняшний день нет никакой официальной информации о том, будет ли вообще когда-нибудь использовано это ключевое слово.
Итак, рассмотрев обе точки зрения, я скажу так: "Все это зависит лишь от вашего представления о ссылках." Теперь вернемся к нашей проблеме. В конце концов, это не так важно, гораздо важнее понимание того, что передача ссылок в качестве параметров может привести к неожиданным изменениям внешних объектов.
Перегрузка hashCode( )
Теперь, так как вы понимаете что подразумевается под функцией HashMap, проблема написания hashCode( ) становится более ощутимой.
Прежде всего у вас нет инструмента контроля за созданием реального значения, которое используется для индексирования массива ковшей. Так как он зависит от емкости определенного объекта HashMap, а эта емкость меняется в зависимости от того, насколько полон контейнер и каков коэффициент загрузки. Значение, производимое вашим методом hashCode( ) в будущем будет использоваться для создания индекса ковша (в SimpleHashMap это просто вычисление на основе остатка от деления на размер массива ковшей).
Более важный фактор при создании hashCode( ) это то, что независимо от времени вызова hashCode( ) он производил бы одно и то же значение для определенного объекта при каждом вызове. Если вы работаете с объектом, для которого hashCode( ) произвел одно значение в методе put( ) для HashMap, а другое в методе get( ), вы не будете способны получить объект назад. Так что, если ваш hashCode( ) зависит от непостоянства данных объекта, пользователь должен быть уверен, что при изменении данных будет результативно произведен новый ключ, сгенерированный другим hashCode( ).
Кроме того, вероятно, вы не захотите генерировать hashCode( ), который базируется на уникальной информации объекта, обычно это значение this, которое делает плохой hashCode( ), потому что вы не сможете сгенерировать новый ключ, идентичный использованному в put( ) в качестве исходной пары ключ-значение. Эта проблема случилась в SpringDetector.java, потому что реализация по умолчанию hashCode( ) использует адрес объекта. Поэтому вы захотите использовать информацию, которая идентифицирует объект осмысленным образом.
Один пример найден в классе String. String имеет специальную характеристику, так что если программа имеет несколько объектов String, содержащих идентичную последовательность символов, то эти объекты String ссылаются на одну и ту же память (этот механизм описан в Приложении A). Таким образом, имеет смысл, чтобы hashCode( ), производимый двумя различными экземплярами new String(“hello”) были идентичными. Вы можете проверить это, запустив программу.
//: c09:StringHashCode.java
public class StringHashCode { public static void main(String[] args) { System.out.println("Hello".hashCode()); System.out.println("Hello".hashCode()); } } ///:~
Чтобы это работало, hashCode( ) для String должен базироваться на содержимом String.
Для эффективного hashCode( ) необходим быстрый и осмысленный механизм: то есть, он должен генерировать значение, основываясь на содержимом объекта. Помните, что это значение не обязательно должно быть уникальным — вы должны больше внимания уделить скорости, а не уникальности — но с помощью hashCode( ) и equals( ) идентичность должна быть полностью установлена.
Поскольку hashCode( ) вызывается до того, как будет произведен индекс ковша, диапазон значений не важен; просто должно генерироваться число типа int.
Есть еще один фактор: хороший hashCode( ) должен возвращать хорошо распределенные значения. Если значения группируются, то HashMap или HashSet будут тяжелее загружаться в некоторых областях и не будут так же быстры, как это могло быть с функцией с хорошим распределением.
Вот пример, который следует этим руководящим принципам:
//: c09:CountedString.java
// Создание хорошего hashCode().
import java.util.*;
public class CountedString { private String s; private int id = 0; private static ArrayList created = new ArrayList(); public CountedString(String str) { s = str; created.add(s); Iterator it = created.iterator(); // Id - это полное число экземпляров
// строки, используемой CountedString:
while(it.hasNext()) if(it.next().equals(s)) id++; } public String toString() { return "String: " + s + " id: " + id + " hashCode(): " + hashCode() + "\n"; } public int hashCode() { return s.hashCode() * id; } public boolean equals(Object o) { return (o instanceof CountedString) && s.equals(((CountedString)o).s) && id == ((CountedString)o).id; } public static void main(String[] args) { HashMap m = new HashMap(); CountedString[] cs = new CountedString[10]; for(int i = 0; i < cs.length; i++) { cs[i] = new CountedString("hi"); m.put(cs[i], new Integer(i)); } System.out.println(m); for(int i = 0; i < cs.length; i++) { System.out.print("Looking up " + cs[i]); System.out.println(m.get(cs[i])); } } } ///:~
CountedString включает String и id, который представляет число объектов CountedString, содержащих идентичный String. Подсчет совершается в конструкторе при продвижение по static ArrayList, где хранятся все String.
