Адрес IP и класс InetAddress
Назад Вперед
Прежде чем начинать создание сетевых приложений для Internet, вы должны разобраться с адресацией компьютеров в сети с протоколом TCP/IP, на базе которого построена сеть Internet. Здесь мы приведем самые необходимые для этого сведения.
Все компьютеры, подключенные к сети TCP/IP, называются узлами (в оригинальной терминологии узел - это host). Каждый узел имеет в сети свой адрес IP, состоящий из четырех десятичных цифр в диапазоне от 0 до 255, разделенных символом "точка ", например:
193.120.54.200
Фактически адрес IP является 32-разрядным двоичным числом. Упомянутые числа представляют собой отдельные байты адеса IP.
Так как работать с цифрами удобно лишь компьютеру, была придумана система доменных имен. При использовании этой системы адресам IP ставится в соответсвие так называемый доменный адрес, такой как, например, www.sun.com.
В сети Internet имеется распределенная по всему миру база доменных имен, в которой установлено соответствие между доменными именами и адресами IP в виде четырех чисел.
Для работы с адресами IP в библиотеке классов Java имеется класс InetAddress, определение наиболее интересных методов которого приведено ниже:
public static InetAddress getLocalHost(); public static InetAddress getByName(String host); public static InetAddress[] getAllByName(String host); public byte[] getAddress(); public String toString(); public String getHostName(); public boolean equals(Object obj);
Рассмотрим применение этих методов.
Чтобы работать с адресами IP, прежде всего вы должны создать объект класса InetAddress. Эта процедура выполняется не с помощью оператора new, а с применением статических методов getLocalHost, getByName и getAllByName.
Аплет Form
Назад Вперед
На примере аплета Form мы покажем, как приложения Java могут взаимодействовать с расширениями сервера Web, такими как программы CGI или приложения ISAPI.
В окне нашего аплета находится форма, содержащая два однострочных поля редактирования, кнопку и многострочное поле редактирования (рис. 5).

Рис. 5. Окно аплета Form
Эта форма предназначена для добавления записей в базу данных, содержащую электронные почтовые адреса. Заполнив поля имени и адреса E-Mail, пользователь должен нажать кнопку Send. При этом введенная информация будет передана расширению сервера CGI, который запишет ее в базу данных, а затем отправит обратно аплету. Сохраненные записи, полученные от программы CGI, аплет FORM отобразит в многострочном поле редактирования, как это показано на рис. 5.
Аплет ShowChart
Назад Вперед
Попробуем теперь на практике применить технологию передачи файлов из каталога сервера Web в аплет для локальной обработки. Наше следующее приложение с названием ShowChart получает небольшой текстовый файл с исходными данными для построения круговой диаграммы, содержимое которого представлено ниже:
10,20,5,35,11,10,3,6,80,10,20,5,35,11,10,3,6,80
В этом файле находятся численные значения углов для отдельных секторов диаграммы, причем сумма этих значений равна 360 градусам. Наш аплет принимает этот файл через сеть и рисует круговую диаграмму, показанную на рис. 2.

Рис. 2. Круговая диаграмма, построенная на базе исходных данных, полученных через сеть
Файл исходных данных занимает всего 49 байт, поэтому он передается по сети очень быстро. Если бы мы передавали графическое изображение этой диаграммы, статическое или динамическое, подготовленное, например, расширением сервера CGI или ISAPI, объем передаваемых по сети данных был бы намного больше.
Блокировки
В основном хранилище для каждого объекта поддерживается блокировка (lock), над которой можно произвести два действия – установить (lock) и снять (unlock). Только один поток в один момент времени может установить блокировку на некоторый объект. Если до того, как этот поток выполнит операцию unlock, другой поток попытается установить блокировку, его выполнение будет приостановлено до тех пор, пока первый поток не отпустит ее.
Операции lock и unlock накладывают жесткое ограничение на работу с переменными в рабочей памяти потока. После успешно выполненного lock рабочая память очищается и все переменные необходимо заново считывать из основного хранилища. Аналогично, перед операцией unlock необходимо все переменные сохранить в основном хранилище.
Важно подчеркнуть, что блокировка является чем-то вроде флага. Если блокировка на объект установлена, это не означает, что данным объектом нельзя пользоваться, что его поля и методы становятся недоступными,– это не так. Единственное действие, которое становится невозможным,– установка этой же блокировки другим потоком, до тех пор, пока первый поток не выполнит unlock.
В Java-программе для того, чтобы воспользоваться механизмом блокировок, существует ключевое слово synchronized. Оно может быть применено в двух вариантах – для объявления synchronized-блока и как модификатор метода. В обоих случаях действие его примерно одинаковое.
Synchronized-блок записывается следующим образом:
synchronized (ref) { ... }
Прежде, чем начать выполнять действия, описанные в этом блоке, поток обязан установить блокировку на объект, на который ссылается переменная ref (поэтому она не может быть null). Если другой поток уже установил блокировку на этот объект, то выполнение первого потока приостанавливается до тех пор, пока не удастся выполнить операцию lock.
После этого блок выполняется. При завершении исполнения (как успешном, так и в случае ошибок) производится операция unlock, чтобы освободить объект для других потоков.
Рассмотрим пример:
public class ThreadTest implements Runnable { private static ThreadTest shared = new ThreadTest(); public void process() { for (int i=0; i<3; i++) { System.out.println( Thread.currentThread(). getName()+" "+i); Thread.yield(); } }
public void run() { shared.process(); } public static void main(String s[]) { for (int i=0; i<3; i++) { new Thread(new ThreadTest(), "Thread-"+i).start(); } } }
В этом простом примере три потока вызывают метод у одного объекта, чтобы тот распечатал три значения. Результатом будет:
Thread-0 0 Thread-1 0 Thread-2 0 Thread-0 1 Thread-2 1 Thread-0 2 Thread-1 1 Thread-2 2 Thread-1 2
То есть все потоки одновременно работают с одним методом одного объекта. Заключим обращение к методу в synchronized-блок:
public void run() { synchronized (shared) { shared.process(); } }
Теперь результат будет строго упорядочен:
Thread-0 0 Thread-0 1 Thread-0 2 Thread-1 0 Thread-1 1 Thread-1 2 Thread-2 0 Thread-2 1 Thread-2 2
Synchronized-методы работают аналогичным образом. Прежде, чем начать выполнять их, поток пытается заблокировать объект, у которого вызывается метод. После выполнения блокировка снимается. В предыдущем примере аналогичной упорядоченности можно было добиться, если использовать не synchronized-блок, а объявить метод process() синхронизированным.
Также допустимы методы static synchronized. При их вызове блокировка устанавливается на объект класса Class, отвечающего за тип, у которого вызывается этот метод.
При работе с блокировками всегда надо помнить о возможности появления deadlock – взаимных блокировок, которые приводят к зависанию программы. Если один поток заблокировал один ресурс и пытается заблокировать второй, а другой поток заблокировал второй и пытается заблокировать первый, то такие потоки уже никогда не выйдут из состояния ожидания.
Рассмотрим простейший пример:
Пример 12.4.
(html, txt)
Если запустить такую программу, то она никогда не закончит свою работу. Обратите внимание на вызовы метода yield() в каждом потоке. Они гарантируют, что когда один поток выполнил первую блокировку и переходит к следующей, второй поток находится в таком же состоянии. Очевидно, что в результате оба потока "замрут", не смогут продолжить свое выполнение. Первый поток будет ждать освобождения второго объекта, и наоборот. Именно такая ситуация называется "мертвой блокировкой", или deadlock. Если один из потоков успел бы заблокировать оба объекта, то программа успешно бы выполнилась до конца. Однако многопоточная архитектура не дает никаких гарантий, как именно потоки будут выполняться друг относительно друга. Задержки (которые в примере моделируются вызовами yield()) могут возникать из логики программы (необходимость произвести вычисления), действий пользователя (не сразу нажал кнопку "ОК"), занятости ОС (из-за нехватки физической оперативной памяти пришлось воспользоваться виртуальной), значений приоритетов потоков и так далее.
В Java нет никаких средств распознавания или предотвращения ситуаций deadlock. Также нет способа перед вызовом синхронизированного метода узнать, заблокирован ли уже объект другим потоком. Программист сам должен строить работу программы таким образом, чтобы неразрешимые блокировки не возникали. Например, в рассмотренном примере достаточно было организовать блокировки объектов в одном порядке (всегда сначала первый, затем второй) – и программа всегда выполнялась бы успешно.
Опасность возникновения взаимных блокировок заставляет с особенным вниманием относиться к работе с потоками. Например, важно помнить, что если у объекта потока был вызван метод sleep(..), то такой поток будет бездействовать определенное время, но при этом все заблокированные им объекты будут оставаться недоступными для блокировок со стороны других потоков, а это потенциальный deadlock. Такие ситуации крайне сложно выявить путем тестирования и отладки, поэтому вопросам синхронизации надо уделять много времени на этапе проектирования.