И hashCode( ), и equals( ) производят результат, базируясь на обоих полях; если бы они базировались только на одном String или на одном id, то были бы дублирующие совпадения для разных значений.
Обратите внимание насколько прост hashCode( ): hashCode( ) объекта String умножается на d. Краткость обычно лучше (и быстрее) для hashCode( ).
В main( ) создается группа объектов CountedString, использующих один и тот же String, чтобы показать, что при дублировании создаются уникальные значения, потому что используется счет id. HashMap отображается так, что вы можете видеть как он хранится внутри (нет видимого порядка), а затем каждый ключ ищется индивидуально, чтобы продемонстрировать, что механизм поиска работает правильно.
Перегрузка методов
Одна из главных особенностей в любом языке программирования - это использование имен. Когда вы создаете объект, вы даете имя области хранения. Метод - это имя действия. При использовании имен для описания вашей системы вы создаете программу, которую людям легче понять и изменить. Это очень похоже на написание прозаического произведения — целью является взаимодействие с вашими читателями.
Вы обращаетесь ко всем объектам и методам по имени. Хороший подбор имен облегчает понимание кода для вас и ваших читателей.
Проблемы возникают, когда происходит перекладывание нюансов концепции с человеческого языка на язык программирования. Часто одни и те же слова выражают несколько различных смыслов — это называется перегрузкой. Это полезно, особенно когда имеете дело с тривиальными отличиями. Вы говорите “стирать (мыть) рубашку”, “мыть машину” и “мыть собаку”. Было бы глупо ограничиваться фразами, типа “рубашкоМойка рубашки”, “машиноМойка машины” и “собакоМойка собаки”, так как слушателю события нет необходимости делать различия при выполнении действия. Большинство человеческих языков являются многословными, так что даже если вы пропустите несколько слов, вы все равно поймете смысл. Мы не нуждаемся в уникальных идентификаторах — мы можем вывести смысл из контекста.
Большинство языков программирования (и в частности C) требуют использования уникальных идентификаторов для каждой функции. Так что вы не можете иметь одной функции с именем print( ) для печати целых чисел, а другой, с названием print( ) для печати чисел с плавающей точкой — каждая функция требует уникального имени.
В Java (и C++) один из факторов вынуждает использовать перегрузку методов: конструктор. Поскольку имя конструктора является предопределенным именем класса, то может быть только одно имя конструктора. Но что, если вы хотите создавать объект более чем одним способом? Например, предположим, вы строите класс, который может инициализировать себя стандартным способом или путем чтения информации из файла. Вам нужно два конструктора, один не принимает аргументов (конструктор по умолчанию, также называемый конструктором без аргументов), а другой принимает в качестве аргумента String, который является именем файла, из которого инициализируется объект. Ода они являются конструкторами, так что они должны иметь одно и то же имя — имя класса. Таким образом, перегрузка методов необходима для получения возможности использования одного и того же имени метода с разными типами аргументов. И хотя перегрузка методов необходима для конструкторов, она является общим соглашением и может использоваться для любого метода.
Вот пример, показывающий оба перегруженных конструктора и перегрузку обычного метода:
//: c04:Overloading.java
// Демонстрация перегрузки конструктора
// и обычного метода.
import java.util.*;
class Tree { int height; Tree() { prt("Planting a seedling"); height = 0; } Tree(int i) { prt("Creating new Tree that is "
+ i + " feet tall"); height = i; } void info() { prt("Tree is " + height + " feet tall"); } void info(String s) { prt(s + ": Tree is "
+ height + " feet tall"); } static void prt(String s) { System.out.println(s); } }
public class Overloading { public static void main(String[] args) { for(int i = 0; i < 5; i++) { Tree t = new Tree(i); t.info(); t.info("overloaded method"); } // Перегруженный конструктор:
new Tree(); } } ///:~
Объект Дерева(Tree) может быть создан либо рассадой, без аргументов, либо получен плановой посадкой в лесном хозяйстве по заданной высоте. Для поддержки этого есть два конструктора, один не принимает аргументов (мы называем конструктор, который не принимает аргументов, конструктором по умолчанию [27]), а другой принимает существующую высоту.
Вы так же можете захотеть вызвать метод info( ) более чем одним способом. Например, с аргументом String, если у вас есть желание напечатать дополнительное сообщение, и без него, если вам нечего сказать. Было бы странным давать два разных имени для того, что имеет одну и ту же концепцию. К счастью, перегрузка методов позволяет вам использовать одно и то же имя в обоих случаях.
Перегрузка по возвращаемому значению
Это обычное удивление: “Почему только имена классов и список аргументов метода? Почему не делать различия между методами, основываясь на их возвращаемом значении?” Например, эти методы имеют одинаковое имя и список аргументов, но легко отличаются друг от друга:
void f() {} int f() {}
Это хорошо работает, когда компилятор может недвусмысленно определить смысл из контекста, как в случае int x = f( ). Однако, вы можете вызвать метод и проигнорировать возвращаемое значение; это часто называется побочным действием вызова метода, так как вы не заботитесь о возвращаемом значении, а просто ждете других эффектов от вызова метода. Таким образом, если вы вызываете функция следующим образом:
f();
как Java может определить какой из методов f( ) должен быть вызван? И как другой человек мог бы прочесть приведенный код? Из-за возникновения проблем такого рода вы не можете использовать тип возвращаемого значения для различения перегруженных методов.
Перегрузка с помощью примитивных типов
Примитивные типы могут автоматически преобразовываться от меньшего типа к большему, и это может вносить путаницу в комбинации с перегрузкой. Следующий пример демонстрирует, что случается, когда примитивные типы используются для перегрузки методов:
//: c04:PrimitiveOverloading.java
// Преобразование примитивных типов и перегрузка.
public class PrimitiveOverloading { // boolean не может конвертироваться автоматически
static void prt(String s) { System.out.println(s); }
void f1(char x) { prt("f1(char)"); } void f1(byte x) { prt("f1(byte)"); } void f1(short x) { prt("f1(short)"); } void f1(int x) { prt("f1(int)"); } void f1(long x) { prt("f1(long)"); } void f1(float x) { prt("f1(float)"); } void f1(double x) { prt("f1(double)"); }
void f2(byte x) { prt("f2(byte)"); } void f2(short x) { prt("f2(short)"); } void f2(int x) { prt("f2(int)"); } void f2(long x) { prt("f2(long)"); } void f2(float x) { prt("f2(float)"); } void f2(double x) { prt("f2(double)"); }
void f3(short x) { prt("f3(short)"); } void f3(int x) { prt("f3(int)"); } void f3(long x) { prt("f3(long)"); } void f3(float x) { prt("f3(float)"); } void f3(double x) { prt("f3(double)"); }
void f4(int x) { prt("f4(int)"); } void f4(long x) { prt("f4(long)"); } void f4(float x) { prt("f4(float)"); } void f4(double x) { prt("f4(double)"); }
void f5(long x) { prt("f5(long)"); } void f5(float x) { prt("f5(float)"); } void f5(double x) { prt("f5(double)"); }
void f6(float x) { prt("f6(float)"); } void f6(double x) { prt("f6(double)"); }
void f7(double x) { prt("f7(double)"); }
void testConstVal() { prt("Testing with 5"); f1(5);f2(5);f3(5);f4(5);f5(5);f6(5);f7(5); } void testChar() { char x = 'x'; prt("char argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } void testByte() { byte x = 0; prt("byte argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } void testShort() { short x = 0; prt("short argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } void testInt() { int x = 0; prt("int argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } void testLong() { long x = 0; prt("long argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } void testFloat() { float x = 0; prt("float argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } void testDouble() { double x = 0; prt("double argument:"); f1(x);f2(x);f3(x);f4(x);f5(x);f6(x);f7(x); } public static void main(String[] args) { PrimitiveOverloading p = new PrimitiveOverloading(); p.testConstVal(); p.testChar(); p.testByte(); p.testShort(); p.testInt(); p.testLong(); p.testFloat(); p.testDouble(); } } ///:~
Если вы посмотрите на результаты работы этой программы, вы увидите, что значение константы 5 трактуется как int, так что, несмотря на то, что есть перегруженный метод, используется тот, который принимает int. Во всех остальных случаях, если вы имеете тип данных, который меньше, чем аргумент метода, тип данный преобразуется. char производит немного отличающийся эффект, так как если точное совпадение с char не будет найдено, он преобразуется в int.
Что произойдет, если ваш аргумент больше, чем аргумент, ожидаемый перегруженным методом? Модифицированная программа дает ответ на этот вопрос:
//: c04:Demotion.java
// Понижение примитивных типов и перегрузка.