// Запускаем потоки t1.start(); t2.start(); } }
Пример 12.4.
Если запустить такую программу, то она никогда не закончит свою работу. Обратите внимание на вызовы метода yield() в каждом потоке. Они гарантируют, что когда один поток выполнил первую блокировку и переходит к следующей, второй поток находится в таком же состоянии. Очевидно, что в результате оба потока "замрут", не смогут продолжить свое выполнение. Первый поток будет ждать освобождения второго объекта, и наоборот. Именно такая ситуация называется "мертвой блокировкой", или deadlock. Если один из потоков успел бы заблокировать оба объекта, то программа успешно бы выполнилась до конца. Однако многопоточная архитектура не дает никаких гарантий, как именно потоки будут выполняться друг относительно друга. Задержки (которые в примере моделируются вызовами yield()) могут возникать из логики программы (необходимость произвести вычисления), действий пользователя (не сразу нажал кнопку "ОК"), занятости ОС (из-за нехватки физической оперативной памяти пришлось воспользоваться виртуальной), значений приоритетов потоков и так далее.
В Java нет никаких средств распознавания или предотвращения ситуаций deadlock. Также нет способа перед вызовом синхронизированного метода узнать, заблокирован ли уже объект другим потоком. Программист сам должен строить работу программы таким образом, чтобы неразрешимые блокировки не возникали. Например, в рассмотренном примере достаточно было организовать блокировки объектов в одном порядке (всегда сначала первый, затем второй) – и программа всегда выполнялась бы успешно.
Опасность возникновения взаимных блокировок заставляет с особенным вниманием относиться к работе с потоками. Например, важно помнить, что если у объекта потока был вызван метод sleep(..), то такой поток будет бездействовать определенное время, но при этом все заблокированные им объекты будут оставаться недоступными для блокировок со стороны других потоков, а это потенциальный deadlock. Такие ситуации крайне сложно выявить путем тестирования и отладки, поэтому вопросам синхронизации надо уделять много времени на этапе проектирования.
Демон-потоки
Демон-потоки позволяют описывать фоновые процессы, которые нужны только для обслуживания основных потоков выполнения и не могут существовать без них. Для работы с этим свойством существуют методы setDaemon() и isDaemon().
Рассмотрим следующий пример:
Пример 12.1.
(html, txt)
В этом примере происходит следующее. Потоки ThreadTest имеют некоторое стартовое значение, передаваемое им при создании. В методе run() это значение последовательно уменьшается. При достижении половины от начальной величины порождается новый поток с вдвое меньшим начальным значением. По исчерпании счетчика поток останавливается. Метод main() порождает первый поток со стартовым значением 16. В ходе программы будут дополнительно порождены потоки со значениями 8, 4, 2.
За этим процессом наблюдает демон-поток DaemonDemo. Этот поток регулярно получает список всех существующих потоков ThreadTest и распечатывает их имена для удобства наблюдения.
Результатом программы будет:
Пример 12.2.
(html, txt)
Несмотря на то, что демон-поток никогда не выходит из метода run(), виртуальная машина прекращает работу, как только все не-демон-потоки завершаются.
В примере использовалось несколько дополнительных классов и методов, которые еще не были рассмотрены:
класс ThreadGroup
Все потоки находятся в группах, представляемых экземплярами класса ThreadGroup. Группа указывается при создании потока. Если группа не была указана, то поток помещается в ту же группу, где находится поток, породивший его.
Методы activeCount() и enumerate() возвращают количество и полный список, соответственно, всех потоков в группе.
sleep()
Этот статический метод класса Thread приостанавливает выполнение текущего потока на указанное количество миллисекунд. Обратите внимание, что метод требует обработки исключения InterruptedException. Он связан с возможностью активизировать метод, который приостановил свою работу. Например, если поток занят выполнением метода sleep(), то есть бездействует на протяжении указанного периода времени, его можно вывести из этого состояния, вызвав метод interrupt() из другого потока выполнения. В результате метод sleep() прервется исключением InterruptedException.
Кроме метода sleep(), существует еще один статический метод yield() без параметров. Когда поток вызывает его, он временно приостанавливает свою работу и позволяет отработать другим потокам. Один из методов обязательно должен применяться внутри бесконечных циклов ожидания, иначе есть риск, что такой ничего не делающий поток затормозит работу остальных потоков.
Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 4, Thread 16, Thread 8, Thread 4, Thread 8, Thread 4, Thread 4, Thread 2, Thread 2,
Пример 12.2.
Несмотря на то, что демон-поток никогда не выходит из метода run(), виртуальная машина прекращает работу, как только все не-демон-потоки завершаются.
В примере использовалось несколько дополнительных классов и методов, которые еще не были рассмотрены:
класс ThreadGroup
Все потоки находятся в группах, представляемых экземплярами класса ThreadGroup. Группа указывается при создании потока. Если группа не была указана, то поток помещается в ту же группу, где находится поток, породивший его.
Методы activeCount() и enumerate() возвращают количество и полный список, соответственно, всех потоков в группе.
sleep()
Этот статический метод класса Thread приостанавливает выполнение текущего потока на указанное количество миллисекунд. Обратите внимание, что метод требует обработки исключения InterruptedException. Он связан с возможностью активизировать метод, который приостановил свою работу. Например, если поток занят выполнением метода sleep(), то есть бездействует на протяжении указанного периода времени, его можно вывести из этого состояния, вызвав метод interrupt() из другого потока выполнения. В результате метод sleep() прервется исключением InterruptedException.
Кроме метода sleep(), существует еще один статический метод yield() без параметров. Когда поток вызывает его, он временно приостанавливает свою работу и позволяет отработать другим потокам. Один из методов обязательно должен применяться внутри бесконечных циклов ожидания, иначе есть риск, что такой ничего не делающий поток затормозит работу остальных потоков.
public class ThreadTest implements Runnable
|
public class ThreadTest implements Runnable { // Отдельная группа, в которой будут // находиться все потоки ThreadTest public final static ThreadGroup GROUP = new ThreadGroup("Daemon demo"); // Стартовое значение, указывается при создании объекта private int start; public ThreadTest(int s) { start = (s%2==0)? s: s+1; new Thread(GROUP, this, "Thread "+ start).start(); } public void run() { // Начинаем обратный отсчет for (int i=start; i>0; i--) { try { Thread.sleep(300); } catch (InterruptedException e) {} // По достижении середины порождаем // новый поток с половинным начальным // значением if (start>2 && i==start/2) { new ThreadTest(i); } } } public static void main(String s[]) { new ThreadTest(16); new DaemonDemo(); } } public class DaemonDemo extends Thread { public DaemonDemo() { super("Daemon demo thread"); setDaemon(true); start(); } public void run() { Thread threads[]=new Thread[10]; while (true) { // Получаем набор всех потоков из // тестовой группы int count=ThreadTest.GROUP.activeCount(); if (threads.length<count) threads = new Thread[count+10]; count=ThreadTest.GROUP.enumerate(threads); // Распечатываем имя каждого потока for (int i=0; i<count; i++) { System.out.print(threads[i].getName()+", "); } System.out.println(); try { Thread.sleep(300); } catch (InterruptedException e) {} } } } |
| Пример 12.1. |
| Закрыть окно |
| Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 16, Thread 8, Thread 4, Thread 16, Thread 8, Thread 4, Thread 8, Thread 4, Thread 4, Thread 2, Thread 2, |
| Пример 12.2. |
| Закрыть окно |
|
public class ThreadTest { private int a=1, b=2; public void one() { a=b; } public void two() { b=a; } public static void main(String s[]) { int a11=0, a22=0, a12=0; for (int i=0; i<1000; i++) { final ThreadTest o = new ThreadTest(); // Запускаем первый поток, который // вызывает один метод new Thread() { public void run() { o.one(); } }.start(); // Запускаем второй поток, который // вызывает второй метод new Thread() { public void run() { o.two(); } }.start(); // даем потокам время отработать try { Thread.sleep(100); } catch (InterruptedException e) {} // анализируем финальные значения if (o.a==1 && o.b==1) a11++; if (o.a==2 && o.b==2) a22++; if (o.a!=o.b) a12++; } System.out.println(a11+" "+a22+" "+a12); } } |
| Пример 12.3. |
| Закрыть окно |
|
public class DeadlockDemo { // Два объекта- ресурса public final static Object one=new Object(), two=new Object(); public static void main(String s[]) { // Создаем два потока, которые будут // конкурировать за доступ к объектам // one и two Thread t1 = new Thread() { public void run() { // Блокировка первого объекта synchronized(one) { Thread.yield(); // Блокировка второго объекта synchronized (two) { System.out.println("Success!"); } } } }; Thread t2 = new Thread() { public void run() { // Блокировка второго объекта synchronized(two) { Thread.yield(); // Блокировка первого объекта synchronized (one) { System.out.println("Success!"); } } } }; // Запускаем потоки t1.start(); t2.start(); } } |
| Пример 12.4. |
| Закрыть окно |
|
public class ThreadTest implements Runnable { final static private Object shared=new Object(); private int type; public ThreadTest(int i) { type=i; } public void run() { if (type==1 || type==2) { synchronized (shared) { try { shared.wait(); } catch (InterruptedException e) {} System.out.println("Thread "+type+" after wait()"); } } else { synchronized (shared) { shared.notifyAll(); System.out.println("Thread "+type+" after notifyAll()"); } } } public static void main(String s[]) { ThreadTest w1 = new ThreadTest(1); new Thread(w1).start(); try { Thread.sleep(100); } catch (InterruptedException e) {} ThreadTest w2 = new ThreadTest(2); new Thread(w2).start(); try { Thread.sleep(100); } catch (InterruptedException e) {} ThreadTest w3 = new ThreadTest(3); new Thread(w3).start(); } } |
| Пример 12.5. |
| Закрыть окно |
| Thread 3 after notifyAll() Thread 1 after wait() Thread 2 after wait() |
| Пример 12.6. |
| Закрыть окно |
Хранение переменных в памяти
Виртуальная машина поддерживает основное хранилище данных (main storage), в котором сохраняются значения всех переменных и которое используется всеми потоками. Под переменными здесь понимаются поля объектов и классов, а также элементы массивов. Что касается локальных переменных и параметров методов, то их значения не могут быть доступны другим потокам, поэтому они не представляют интереса.