public class Demotion { static void prt(String s) { System.out.println(s); }
void f1(char x) { prt("f1(char)"); } void f1(byte x) { prt("f1(byte)"); } void f1(short x) { prt("f1(short)"); } void f1(int x) { prt("f1(int)"); } void f1(long x) { prt("f1(long)"); } void f1(float x) { prt("f1(float)"); } void f1(double x) { prt("f1(double)"); }
void f2(char x) { prt("f2(char)"); } void f2(byte x) { prt("f2(byte)"); } void f2(short x) { prt("f2(short)"); } void f2(int x) { prt("f2(int)"); } void f2(long x) { prt("f2(long)"); } void f2(float x) { prt("f2(float)"); }
void f3(char x) { prt("f3(char)"); } void f3(byte x) { prt("f3(byte)"); } void f3(short x) { prt("f3(short)"); } void f3(int x) { prt("f3(int)"); } void f3(long x) { prt("f3(long)"); }
void f4(char x) { prt("f4(char)"); } void f4(byte x) { prt("f4(byte)"); } void f4(short x) { prt("f4(short)"); } void f4(int x) { prt("f4(int)"); }
void f5(char x) { prt("f5(char)"); } void f5(byte x) { prt("f5(byte)"); } void f5(short x) { prt("f5(short)"); }
void f6(char x) { prt("f6(char)"); } void f6(byte x) { prt("f6(byte)"); }
void f7(char x) { prt("f7(char)"); }
void testDouble() { double x = 0; prt("double argument:"); f1(x);f2((float)x);f3((long)x);f4((int)x); f5((short)x);f6((byte)x);f7((char)x); } public static void main(String[] args) { Demotion p = new Demotion(); p.testDouble(); } } ///:~
Здесь методы принимают сужающие примитивные типы. Если ваш список аргументов широк, вы должны выполнять приведение типа, используя нужное имя типа в круглых скобках. Если вы не сделаете это, компилятор выдаст сообщение об ошибки.
Вы должны быть знать, что это ограничивающее преобразование, которое вы означает, что вы можете потерять информацию во время приведения типа. По этой причине компилятор заставляет вас сделать это — чтобы указать на ограничивающее преобразование.
Перехват любого исключения
Можно создать обработчик, ловящий любой тип исключения. Вы сделаете это, перехватив исключение базового типа Exception (есть другие типы базовых исключений, но Exception - это базовый тип, которому принадлежит фактически вся программная активность):
catch(Exception e) { System.err.println("Caught an exception"); }
Это поймает любое исключение, так что, если вы используете его, вы будете помещать его в конце вашего списка обработчиков для предотвращения перехвата любого обработчика исключения, который мог управлять течением.
Так как класс Exception - это базовый класс для всех исключений, которые важны для программиста, вы не получите достаточно специфической информации об исключении, но вы можете вызвать метод, который пришел из его базового типа Throwable:
String getMessage( )
String getLocalizedMessage( )
Получает подробное сообщение или сообщение, отрегулированное по его месту действия.
String toString( )
Возвращает короткое описание Throwable, включая подробности сообщения, если они есть.
void printStackTrace( )
void printStackTrace(PrintStream)
void printStackTrace(PrintWriter)
Печатает Throwable и трассировку вызовов Throwable. Вызов стека показывает последовательность вызовов методов, которые подвели вас к точке, в которой было выброшено исключение. Первая версия печатает в поток стандартный поток ошибки, второй и третий печатают в выбранный вами поток (в Главе 11, вы поймете, почему есть два типа потоков).
Throwable fillInStackTrace( )
Запись информации в этот Throwable объекте о текущем состоянии кадра стека. Это полезно, когда приложение вновь выбрасывает ошибки или исключение (дальше об этом будет подробнее).
Кроме этого вы имеете некоторые другие метода, наследуемые от базового типа Throwable Object (базовый тип для всего). Один из них, который может быть удобен для исключений, это getClass( ), который возвращает объектное представление класса этого объекта. Вы можете опросить у объекта этого Класса его имя с помощью getName( ) или toString( ). Вы также можете делать более изощренные вещи с объектом Класса, которые не нужны в обработке ошибок. Объект Class будет изучен позже в этой книге.
Вот пример, показывающий использование основных методов Exception:
//: c10:ExceptionMethods.java
// Демонстрация методов Exception.
public class ExceptionMethods { public static void main(String[] args) { try { throw new Exception("Here's my Exception"); } catch(Exception e) { System.err.println("Caught Exception"); System.err.println( "e.getMessage(): " + e.getMessage()); System.err.println( "e.getLocalizedMessage(): " + e.getLocalizedMessage()); System.err.println("e.toString(): " + e); System.err.println("e.printStackTrace():"); e.printStackTrace(System.err); } } } ///:~
Вывод этой программы:
Caught Exception e.getMessage(): Here's my Exception e.getLocalizedMessage(): Here's my Exception e.toString(): java.lang.Exception: Here's my Exception e.printStackTrace(): java.lang.Exception: Here's my Exception at ExceptionMethods.main(ExceptionMethods.java:7) java.lang.Exception: Here's my Exception at ExceptionMethods.main(ExceptionMethods.java:7)
Вы можете заметить, что методы обеспечивают больше информации — каждый из них дополняет предыдущий.
Перенаправление стандартного ввода/вывода
Класс Java System позволяет вам перенаправлять стандартный ввод, вывод и поток вывода ошибок, используя простой вызов статического метода:
setIn(InputStream)
setOut(PrintStream)
setErr(PrintStream)
Перенаправление вывода особенно полезно, если вы неожиданно начнете создание большого объема для вывода на экран, а он будет скроллироваться гораздо быстрее, чем выбудете успевать читать.[59] Перенаправление ввода важно для программ командной строки, в которых вы захотите протестировать определенные последовательности пользовательского ввода несколько раз. Вот пример, показывающий использование этих методов:
//: c11:Redirecting.java
// Демонстрация перенаправления стандартного ввода/вывода.
import java.io.*;
class Redirecting { // Исключение выбрасывается на консоль:
public static void main(String[] args) throws IOException { BufferedInputStream in = new BufferedInputStream( new FileInputStream( "Redirecting.java")); PrintStream out = new PrintStream( new BufferedOutputStream( new FileOutputStream("test.out"))); System.setIn(in); System.setOut(out); System.setErr(out);
BufferedReader br = new BufferedReader( new InputStreamReader(System.in)); String s; while((s = br.readLine()) != null) System.out.println(s); out.close(); // Помните об этом!
} } ///:~
Эта программа соединяет стандартный ввод с файлом и перенаправляет стандартный вывод и стандартные ошибки в другой файл.
Перенаправление ввода/вывода управляет потоками байт, а не потоками символов, то есть, скорее, используются InputStream и OutputStream, чем Reader и Writer.
Переопределение против перегрузки
Давайте теперь взглянем на первый пример этой главы, но под другим углом зрения. В следующей программе интерфейс метода play( ) изменен в процессе переопределения, что означает, что Вы не переопределили этот метод, а вместо этого перегрузили его. Компилятор позволяет вам перегрузить метод, поэтому и не было никаких жалоб с его стороны. Но поведение метода вероятно отличается от того, что бы Вы хотели. Пример:
//: c07:WindError.java
// Случайное изменение интерфейса.
class NoteX { public static final int
MIDDLE_C = 0, C_SHARP = 1, C_FLAT = 2; }
class InstrumentX { public void play(int NoteX) { System.out.println("InstrumentX.play()"); } }
class WindX extends InstrumentX { // Упс! Изменился интерфейс метода:
public void play(NoteX n) { System.out.println("WindX.play(NoteX n)"); } }
public class WindError { public static void tune(InstrumentX i) { // ...
i.play(NoteX.MIDDLE_C); } public static void main(String[] args) { WindX flute = new WindX(); tune(flute); // Не желаемое поведедение!
} } ///:~
Здесь есть еще одна запутывающая сторона применения полиморфизма. В InstrumentX метод play( ) принимает int, который имеет идентификатор NoteX. Так что, даже если NoteX это имя класса, то оно так же может быть использовано и в качестве переменной, без возражений со стороны компилятора. Но в WindX, play( ) берет ссылку NoteX,
которая имеет идентификатор n. (Хотя Вы никогда не сможете осуществить play(NoteX NoteX) без сообщения об ошибке.) Поэтому кажется, что программист собирался переопределить play( ), но немного опечатался. Компилятор же в свою очередь понял, что это перегрузка (overload), а не переопределение (override). Заметьте, что если Вы следуете соглашению об именах в Java, то тогда идентификатор был бы noteX (в нижнем регистре "n"), что отделило бы его от имени класса.
В tune, InstrumentX
i посылает сообщение методу play( ), с одним из членов NoteX (MIDDLE_C) в качестве аргумента. Поскольку NoteX содержит определение int, то это означает, что будет вызвана int
версия перегруженного метода play( ) и в силу того, что он не был переопределен, то будет использована версия базового класса.
Вывод программы:
InstrumentX.play()
Несомненно, это не повлияет на вызов полиморфного метода. Как только Вы поймете что случилось, Вы сможете с легкостью исправить возникшую проблему, но понять причину ошибки тем сложнее, чем больше размер программы.
Первичное написание тестов
Тестирование традиционно относится к последней части проекта, после того, как вы “заставили все работать, просто для того, чтобы убедится”. Это простота имеет более низкий приоритет и те люди, которые специализируются в этом, не имели высокого статуса и часто даже основательно отгораживались, подальше от “реальных программистов”. Испытательные команды относятся к тому типу людей, которые заходят так далеко, что носят черную одежду и с ликованием кудахчут всякий раз, когда что-то ломают (честно говоря, я имел такое чувство, когда ломал компиляторы).
ЭП полностью революционизирует концепцию тестирования, давая равный (или больший) приоритет с кодированием. Фактически, вы пишите тест до того, как напишите код, который будет тестироваться, а тест навсегда остается с кодом. Тест должен выполнятся полностью каждый раз, когда вы делаете итерацию проекта (которая часто случается чаще одного раза в день).
Первичное написание теста имеет два особенно важных эффекта.