Для каждого потока создается его собственная рабочая память (working memory), в которую перед использованием копируются значения всех переменных.
Рассмотрим основные операции, доступные для потоков при работе с памятью:
use – чтение значения переменной из рабочей памяти потока;
assign – запись значения переменной в рабочую память потока;
read – получение значения переменной из основного хранилища;
load – сохранение значения переменной, прочитанного из основного хранилища, в рабочей памяти;
store – передача значения переменной из рабочей памяти в основное хранилище для дальнейшего хранения;
write – сохраняет в основном хранилище значение переменной, переданной командой store.
Подчеркнем, что перечисленные команды не являются методами каких-либо классов, они недоступны программисту. Сама виртуальная машина использует их для обеспечения корректной работы потоков исполнения.
Поток, работая с переменной, регулярно применяет команды use и assign для использования ее текущего значения и присвоения нового. Кроме того, должны осуществляться действия по передаче значений в основное хранилище и из него. Они выполняются в два этапа. При получении данных сначала основное хранилище считывает значение командой read, а затем поток сохраняет результат в своей рабочей памяти командой load. Эта пара команд всегда выполняется вместе именно в таком порядке, т.е. нельзя выполнить одну, не выполнив другую. При отправлении данных сначала поток считывает значение из рабочей памяти командой store, а затем основное хранилище сохраняет его командой write. Эта пара команд также всегда выполняется вместе именно в таком порядке, т.е. нельзя выполнить одну, не выполнив другую.
Набор этих правил составлялся с тем, чтобы операции с памятью были достаточно строги для точного анализа их результатов, а с другой стороны, правила должны оставлять достаточное пространство для различных технологий оптимизаций (регистры, очереди, кэш и т.д.).
Последовательность команд подчиняется следующим правилам:
все действия, выполняемые одним потоком, строго упорядочены, т.е. выполняются одно за другим;все действия, выполняемые с одной переменной в основном хранилище памяти, строго упорядочены, т.е. следуют одно за другим.
За исключением некоторых дополнительных очевидных правил, больше никаких ограничений нет. Например, если поток изменил значение сначала одной, а затем другой переменной, то эти изменения могут быть переданы в основное хранилище в обратном порядке.
Поток создается с чистой рабочей памятью и должен перед использованием загрузить все необходимые переменные из основного хранилища. Любая переменная сначала создается в основном хранилище и лишь затем копируется в рабочую память потоков, которые будут ее применять.
Таким образом, потоки никогда не взаимодействуют друг с другом напрямую, только через главное хранилище.
Инициализация клиента
Процесс инициализации клиентского приложения выглядит весьма просто. Клиент должен просто создать сокет как объект класса Socket, указав адрес IP серверного приложения и номер порта, используемого сервером:
Socket s; s = new Socket("localhost",9999);
Здесь в качестве адреса IP мы указали специальный адрес localhost, предназначенный для тестирования сетевых приложений, а в качестве номера порта - ззначение 9999, использованное сервером.
Теперь можно создавать входной и выходной потоки. На стороне клиента эта операция выполняется точно также, как и на стороне сервера:
InputStream is; OutputStream os; is = s.getInputStream(); os = s.getOutputStream();
Инициализация сервера
Вначале мы рассмотрим действия приложения, которое на момент инициализации является сервером.
Первое, что должно сделать серверное приложение, это создать объект класса ServerSocket, указав конструктору этого класса номер используемого порта:
ServerSocket ss; ss = new ServerSocket(9999);
Заметим, что объект класса ServerSocket вовсе не является сокетом. Он предназначен всего лишь для установки канала связи с клиентским приложением, после чего создается сокет класса Socket, пригодный для передачи данных.
Установка канала связи с клиентским приложением выполняется при помощи метода accept, определенного в классе ServerSocket:
Socket s; s = ss.accept();
Метод accept приостанавливает работу вызвавшего потока до тех пор, пока клиентское приложение не установит канал связи с сервером. Если ваше приложение однопоточное, его работа будет блокирована до момента установки канала связи. Избежать полной блокировки приложения можно, если выполнять создание канала передачи данных в отдельном потоке.
Как только канал будет создан, вы можете использовать сокет сервера для образования входного и выходного потока класса InputStream и OutputStream, соответственно:
InputStream is; OutputStream os; is = s.getInputStream(); os = s.getOutputStream();
Эти потоки можно использовать таким же образом, что и потоки, связанные с файлами.
Обратите также внимание на то, что при создании серверного сокета мы не указали адрес IP и тип сокета, ограничившись только номером порта.
Что касается адреса IP, то он, очевидно, равен адресу IP узла, на котором запущено приложение сервера. В классе ServerSocket определен метод getInetAddress, позволяющий определить этот адрес:
public InetAddress getInetAddress();
Тип сокета указывать не нужно, так как для работы с датаграммными сокетами предназначен класс DatagramSocket, который мы рассмотрим позже.
Интерфейс Runnable
Описанный подход имеет один недостаток. Поскольку в Java множественное наследование отсутствует, требование наследоваться от Thread может привести к конфликту. Если еще раз посмотреть на приведенный выше пример, станет понятно, что наследование производилось только с целью переопределения метода run(). Поэтому предлагается более простой способ создать свой поток исполнения. Достаточно реализовать интерфейс Runnable, в котором объявлен только один метод – уже знакомый void run(). Запишем пример, приведенный выше, с помощью этого интерфейса:
public class MyRunnable implements Runnable { public void run() { // некоторое долгое действие, вычисление long sum=0; for (int i=0; i<1000; i++) { sum+=i; } System.out.println(sum); } }
Также незначительно меняется процедура запуска потока:
Runnable r = new MyRunnable(); Thread t = new Thread(r); t.start();
Если раньше объект, представляющий сам поток выполнения, и объект с методом run(), реализующим необходимую функциональность, были объединены в одном экземпляре класса MyThread, то теперь они разделены. Какой из двух подходов удобней, решается в каждом конкретном случае.
Подчеркнем, что Runnable не является полной заменой классу Thread, поскольку создание и запуск самого потока исполнения возможно только через метод Thread.start().
Исходные тексты аплета Form
Исходные тексты аплета Form представлены в листинге 5.
Листинг 5. Файл Form.java
import java.applet.*; import java.awt.*; import java.net.*; import java.io.*; import java.util.*;
public class Form extends Applet implements Runnable { private Thread m_store = null;
TextField txtName; TextField txtEMail; TextArea txta; Button btnGetText;
public void init() { Label lbName; Label lbEMail; Label lbPress;
lbName = new Label("Enter your name:"); lbEMail = new Label( "Enter your E-Mail address:");
add(lbName);
txtName = new TextField("Your name", 40); add(txtName);
add(lbEMail);
txtEMail = new TextField("your@email", 40); add(txtEMail);
btnGetText = new Button("Send!"); add(btnGetText);
txta = new TextArea(8, 65); add(txta);
setBackground(Color.yellow); }
public void paint(Graphics g) { setBackground(Color.yellow);
Dimension dimAppWndDimension = getSize(); g.setColor(Color.black); g.drawRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1); }
public boolean action(Event evt, Object obj) { Button btn;
if(evt.target instanceof Button) { btn = (Button)evt.target;
if(evt.target.equals(btnGetText)) { startTransaction(); } else return false; return true; } return false; }
void startTransaction() { m_store = new Thread(this); m_store.start(); }
public void stop() { if (m_store != null) { m_store.stop(); m_store = null; } }
public void run() { URL u; URLConnection c; PrintStream ps; DataInputStream is;
try { String szSourceStr = txtName.getText() + ", " + txtEMail.getText();
String szReceived; String szURL = "http://frolov/scripts/store.exe";
u = new URL(szURL); c = u.openConnection();
ps = new PrintStream( c.getOutputStream()); ps.println(szSourceStr); ps.close();
is = new DataInputStream( c.getInputStream());
szReceived = is.readLine(); is.close();
txta.appendText(szReceived + "\r\n"); repaint(); } catch (Exception ioe) { showStatus(ioe.toString()); stop(); } } }
Исходный текст документа HTML, который был подготовлен для нас системой Java Workshop, мы немного отредактировали, изменив параметр CODEBASE (листинг 6).
Листинг 6. Файл Form.tmp.html
<applet name="Form" code="Form.class" codebase="http://frolov/" width="500" height="200" align="Top" alt="If you had a java-enabled browser, you would see an applet here."> <hr>If your browser recognized the applet tag, you would see an applet here.<hr> </applet>
В этом параметре следует указать путь к каталогу, в котором располагается байт-код аплета.
Исходные тексты аплета ShowChart
Исходный текст приложения ShowChart приведен в листинге 1.
Листинг 1. Файл ShowChart.java
import java.applet.*; import java.awt.*; import java.net.*; import java.io.*; import java.util.*;
public class ShowChart extends Applet { URL SrcURL; Object URLContent; int errno = 0; String str; byte buf[] = new byte[200];
public String getAppletInfo() { return "Name: ShowChart"; }
public void init() { try { SrcURL = new URL( "http://frolov/chart.txt"); try { InputStream is = SrcURL.openStream(); is.read(buf); str = new String(buf, 0); } catch (IOException ioe) { showStatus("read exception"); errno = 1; } } catch (MalformedURLException uex) { showStatus( "MalformedURLException exception"); errno = 2; } }
public void paint(Graphics g) { Integer AngleFromChart = new Integer(0); int PrevAngle = 0; int rColor, gColor, bColor; Dimension dimAppWndDimension = getSize();
g.setColor(Color.yellow); g.fillRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
g.setColor(Color.black); g.drawRect(0, 0, dimAppWndDimension.width - 1, dimAppWndDimension.height - 1);
showStatus(str); StringTokenizer st = new StringTokenizer(str, ",\r\n");
while(st.hasMoreElements()) { rColor = (int)(255 * Math.random()); gColor = (int)(255 * Math.random()); bColor = (int)(255 * Math.random());
g.setColor(new Color(rColor, gColor, bColor));
String angle = (String)st.nextElement(); AngleFromChart = new Integer(angle) ; g.fillArc(0, 0, 200, 200, PrevAngle, AngleFromChart.intValue()); PrevAngle += AngleFromChart.intValue(); } } }
Исходный текст документа HTML, созданного автоматически для нашего аплета, представлен в листинге 2.
Листинг 2. Файл ShowChart.tmp.html
<applet name="ShowChart" code="ShowChart" codebase= "file:/e:/Sun/Articles/vol12/src/ShowChart" width="200" height="200" align="Top" alt="If you had a java-enabled browser, you would see an applet here."> <hr>If your browser recognized the applet tag, you would see an applet here. <hr> </applet>
Исходный текст клиентского приложения SocketClient
Исходный текст клиентского приложения SocketClient приведен в листинге4.
Листинг 4. Файл SocketClient.java
import java.io.*; import java.net.*; import java.util.*;
public class SocketClient { public static void main(String args[]) { byte bKbdInput[] = new byte[256]; Socket s; InputStream is; OutputStream os;
try { System.out.println( "Socket Client Application" + "\nEnter any string or" + " 'quit' to exit..."); } catch(Exception ioe) { System.out.println(ioe.toString()); }
try { s = new Socket("localhost",9999); is = s.getInputStream(); os = s.getOutputStream(); byte buf[] = new byte[512]; int length; String str;
while(true) { length = System.in.read(bKbdInput); if(length != 1) { str = new String(bKbdInput, 0);
StringTokenizer st; st = new StringTokenizer( str, "\r\n"); str = new String( (String)st.nextElement());
System.out.println("> " + str);
os.write(bKbdInput, 0, length); os.flush();
length = is.read(buf); if(length == -1) break;
str = new String(buf, 0); st = new StringTokenizer( str, "\r\n"); str = new String( (String)st.nextElement()); System.out.println(">> " + str);
if(str.equals("quit")) break; } } is.close(); os.close(); s.close(); } catch(Exception ioe) { System.out.println(ioe.toString()); }
try { System.out.println( "Press <Enter> to " + "terminate application..."); System.in.read(bKbdInput); } catch(Exception ioe) { System.out.println(ioe.toString()); } } }
Исходный текст программы CGI store.exe
Исходный текст программы CGI store.exe очень прост и показан в листинге 7.
Листинг 7. Файл store.c
#include <windows.h> #include <tchar.h> #include <wchar.h> #include <stdio.h> #include <stdlib.h> #include <string.h>
void main(int argc, char *argv[]) { int nInDatasize; char * szMethod; char szBuf[2000];
FILE *fDatabase; CRITICAL_SECTION csAddRecord;
szMethod = getenv("REQUEST_METHOD"); if(!strcmp(szMethod, "POST")); { nInDatasize = atoi( getenv("CONTENT_LENGTH"));
fread(szBuf, nInDatasize, 1, stdin); szBuf[nInDatasize] = '\0';
InitializeCriticalSection(&csAddRecord); EnterCriticalSection(&csAddRecord);
fDatabase = fopen("c:\\EMAIL.DAT", "a+"); if(fDatabase != NULL) { fputs(szBuf, fDatabase); fclose(fDatabase); }
LeaveCriticalSection(&csAddRecord); DeleteCriticalSection(&csAddRecord);
printf( "Content-type: text/plain\r\n\r\n"); printf("Stored information: %s", szBuf); } }
Этот текст подготовлен для работы в среде Windows 95 или Windows NT, так как для синхронизации доступа к файлу мы использовали специфические для этих операционных систем функции работы с критическими секциями.
Свою работу программа CGI начинает с анализа переменной среды REQUEST_METHOD. Убедившись, что при запуске программы ей передали данные методом POST, программа определяет размер этих данных исходя из содержимого переменной среды CONTENT_LENGTH.
Далее программа считывает соответствующее количество байт данных из стандартного потока ввода, записывает их в файл. Затем, после добавления заголовка "Stored information:", программа CGI записывает полученную строку в стандартный выходной поток, передавая ее таким образом аплету Form.
Так как при реальной работе в сети Internet вашу программу CGI могут одновременно запустить несколько пользователей, для синхронизации обновления файла базы данных мы применили критическую секцию. В результате с файлом может работать в любой момент времени только одна копия программы CGI.
Еще одно замечание касается пути к файлу, который в нашем случае создается в корневом каталоге диска C:. При установке программы CGI на сервер вам необходимо обеспечить доступ на запись к каталогу, в котором располагается файл, для удаленных пользователей. О том, как это сделать, вы можете узнать из документации на ваш сервер Web.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Исходный текст серверного приложения SocketServ
Исходный текст серверного приложения SocketServ приведен в листинге3.
Листинг 3. Файл SocketServ.java
import java.io.*; import java.net.*; import java.util.*;
public class SocketServ { public static void main(String args[]) { byte bKbdInput[] = new byte[256]; ServerSocket ss; Socket s; InputStream is; OutputStream os;
try { System.out.println( "Socket Server Application"); } catch(Exception ioe) { System.out.println(ioe.toString()); }
try { ss = new ServerSocket(9999); s = ss.accept(); is = s.getInputStream(); os = s.getOutputStream(); byte buf[] = new byte[512]; int lenght;
while(true) { lenght = is.read(buf); if(lenght == -1) break;
String str = new String(buf, 0);
StringTokenizer st; st = new StringTokenizer( str, "\r\n"); str = new String( (String)st.nextElement());
System.out.println("> " + str); os.write(buf, 0, lenght); os.flush(); }
is.close(); os.close(); s.close(); ss.close(); } catch(Exception ioe) { System.out.println(ioe.toString()); }
try { System.out.println( "Press <Enter> to terminate application..."); System.in.read(bKbdInput); } catch(Exception ioe) { System.out.println(ioe.toString()); } } }
Использование датаграммных сокетов
Назад Вперед
Как мы уже говорили, датаграммные сокеты не гарантируют доставку пакетов данных. Тем не менее, они работают быстрее потоковых и обеспечивают возможность широковещательной расслыки пакетов данных одновременно всем узлам сети. Последняя возможность используется не очень широко в сети Internet, однако в корпоративной сети Intranet вы вполне можете ей воспользоваться.