Во-первых, оно обеспечивает ясное определение интерфейсов класса. Я часто советовал людям “придумывать совершенный класс для решения определенной проблемы”, как инструмент, когда при попытках разработки системы. Стратегия тестирования ЭП идет дальше — она точно указывает, как класс должен выглядеть для потребителя класса и точно указывает как класс должен себя веси. При этом нет неопределенных терминов. Вы можете писать всю эту прозу или создавать все эти диаграммы, которые хотите, описывающие как класс должен вести себя и как он должен выглядеть, но тесты - это договор, который навязывается компилятору и работающей программе. Трудно выдумать более конкретное описание класса, чем тесты.
Пока создаются тесты, вы навязываете классу конкретные вещи и часто обнаруживаете необходимую функциональность, которая может отсутствовать во время экспериментов с UML диаграммами, CRC карточками, использованием причин и т.п.
Второй важный эффект первичного написания тестов приходит из запуска тестов каждый раз, когда вы делаете сборку программного обеспечения. Это реально дает вам вторую половину тестирования в добавок к проводимому компилятору. Если вы взглянете на эволюцию языков программирования в перспективе, вы увидите, что реальное улучшение технологии вращается вокруг тестирования. Языки сборки проверяли только синтаксис, а C налагает некоторые семантические ограничения, что предотвращает некоторые типы ошибок. ООП языки налагают еще больше семантических ограничений, которые, если вы реально об этом думаете, реально формируются при тестировании. “Правильно ли используется этот тип данных?” и “Правильно ли вызывается эта функция?” - это виды тестов, выполняемые компилятором или системой времени выполнения. Мы видим результат применения этих тестов, встроенных в язык: люди становятся способны писать более сложные системы и заставлять их работать ха меньшее время и с меньшими усилиями. Я разгадал почему это так и теперь я реализую это в тестах: вы делаете что-то неправильно, а сеть безопасности, встроенная в тесты, говорит вам, что появилась проблема и указывает на нее.
Встроенная система тестирования, представленная дизайном языка, может зайти очень далеко. В некоторый момент вы должны вступить и добавить остальные тесты, которые произведут полную свиту (при взаимодействии с компилятором с системе времени выполнения), которые проверяют всю вашу программу. Имея компилятор, заглядывающий вам через плечо, нужны ли вам эти вспомогательные тесты с самого начала? Так почему вы пишите из первыми, а запускаете их автоматически при каждом построении вашей системы. Ваши тесты становятся расширением сети безопасности, обеспечиваемой языком.
Одна из вещей, обнаруженных мной при использовании все более и более мощных языков программирования, была в том, что я одобрял попытки более бесстыдных экспериментов, поскольку я знал, что язык сохранит мне время при охоте за ошибками. Схема тестирования ЭП делает то же для всего вашего проекта. Поскольку вы знаете, что ваши тесты всегда перехватят любую проблему, которую вы создадите (и вы регулярно добавляете новые тесты, когда вы их придумываете), вы можете сделать большие изменения, когда вам это нужно, не заботясь о том, что вы бросите весь проект в полную неразбериху. Это невероятно мощно.
Пять стадий дизайна объектов
Разработка жизни объекта не ограничивается тем временем, когда вы пишите программу. Вместо этого, дизайн объекта продолжается на всей последовательности шагов. Полезно это понимать потому, что вы сразу прекращаете совершенствование; вместо этого вы реализуете, то, что поняли из того, что делает объект и как это должно со временем выглядеть. Это виденье также применимо для разработки различных типов программ; шаблон для обычного типа программы изо всех сил проявляют снова и снова эту проблему (Это отмечено в книге “Thinking in Patterns with Java”, которую можно получить на www.BruceEckel.com). Объекты тоже имеют свои шаблоны, которые проявляется через понимание, использование и повторное использование.
1. Открытие объектов. Этот этап возникает во время начального анализа программы. Объекты могут открываться при рассмотрении внешних факторов и ограничений, дублировании элементов в системе и разбиении на концептуальные кусочки. Некоторые объекты очевидны, если вы уже имеете набор библиотек классов. Общность между подсказкой классов базового класса и наследованием может проявиться сразу или позже, в процессе дизайна.
2. Сборка классов. Как только вы построите объекты, вы почувствуете необходимость в новых членах, которые не проявились при исследовании. Внутренние надобности объектов могут требовать других классов для их поддержки.
3. Конструирование системы. И снова дополнительные требования для объектов могут появиться на этом этапе. Как вы узнали, вы развиваете ваши объекты. Необходимость в коммуникации и взаимодействии с другими объектами системы может изменить требования к вашим классам или потребовать новые. Например, вы можете обнаружить необходимость в посреднике или помощнике класса, таком как связанный список, который содержит малую или главную информацию и просто помогает другим функциям класса.
4. Расширение системы. Как только вы добавите новую особенность системы, вы можете обнаружить, что предыдущий дизайн не поддерживает легкое расширение системы. С этой новой информацией вы можете реструктурировать часть системы, возможно, добавляя новые классы или иерархию классов.