Для работы с датаграммными сокетами приложение должно создать сокет на базе класса DatagramSocket, а также подготовить объект класса DatagramPacket, в который будет записан принятый от партнера по сети блок данных.
Канал, а также входные и выходные потоки создавать не нужно. Данные передаются и принимаются методами send и receive, определенными в классе DatagramSocket.
Класс DatagramPacket
Перед тем как принимать или передавать данные с использованием методов receive и send вы должны подготовить объекты класса DatagramPacket. Метод receive запишет в такой объект принятые данные, а метод send - перешлет данные из объекта класса DatagramPacket узлу, адрес которого указан в пакете.
Подготовка объекта класса DatagramPacket для приема пакетов выполняется с помощью следующего конструктора:
public DatagramPacket(byte ibuf[], int ilength);
Этому конструктору передается ссылка на массив ibuf, в который нужно будет записать данные, и размер этого массива ilength.
Если вам нужно подготовить пакет для передачи, воспользуйтесь конструктором, который дополнительно позволяет задать адрес IP iaddr и номер порта iport узла назначения:
public DatagramPacket(byte ibuf[], int ilength, InetAddress iaddr, int iport);
Таким образом, информация о том, в какой узел и на какой порт необходимо доставить пакет данных, хранится не в сокете, а в пакете, то есть в объекте класса DatagramPacket.
Помимо только что описанных конструкторов, в классе DatagramPacket определены четыре метода, позволяющие получить данные и информацию об адресе узла, из которого пришел пакет, или для которого предназначен пакет.
Метод getData возвращает ссылку на массив данных пакета:
public byte[] getData();
Размер пакета, данные из которого хранятся в этом массиве, легко определить с помощью метода getLength:
public int getLength();
Методы getAddress и getPort позволяют определить адрес и номер порта узла, откуда пришел пакет, или узла, для которого предназначен пакет:
public InetAddress getAddress(); public int getPort();
Если вы создаете клиент-серверную систему, в которой сервер имеет заранее известный адрес и номер порта, а клиенты - произвольные адреса и различные номера портов, то после получения пакета от клиента сервер может определить с помощью методов getAddress и getPort адрес клиента для установления с ним связи.
Если же адрес сервера неизвестен, клиент может посылать широковещательные пакеты, указав в объекте класса DatagramPacket адрес сети. Такая методика обычно используется в локальных сетях.
Как указать адрес сети?
Напомним, что адрес IP состоит из двух частей - адреса сети и адреса узла. Для разделения компонент 32-разрядного адреса IP используется 32-разрядная маска, в которой битам адреса сети соответствуют единицы, а битам адреса узла - нули.
Например, адрес узла может быть указан как 193.24.111.2. Исходя из значения старшего байта адреса, это сеть класса С, для которой по умолчанию используется маска 255.255.255.0. Следовательно, адрес сети будет такой: 193.24.111.0.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Класс DatagramSocket
Рассмотрим конструкторы и методы класса DatagramSocket, предназначенного для создания и использования датаграммных сокетов.
В классе DatagramSocket определены два конструктора, прототипы которых представлены ниже:
public DatagramSocket(int port); public DatagramSocket();
Первый из этих конструкторов позволяет определить порт для сокета, второй предполагает использование любого свободного порта.
Обычно серверные приложения работают с использованием какого-то заранее определенного порта, номер которого известен клиентским приложениям. Поэтому для серверных приложений больше подходит первый из приведенных выше конструкторов.
Клиентские приложения, напротив, часто применяют любые свободные на локальном узле порты, поэтому для них годится конструктор без параметров.
Кстати, с помощью метода getLocalPort приложение всегда может узнать номер порта, закрепленного за данным сокетом:
public int getLocalPort();
Прием и передача данных на датаграммном сокете выполняется с помощью методов receive и send, соответственно:
public void receive(DatagramPacket p); public void send(DatagramPacket p);
В качестве параметра этим методам передается ссылка на пакет данных (соответственно, принимаемый и передаваемый), определенный как объект класса DatagramPacket. Этот класс будет рассмотрен позже.
Еще один метод в классе DatagramSocket, которым вы будете пользоваться, это метод close, предназначенный для закрытия сокета:
public void close();
Напомним, что сборка мусора в Java выполняется только для объектов, находящихся в оперативной памяти. Такие объекты, как потоки и сокеты, вы должны закрывать после использования самостоятельно.
Класс Socket
Назад Вперед
После краткого введения в сокеты приведем описание наиболее интересных конструкторов и методов класса Socket.
Класс Thread
Поток выполнения в Java представляется экземпляром класса Thread. Для того, чтобы написать свой поток исполнения, необходимо наследоваться от этого класса и переопределить метод run(). Например,
public class MyThread extends Thread { public void run() { // некоторое долгое действие, вычисление long sum=0; for (int i=0; i<1000; i++) { sum+=i; } System.out.println(sum); } }
Метод run() содержит действия, которые должны выполняться в новом потоке исполнения. Чтобы запустить его, необходимо создать экземпляр класса-наследника и вызвать унаследованный метод start(), который сообщает виртуальной машине, что требуется запустить новый поток исполнения и начать выполнять в нем метод run().
MyThread t = new MyThread(); t.start();
В результате чего на консоли появится результат:
499500
Когда метод run() завершен (в частности, встретилось выражение return), поток выполнения останавливается. Однако ничто не препятствует записи бесконечного цикла в этом методе. В результате поток не прервет своего исполнения и будет остановлен только при завершении работы всего приложения.
Класс URL в библиотеке классов Java
Назад Вперед
Для работы с ресурсами, заданными своими адресами URL, в библиотеке классов Java имеется очень удобный и мощный класс с названием URL. Простота создания сетевых приложений с использованием этого класса в значительной степени опровергает общераспространенное убеждение в сложности сетевого программирования. Инкапсулируя в себе достаточно сложные процедуры, класс URL предоставляет в распоряжение программиста небольшой набор простых в использовании конструкторов и методов.
Класс URLConnection
Напомним, что в классе URL, рассмотренном нами в начале этой главы, мы привели прототип метода openConnection, возвращающий для заданного объекта класса URL ссылку на объект URLConnection:
public URLConnection openConnection();
Что мы можем получить, имея ссылку на этот объект?
Прежде всего, пользуясь этой ссылкой, мы можем получить содержимое объекта, адресуемое соответствующим объектом URL, методом getContent:
public Object getContent();
Заметим, что метод с таким же названием есть и в классе URL. Поэтому если все, что вы хотите сделать, это получение содержимое файла, адресуемое объектом класса URL, то нет никакой необходимости обращаться к классу URLConnection.
Метод getInputStream позволяет открыть входной поток данных, с помощью которого можно считать файл или получить данные от расширения сервера Web:
public InputStream getInputStream();
В классе URLConnection определен также метод getOutputStream, позволяющий открыть выходной поток данных:
public OutputStream getOutputStream();
Не следует думать, что этот поток можно использовать для записи файлов в каталоги сервера Web. Однако для этого потока есть лучшее применение - с его помощью можно передать данные расширению сервера Web.
Рассмотрим еще несколько полезных методов, определенных в классе URLConnection.
Метод connect предназначен для установки соединения с объектом, на который ссылается объект класса URL:
public abstract void connect();
Перед установкой соединения приложение может установить различные параметры соединения. Некоторые из методов, предназначенных для этого, приведены ниже:
setDefaultUseCaches
Включение или отключение кэширования по умолчанию
public void setDefaultUseCaches( boolean defaultusecaches);
setUseCaches
Включение или отключение кэширования
public void setUseCaches(boolean usecaches);
setDoInput
Возможность использования потока для ввода
public void setDoInput(boolean doinput);
setDoOutput
Возможность использования потока для вывода
public void setDoOutput(boolean dooutput);
setIfModifiedSince
Установка даты модификации документа
public void setIfModifiedSince( long ifmodifiedsince);
В классе URLConnection есть методы, позволяющие определить значения параметров, установленных только что описанными методами:
public boolean getDefaultUseCaches(); public boolean getUseCaches(); public boolean getDoInput(); public boolean getDoOutput(); public long getIfModifiedSince();
Определенный интерес могут представлять методы, предназначенные для извлечения информации из заголовка протокола HTTP:
getContentEncoding
Метод возвращает содержимое заголовка content-encoding (кодировка ресурса, на который ссылается URL)
public String getContentEncoding();
getContentLength
Метод возвращает содержимое заголовка content-length (размер документа)
public int getContentLength();
getContentType
Метод возвращает содержимое заголовка content-type (тип содержимого)
public String getContentType();
getDate
Метод возвращает содержимое заголовка date (дата посылки ресурса в секундах с 1 января 1970 года)
public long getDate();
getLastModified
Метод возвращает содержимое заголовка last-modified (дата изменения ресурса в секундах с 1 января 1970 года)
public long getLastModified();
getExpiration
Метод возвращает содержимое заголовка expires (дата устаревания ресурса в секундах с 1 января 1970 года)
public long getExpiration();
Другие методы, определенные в классе URLConnection, позволяют получить все заголовки или заголовки с заданным номером, а также другую информацию о соединении. При необходимости вы найдете описание этих методов в справочной системе Java WorkShop.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Конструкторы класса Socket
Чаще всего для создания сокетов в клиентских приложениях вы будете использовать один из двух конструкторов, прототипы которых приведены ниже:
public Socket(String host,int port); public Socket(InetAddress address,int port);
Первый из этих конструкторов позволяет указывать адрес серверного узла в виде текстовой строки, второй - в виде ссылки на объект класса InetAddress. Вторым параметром задается номер порта, с использованием которого будут передаваться данные.
В классе Socket определена еще одна пара конструкторов, которая, однако не рекомендуется для использования:
public Socket(String host, int port, boolean stream); public Socket(InetAddress address, int port, boolean stream);
В этих конструкторах последний параметр определяет тип сокета. Если этот параметр равен true, создается потоковый сокет, а если false - датаграммный. Заметим, что для работы с датаграммными сокетами следует использовать класс DatagramSocket.
Конструкторы класса URL
Сначала о конструкторах. Их в классе URL имеется четыре штуки.
public URL(String spec);
Первый из них создает объект URL для сетевого ресурса, адрес URL которого передается конструктору в виде текстовой строки через единственный параметр spec:
public URL(String spec);
В процессе создания объекта проверяется заданный адрес URL, а также наличие указанного в нем ресурса. Если адрес указан неверно или заданный в нем ресурс отсутствует, возникает исключение MalformedURLException. Это же исключение возникает при попытке использовать протокол, с которым данная система не может работать.
Второй вариант конструктора класса URL допускает раздельное указание протокола, адреса узла, номера порта, а также имя файла:
public URL(String protocol, String host, int port, String file);
Третий вариант предполагает использование номера порта, принятого по умолчанию:
public URL(String protocol, String host, String file);
Для протокола HTTP это порт с номером 80.
И, наконец, четвертый вариант конструктора допускает указание контекста адреса URL и строки адреса URL:
public URL(URL context, String spec);
Строка контекста позволяет указывать компоненты адреса URL, отсустсвующие в строке spec, такие как протокол, имя узла, файла или номер порта.
Метод equals
Вы можете использовать метод equals для определения идентичности адресов URL, заданных двумя объектами класса URL:
public boolean equals(Object obj);
Если адреса URL идентичны, метод equals возвращает значение true, если нет - значение false.
Метод getContent
Очень интересен метод getConten. Этот метод определяет и получает содержимое сетевого ресурса, для которого создан объект URL:
public final Object getContent();
Практически вы можете использовать метод getContent для получения текстовых файлов, расположенных в сетевых каталогах.
К сожалению, данный метод непригоден для получения документов HTML, так как для данного ресурса не определен обработчик соедржимого, предназначенный для создания объекта. Метод getContent не способен создать объект ни из чего другого, кроме текстового файла.
Данная проблема, тем не менее, решается очень просто - достаточно вместо метода getContent использовать описанную выше комбинацию методов openStream из класса URL и read из класса InputStream.
Метод getFile
Метод getFile позволяет получить информацию о файле, связанном с данным объектом URL:
public String getFile();
Метод getHost
С помощью метода getHost вы можете определить имя узла, соответствующего данному объекту URL:
public String getHost();
Метод getPort
Метод getPortt предназначен для определения номера порта, на котором выполняется связь для объекта URL:
public int getPort();
Метод getProtocol
С помощью метода getProtocol вы можете определить протокол, с использованием которого установлено соединение с ресурсом, заданным объектом URL:
public String getProtocol();
Метод getRef
Метод getRef возвращает текстовую строку ссылки на ресурс, соответствующий данному объекту URL:
public String getRef();
Метод hashCode
Метод hashCode возвращает хэш-код объекта URL:
public int hashCode();
Метод init
Во время инициализации метод init создает объект класса URL для файла исходных данных:
SrcURL = new URL("http://frolov/chart.txt");
Здесь для упрощения исходного текста мы указали адрес URL файла данных непосредственно в программе, однако вы можете передать этот адрес аплету через параметр в документе HTML.
Далее для нашего объекта URL мы создаем поток ввода и получаем содержимое файла (то есть исходные данные для построения диаграммы):
InputStream is = SrcURL.openStream(); is.read(buf);
Принятые данные записываются в буфер buf и затем преобразуются к типу String с помощью соответствующего конструктора:
str = new String(buf, 0);
Если при создании объекта класса URL возникло исключение, метод init записывает в поле errno код ошибки, равный 2, записывая при этом в строку состояния браузера сообщение "MalformedURLException exception".
В том случае, когда объект класса URL создан успешно, а исключение возникло в процессе чтения содержимого файла, в поле errno записывается значение 1, а в строку состояния браузера - сообщение "read exception".
Метод openConnection
Метод openConnection предназначен для создания канала между приложением и сетевым ресурсом, представленным объектом класса URL:
public URLConnection openConnection();
Если вы создаете приложение, которое позволяет читать из каталогов сервера Web текстовые или двоичные файлы, можно создать поток методом openStream или получить содержимое текстового ресурса методом getContent.
Однако есть и другая возможность. Вначале вы можете создать канал, как объект класса URLConnection, вызвав метод openConnection, а затем создать для этого канала входной поток, воспользовавшись методом getInputStream, определенным в классе URLConnection. Такая методика позволяет определить или установить перед созданием потока некоторые характеристики канала, например, задать кэширование.
Однако самая интересная возможность, которую предоставляет этот метод, заключается в организации взаимодействия приложения Java и сервера Web.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Метод openStream
Метод openStream позволяет создать входной поток для чтения файла ресурса, связанного с созданным объектом класса URL:
public final InputStream openStream();
Для выполнения операции чтения из созданного таким образом потока вы можете использовать метод read, определенный в классе InputStream (любую из его разновидностей).
Данную пару методов (openStream из класса URL и read из класса InputStream) можно применить для решения задачи получения содержимого двоичного или текстового файла, хранящегося в одном из каталогов сервера Web. Сделав это, обычное приложение Java или аплет может выполнить локальную обработку полученного файла на компьютере удаленного пользователя.
Метод paint
После раскрашивания фона окна аплета и рисования вокруг него рамки метод paint приступает к построению круговой диаграммы. Принятые данные отображаются в строке состояния браузера:
showStatus(sChart);
Далее создается разборщик строки исходных данных:
StringTokenizer st = new StringTokenizer(sChart, ",\r\n");
В качестве разделителей для этого разборщика указывается запятая, символ возврата каретки и перевода строки.
Рисование секторов диаграммы выполняется в цикле, условием выхода из которого является завершение разбора строки исходных данных:
while(st.hasMoreElements()) { . . . }
Для того чтобы секторы диаграммы не сливались, они должны иметь разный цвет. Цвет сектора можно было бы передавать вместе со значением угла через файл исходных данных, однако мы применили более простой способ раскаршивания секторов - в случайные цвета. Мы получаем случайные компоненты цвета сектора, а затем выбираем цвет в контекст отображения:
rColor = (int)(255 * Math.random()); gColor = (int)(255 * Math.random()); bColor = (int)(255 * Math.random()); g.setColor(new Color(rColor, gColor, bColor));
С помощью метода nextElement мы получаем очередное значение угла сектора и сохраняем его в переменной angle:
String angle = (String)st.nextElement();
Далее с помощью конструктора класса Integer это значение преобразуется в численное:
AngleFromChart = new Integer(angle);
Рисование сектора круговой диаграммы выполняется с помощью метода fillArc:
g.fillArc(0, 0, 200, 200, PrevAngle, AngleFromChart.intValue());
В качестве начального значения угла сектора используется значение из переменной PrevAngle. Сразу после инициализации в эту переменную записывается нулевое значение.
Конечный угол сектора задается как AngleFromChart.intValue(), то есть указывается значение, полученное из принятого по сети файла исходных данных.
После завершения рисования очередного сектора круговой диаграммы начальное значение PrevAngle увеличивается на величину угла нарисованного сектора:
PrevAngle += AngleFromChart.intValue();
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994- 2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Метод sameFile
С помощью метода sameFile вы можете определить, ссылаются ли два объекта класса URL на один и тот же ресурс, или нет:
public boolean sameFile(URL other);
Если объекты ссылаются на один и тот же ресурс, метод sameFile возвращает значение true, если нет - false.