5. Повторное использование объектов. Это действительно напряженный тест для классов. Если кто-то пробует использовать их повторно в новой ситуации, он, вероятно, обнаружит рад недостатков. Как только вы измените класс, чтобы адаптировать к более новой программе, основные принципы класса могут стать яснее, пока вы не получите действительно пригодный для повторного использования тип. Однако не ждите, что большинство объектов дизайна системы получится использовать повторно — совершенно допустимо для большинства ваших объектов быть специфичными для системы. Типы многократного использования имеют тенденцию быть более общими и они должны решать более общие проблемы, чтобы их можно было использовать повторно.
Планы выплат
Конечно, вы не захотите строить здание без множества точно прорисованных планов. Если вы стоите сарай или собачью конуру ваш план не обязательно должен быть тщательно разработан, но вы, вероятно, начнете с определенных набросков, которые помогут вам на вашем пути. Разработка программного обеспечения доходит до крайностей. Долгое время люди не имели достаточно структур при разработке, поэтому большие проекты начинали рушиться. Взаимодействуя, мы покончили с методологиями, которые имели запутывающее количество структур и деталей, необходимых, в первую очередь, для больших проектов. Эти методологии были достаточно страшны для использования — это выглядело, как будто вы тратили все время на написание документации, а не на программирование. (Это случалось довольно часто.) Я надеюсь, что то, что я показал вам здесь, советует средний путь — с подвижную шкалу. Используйте тот доход, который удовлетворяет вашим требованиям (и вашим персоналиям). Не имеет значения, какой минимальный выбор вы сделаете, некоторые виды планов делают большие улучшения вашего проекта, что не мешает вообще отсутствовать планам. Помните, что по большинству оценок, более 50 процентов проектов неудачные (по некоторым оценкам до 70 процентов)!
Следование плану — предпочтительно тому, который проще и короче — и следуя разработанной перед началом кодирования структуре, вы обнаружите, что вещи ложатся вместе легче, чем если бы вы их поделили и начали разрезать. Вы также реализуете великолепное решение ситуации. По моему опыту, подход с элегантными решениями более удовлетворяет различным уровням требований; он больше выглядит как искусство, чем как технология. И элегантность всегда оплачивается; это не просто пустое стремление. Это не только дает вам легкость в построении и отладке программы, но вы также получаете легкость в понимании и поддержке, что лежит в основе объема финансирования.
Почему используется такая странная конструкция?
Возможно такая система показалась вам странной и вы задавались вопросом почему в ней возникла необходимость. Что же стоит за такой реализацией?
Первоначально Java разрабатывался как язык для управления устройствами и не был предназначен для использование в Internet. Клонирование объектов является неотъемлемой функцией таких языков. Поэтому в базовый класс Object был помещен метод clone(), но он был описан как public и таким образом обеспечивалась возможность клонирования любых объектов. На том этапе это казалось наиболее оптимальным вариантом.
Но позже, когда Java превратился в язык, активно применяемый в Internet, все изменилось. Тотальная клонируемость объектов привела к возникновению проблем с безопасностью. Кому хочется чтобы его объекты безопасности свободно клонировались? Поэтому в изначально простую схему были внесены изменения и метод clone() класса Object стал защищенным (protected) и теперь для реализации клонирования вам приходится переопределять его, реализовывать интерфейс Cloneable и иметь дело с обработкой исключительных событиями. Следует отметить, что интерфейс Cloneable реализуется только в том случае, если вы собираетесь вызывать метод clone() класса Object, работа которого начинается с проверки, является ли вызвавший его класс клонируемым. Но, во избежание противоречий, на всякий случай следует реализовать этот интерфейс (тем более, если учесть что он пустой).
Почему Java имеет успех
Причина того, что Java имеет такой успех в том, что целью было решение проблем, стоящих перед разработчиком сегодня. Цели Java увеличивают продуктивность. Эта продуктивность приходит многими путями, но язык разработан так, что помогает вам насколько это возможно, в то время как вам мешают правила или любые требования, которые обычно вносят особенности. Java предназначен для практики; дизайн языка Java основан на предоставлении программисту максимума пользы.
Почему JDBC API выглядит так сложно
Когда вы просмотрите онлайн документацию по JDBC, она может испугать. В частности, интерфейс DatabaseMetaData, который просто огромен, в противоположность большинству интерфейсов, вивденных вами в Java. У него есть такие методы, как dataDefinitionCausesTransactionCommit( ), getMaxColumnNameLength( ), getMaxStatementLength( ), storesMixedCaseQuotedIdentifiers( ), supportsANSI92IntermediateSQL( ), supportsLimitedOuterJoins( ) и так далее. Что вы думаете об этом?