Метод toExternalForm
Метод toExternalForm возвращает текстовую строку внешнего представления адреса URL, определенного данным объектом класса URL:
public String toExternalForm();
Метод toString
Метод toString возвращает текстовую строку, представляющую данный объект класса URL:
public String toString();
Методы класса Socket
Перечислим наиболее интересные, на наш взгляд, методы класса Socket.
Прежде всего, это методы getInputStream и getOutputStream, предназначенные для создания входного и выходного потока, соответственно:
public InputStream getInputStream(); public OutputStream getOutputStream();
Эти потоки связаны с сокетом и должны быть использованы для передачи данных по каналу связи.
Методы getInetAddress и getPort позволяют определить адрес IP и номер порта, связанные с данным сокетом (для удаленного узла):
public InetAddress getInetAddress(); public int getPort();
Метод getLocalPort возвращает для данного сокета номер локального порта:
public int getLocalPort();
После того как работа с сокетом завершена, его необходимо закрыть методом close:
public void close();
И, наконец, метод toString возвращает текстовую строку, представляющую сокет:
public String toString();
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Методы класса URL
Рассмотрим самые интересные методы, определенные в классе URL.
Методы wait(), notify(), notifyAll() класса Object
Наконец, перейдем к рассмотрению трех методов класса Object, завершая описание механизмов поддержки многопоточности в Java.
Каждый объект в Java имеет не только блокировку для synchronized блоков и методов, но и так называемый wait-set, набор потоков исполнения. Любой поток может вызвать метод wait() любого объекта и таким образом попасть в его wait-set. При этом выполнение такого потока приостанавливается до тех пор, пока другой поток не вызовет у этого же объекта метод notifyAll(), который пробуждает все потоки из wait-set. Метод notify() пробуждает один случайно выбранный поток из данного набора.
Однако применение этих методов связано с одним важным ограничением. Любой из них может быть вызван потоком у объекта только после установления блокировки на этот объект. То есть либо внутри synchronized-блока с ссылкой на этот объект в качестве аргумента, либо обращения к методам должны быть в синхронизированных методах класса самого объекта. Рассмотрим пример:
public class WaitThread implements Runnable { private Object shared;
public WaitThread(Object o) { shared=o; }
public void run() { synchronized (shared) { try { shared.wait(); } catch (InterruptedException e) {} System.out.println("after wait"); } }
public static void main(String s[]) { Object o = new Object(); WaitThread w = new WaitThread(o); new Thread(w).start(); try { Thread.sleep(100); } catch (InterruptedException e) {} System.out.println("before notify"); synchronized (o) { o.notifyAll(); } } }
Результатом программы будет:
before notify after wait
Обратите внимание, что метод wait(), как и sleep(), требует обработки InterruptedException, то есть его выполнение также можно прервать методом interrupt().
В заключение рассмотрим более сложный пример для трех потоков:
Пример 12.5.
(html, txt)
Результатом работы программы будет:
Пример 12.6.
(html, txt)
Рассмотрим, что произошло. Во-первых, был запущен поток 1, который тут же вызвал метод wait() и приостановил свое выполнение. Затем то же самое произошло с потоком 2. Далее начинает выполняться поток 3.
Сразу обращает на себя внимание следующий факт. Еще поток 1 вошел в synchronized-блок, а стало быть, установил блокировку на объект shared. Но, судя по результатам, это не помешало и потоку 2 зайти в synchronized-блок, а затем и потоку 3. Причем, для последнего это просто необходимо, иначе как можно "разбудить" потоки 1 и 2?
Можно сделать вывод, что потоки, прежде чем приостановить выполнение после вызова метода wait(), отпускают все занятые блокировки. Итак, вызывается метод notifyAll(). Как уже было сказано, все потоки из wait-set возобновляют свою работу. Однако чтобы корректно продолжить исполнение, необходимо вернуть блокировку на объект, ведь следующая команда также находится внутри synchronized-блока!
Получается, что даже после вызова notifyAll() все потоки не могут сразу возобновить работу. Лишь один из них сможет вернуть себе блокировку и продолжить работу. Когда он покинет свой synchronized-блок и отпустит объект, второй поток возобновит свою работу, и так далее. Если по какой-то причине объект так и не будет освобожден, поток так никогда и не выйдет из метода wait(), даже если будет вызван метод notifyAll(). В рассмотренном примере потоки один за другим смогли возобновить свою работу.
Кроме того, определен метод wait() с параметром, который задает период тайм-аута, по истечении которого поток сам попытается возобновить свою работу. Но начать ему придется все равно с повторного получения блокировки.
public static void main(String s[]) { ThreadTest w1 = new ThreadTest(1); new Thread(w1).start(); try { Thread.sleep(100); } catch (InterruptedException e) {} ThreadTest w2 = new ThreadTest(2); new Thread(w2).start(); try { Thread.sleep(100); } catch (InterruptedException e) {} ThreadTest w3 = new ThreadTest(3); new Thread(w3).start(); } }
Пример 12.5.
Результатом работы программы будет:
Thread 3 after notifyAll() Thread 1 after wait() Thread 2 after wait()
Пример 12.6.
Рассмотрим, что произошло. Во-первых, был запущен поток 1, который тут же вызвал метод wait() и приостановил свое выполнение. Затем то же самое произошло с потоком 2. Далее начинает выполняться поток 3.
Сразу обращает на себя внимание следующий факт. Еще поток 1 вошел в synchronized-блок, а стало быть, установил блокировку на объект shared. Но, судя по результатам, это не помешало и потоку 2 зайти в synchronized-блок, а затем и потоку 3. Причем, для последнего это просто необходимо, иначе как можно "разбудить" потоки 1 и 2?
Можно сделать вывод, что потоки, прежде чем приостановить выполнение после вызова метода wait(), отпускают все занятые блокировки. Итак, вызывается метод notifyAll(). Как уже было сказано, все потоки из wait-set возобновляют свою работу. Однако чтобы корректно продолжить исполнение, необходимо вернуть блокировку на объект, ведь следующая команда также находится внутри synchronized-блока!
Получается, что даже после вызова notifyAll() все потоки не могут сразу возобновить работу. Лишь один из них сможет вернуть себе блокировку и продолжить работу. Когда он покинет свой synchronized-блок и отпустит объект, второй поток возобновит свою работу, и так далее. Если по какой-то причине объект так и не будет освобожден, поток так никогда и не выйдет из метода wait(), даже если будет вызван метод notifyAll(). В рассмотренном примере потоки один за другим смогли возобновить свою работу.
Кроме того, определен метод wait() с параметром, который задает период тайм-аута, по истечении которого поток сам попытается возобновить свою работу. Но начать ему придется все равно с повторного получения блокировки.
Многопоточная архитектура
Не претендуя на полноту изложения, рассмотрим общее устройство многопоточной архитектуры, ее достоинства и недостатки.
Реализацию многопоточной архитектуры проще всего представить себе для системы, в которой есть несколько центральных вычислительных процессоров. В этом случае для каждого из них можно выделить задачу, которую он будет выполнять. В результате несколько задач будут обслуживаться одновременно.
Однако возникает вопрос – каким же тогда образом обеспечивается многопоточность в системах с одним центральным процессором, который, в принципе, выполняет лишь одно вычисление в один момент времени? В таких системах применяется процедура квантования времени (time-slicing). Время разделяется на небольшие интервалы. Перед началом каждого интервала принимается решение, какой именно поток выполнения будет отрабатываться на протяжении этого кванта времени. За счет частого переключения между задачами эмулируется многопоточная архитектура.
На самом деле, как правило, и для многопроцессорных систем применяется процедура квантования времени. Дело в том, что даже в мощных серверах приложений процессоров не так много (редко бывает больше десяти), а потоков исполнения запускается, как правило, гораздо больше. Например, операционная система Windows без единого запущенного приложения инициализирует десятки, а то и сотни потоков. Квантование времени позволяет упростить управление выполнением задач на всех процессорах.
Теперь перейдем к вопросу о преимуществах – зачем вообще может потребоваться более одного потока выполнения?
Среди начинающих программистов бытует мнение, что многопоточные программы работают быстрее. Рассмотрев способ реализации многопоточности, можно утверждать, что такие программы работают на самом деле медленнее. Действительно, для переключения между задачами на каждом интервале требуется дополнительное время, а ведь они (переключения) происходят довольно часто. Если бы процессор, не отвлекаясь, выполнял задачи последовательно, одну за другой, он завершил бы их заметно быстрее. Стало быть, преимущества заключаются не в этом.
Первый тип приложений, который выигрывает от поддержки многопоточности, предназначен для задач, где действительно требуется выполнять несколько действий одновременно. Например, будет вполне обоснованно ожидать, что сервер общего пользования станет обслуживать несколько клиентов одновременно. Можно легко представить себе пример из сферы обслуживания, когда имеется несколько потоков клиентов и желательно обслуживать их все одновременно.