Как упоминалось ранее, базы данных от начала до конца выглядят беспорядочно, в основном поэтому требуются прилажения и инструменты по работе с базами данных. Только недавно появились общие соглашения по языку SQL (и в общем употреблении существует множество других языков работы с базами данных). Но даже при существовании “стандартного” SQL есть так много вариаций этой темы, из-за чего JDBC должен предоставлять такой огромный интерфейс DatabaseMetaData, чтобы ваш код мог обнаруживать совместимость подключенной в настоящее время базы данных с определенным “стандартом” SQL. Короче говоря, вы можете писать на простом, переносимом SQL, но если вы хотите оптимизировать скорость, ваш код черезвычайно расширится, если вы будете исследовать совместимость базы данных со свойствами определенного производителя.
Конечно, Java в этом не виноват. JDBC просто пытается компенсировать расхождения между базами данных разных производителей. Но держите в уме, что ваша жизнь будет проще, если вы сможете писать общие запросы и не будете беспокоиться так много о производительности, или, если вы должны настраивать производительность, знать платформу, для которой вы пишите, чтобы вам не нужно было писать весь исследующий код.
Почему "приведение к базовому типу"?
Причина этого термина кроется в недрах истории, и основана она диаграмме наследования классов имеющую традиционное начертание: сверху страницы корень, растущий вниз. Естественно, Вы можете нарисовать свою собственную диаграмму, каким угодно образом. Диаграмма наследования для Wind.java:
Преобразование (casting) дочернего к базовому происходит при движении вверх (up) по диаграмме наследования, так что получается - upcasting (приведение к базовому типу). Приведение к базовому типу всегда безопасно, поскольку Вы переходите от более общего типа, к более конкретному. Так что дочерний класс является супермножеством базового класса. Он может содержать больше методов, чем базовый класс, но он должен содержать минимум все те методы, что есть в базовом классе. Только одна вещь может случится при приведении к базовому типу, это, что могут потеряться некоторые методы. Вот по этому то компилятор и позволяет осуществлять приведение к базовому типу без каких либо ограничений на приведение типов или специальных замечаний.
Вы так же можете осуществить обратную приведению к базовому типу операцию, называемую приведение базового типа к дочернему (downcasting), но при этом возникает небольшая дилемма, которая разъяснена в главе 12.
Поиск и создание директориев
Класс File - это больше, чем просто представление существующего файла или директория. Вы также можете использовать объект File для создания новой директории или целого пути директорий, если этот путь не существует. Вы можете также взглянуть на характеристики файлов (размер, дату последней модификации, доступ на чтение/запись), посмотреть, представляет ли объект File файл или директорий, и удалить файл. Эта программа показывает некоторые методы, поддерживаемые классом File (смотрите HTML документацию на java.sun.com чтобы увидеть полный набор):
//: c11:MakeDirectories.java
// Демонстрация использования класса File
// для создания и манипулирования файлами.
import java.io.*;
public class MakeDirectories { private final static String usage = "Usage:MakeDirectories path1 ...\n" + "Creates each path\n" + "Usage:MakeDirectories -d path1 ...\n" + "Deletes each path\n" + "Usage:MakeDirectories -r path1 path2\n" + "Renames from path1 to path2\n"; private static void usage() { System.err.println(usage); System.exit(1); } private static void fileData(File f) { System.out.println( "Absolute path: " + f.getAbsolutePath() + "\n Can read: " + f.canRead() + "\n Can write: " + f.canWrite() + "\n getName: " + f.getName() + "\n getParent: " + f.getParent() + "\n getPath: " + f.getPath() + "\n length: " + f.length() + "\n lastModified: " + f.lastModified()); if(f.isFile()) System.out.println("it's a file"); else if(f.isDirectory()) System.out.println("it's a directory"); } public static void main(String[] args) { if(args.length < 1) usage(); if(args[0].equals("-r")) { if(args.length != 3) usage(); File old = new File(args[1]), rname = new File(args[2]); old.renameTo(rname); fileData(old); fileData(rname); return; // Выход из main
} int count = 0; boolean del = false; if(args[0].equals("-d")) { count++; del = true; } for( ; count < args.length; count++) { File f = new File(args[count]); if(f.exists()) { System.out.println(f + " exists"); if(del) { System.out.println("deleting..." + f); f.delete(); } } else { // Не существует
if(!del) { f.mkdirs(); System.out.println("created " + f); } } fileData(f); } } } ///:~
В fileData( ) вы можете видеть различные способы исследования файла для отображения информации о файле или о пути директории.
Первый метод, который вызывается main( ) - это renameTo( ), который позволяет вам переименовать (или переместить) файл по введенному новому путь, представленному аргументом, который является другим объектом типа File. Это так же работает с директориями любой длины.
Если вы поэкспериментируете с приведенной выше программой, вы обнаружите, что вы можете создать путь директорий любой сложности, потому что mkdirs( ) будет делать всю работу за вас.