Другой пример – активные игры, или подобные приложения. Необходимо одновременно опрашивать клавиатуру и другие устройства ввода, чтобы реагировать на действия пользователя. В то же время необходимо рассчитывать и перерисовывать изменяющееся состояние игрового поля.
Понятно, что в случае отсутствия поддержки многопоточности для реализации подобных приложений потребовалось бы реализовывать квантование времени вручную. Условно говоря, одну секунду проверять состояние клавиатуры, а следующую – пересчитывать и перерисовывать игровое поле. Если сравнить две реализации time-slicing, одну – на низком уровне, выполненную средствами, как правило, операционной системы, другую – выполняемую вручную, на языке высокого уровня, мало подходящего для таких задач, то становится понятным первое и, возможно, главное преимущество многопоточности. Она обеспечивает наиболее эффективную реализацию процедуры квантования времени, существенно облегчая и укорачивая процесс разработки приложения. Код переключения между задачами на Java выглядел бы куда более громоздко, чем независимое описание действий для каждого потока.
Следующее преимущество проистекает из того, что компьютер состоит не только из одного или нескольких процессоров. Вычислительное устройство – лишь один из ресурсов, необходимых для выполнения задач. Всегда есть оперативная память, дисковая подсистема, сетевые подключения, периферия и т.д. Предположим, пользователю требуется распечатать большой документ и скачать большой файл из сети. Очевидно, что обе задачи требуют совсем незначительного участия процессора, а основные необходимые ресурсы, которые будут задействованы на пределе возможностей, у них разные – сетевое подключение и принтер. Значит, если выполнять задачи одновременно, то замедление от организации квантования времени будет незначительным, процессор легко справится с обслуживанием обеих задач. В то же время, если каждая задача по отдельности занимала, скажем, два часа, то вполне вероятно, что и при одновременном исполнении потребуется не более тех же двух часов, а сделано при этом будет гораздо больше.
Если же задачи в основном загружают процессор (например, математические расчеты), то их одновременное исполнение займет в лучшем случае столько же времени, что и последовательное, а то и больше.
Третье преимущество появляется из-за возможности более гибко управлять выполнением задач. Предположим, пользователь системы, не поддерживающей многопоточность, решил скачать большой файл из сети, или произвести сложное вычисление, что занимает, скажем, два часа. Запустив задачу на выполнение, он может внезапно обнаружить, что ему нужен не этот, а какой-нибудь другой файл (или вычисление с другими начальными параметрами). Однако если приложение занимается только работой с сетью (вычислениями) и не реагирует на действия пользователя (не обрабатываются данные с устройств ввода, таких как клавиатура или мышь), то он не сможет быстро исправить ошибку. Получается, что процессор выполняет большее количество вычислений, но при этом приносит гораздо меньше пользы.
Процедура квантования времени поддерживает приоритеты (priority) задач. В Java приоритет представляется целым числом. Чем больше число, тем выше приоритет. Строгих правил работы с приоритетами нет, каждая реализация может вести себя по-разному на разных платформах. Однако есть общее правило – поток с более высоким приоритетом будет получать большее количество квантов времени на исполнение и таким образом сможет быстрее выполнять свои действия и реагировать на поступающие данные.
В описанном примере представляется разумным запустить дополнительный поток, отвечающий за взаимодействие с пользователем. Ему можно поставить высокий приоритет, так как в случае бездействия пользователя этот поток практически не будет занимать ресурсы машины. В случае же активности пользователя необходимо как можно быстрее произвести необходимые действия, чтобы обеспечить максимальную эффективность работы пользователя.
Рассмотрим здесь же еще одно свойство потоков. Раньше, когда рассматривались однопоточные приложения, завершение вычислений однозначно приводило к завершению выполнения программы. Теперь же приложение должно работать до тех пор, пока есть хоть один действующий поток исполнения. В то же время часто бывают нужны обслуживающие потоки, которые не имеют никакого смысла, если они остаются в системе одни. Например, автоматический сборщик мусора в Java запускается в виде фонового (низкоприоритетного) процесса. Его задача – отслеживать объекты, которые уже не используются другими потоками, и затем уничтожать их, освобождая оперативную память. Понятно, что работа одного потока garbage collector'а не имеет никакого смысла.
Такие обслуживающие потоки называют демонами (daemon), это свойство можно установить любому потоку. В итоге приложение выполняется до тех пор, пока есть хотя бы один поток не-демон.
Рассмотрим, как потоки реализованы в Java.
Модификатор volatile
При объявлении полей объектов и классов может быть указан модификатор volatile. Он устанавливает более строгие правила работы со значениями переменных.
Если поток собирается выполнить команду use для volatile переменной, то требуется, чтобы предыдущим действием с этой переменной было обязательно load, и наоборот – операция load может выполняться только перед use. Таким образом, переменная и главное хранилище всегда имеют самое последнее значение этой переменной.
Аналогично, если поток собирается выполнить команду store для volatile переменной, то требуется, чтобы предыдущим действием над этой переменной было обязательно assign, и наоборот – операция assign может выполняться, только если следующей будет store. Таким образом, переменная и главное хранилище всегда имеют самое последнее значение этой переменной.
Наконец, если проводятся операции над несколькими volatile переменными, то передача соответствующих изменений в основное хранилище должна проводиться строго в том же порядке.
При работе с обычными переменными компилятор имеет больше пространства для маневра. Например, при благоприятных обстоятельствах может оказаться возможным предсказать значение переменной, заранее вычислить и сохранить его, а затем в нужный момент использовать уже готовым.
Следует обратить внимание на два 64-разрядных типа, double и long. Поскольку многие платформы поддерживают лишь 32-битную память, величины этих типов рассматриваются как две переменные и все описанные действия выполняются независимо для двух половинок таких значений. Конечно, если производитель виртуальной машины считает возможным, он может обеспечить атомарность операций и над этими типами. Для volatile переменных это является обязательным требованием.
Описание исходного текста аплета ShowChart
Аплет ShowChart получает содержимое файла исходных данных для построения круговой диаграммы с помощью класса URL. Как вы увидите, для получения содержимого этого файла оно создает поток ввода явным образом.
Описание исходного текста клиентского приложения SocketClient
Внутри метода main клиентского приложения SocketClient определены переменные для ввода строки с клавиатуры (массив bKbdInput), сокет s класса Socket для работы с сервером SocketServ, входной поток is и выходной поток os, которые связаны с сокетом s.
После вывода на консоль приглашающей строки клиентское приложение создает сокет, вызывая конструктор класса Socket:
s = new Socket("localhost",9999);
В процессе отладки мы запускали сервер и клиент на одном и том же узле, поэтому в качестве адреса сервера указана строка "localhost". Номер порта сервера SocketServ равен 9999, поэтому мы и передали конструктору это значение.
После создания сокета наше клиентское приложение создает входной и выходной потоки, связанные с этим сокетом:
is = s.getInputStream(); os = s.getOutputStream();
Теперь клиентское приложение готово обмениваться данными с сервером.
Этот обмен выполняется в цикле, условием завершения которого является ввод пользователем строки "quit".
Внутри цикла приложение читает строку с клавиатуры, записывая ее в массив bKbdInput:
length = System.in.read(bKbdInput);
Количество введенных символов сохраняется в переменной length.
Далее если пользователь ввел строку, а не просто нажал на клавишу <Enter>, эта строка отображается на консоли и передается серверу:
os.write(bKbdInput, 0, length); os.flush();
Сразу после передачи сбрасывается буфер выходного потока.
Далее приложение читает ответ, посылаемый сервером, в буфер buf:
length = is.read(buf);
Напомним, что наш сервер посылает клиенту принятую строку в неизменном виде.
Если сервер закрыл канал, то метод read возвращает значение -1. В этом случае мы прерываем цикл ввода и передачи строк:
if(length == -1) break;
Если же ответ сервера принят успешно, принятые данные записываются в строку str, которая отображается на консоли клиента:
System.out.println(">> " + str);
Перед завершением своей работы клиент закрывает входной и выходной потоки, а также сокет, на котором выполнялась передача данных:
Описание исходного текста серверного приложения SocketServ
В методе main, получающем управление сразу после запуска приложения, мы определили несколько переменных.
Массив bKbdInput размером 256 байт предназначен для хранения строк, введенных при помощи клавиатуры.
В переменную ss класса ServerSocket будет записана ссылка на объект, предназначенный для установления канала связи через потоковый сокет (но не ссылка на сам сокет):
ServerSocket ss;
Ссылка на сокет, с использованием которого будет происходить передача данных, хранится в переменной с именем s класса Socket:
Socket s;
Кроме того, мы определили переменные is и os, соответственно, классов InputStream и OutputStream:
InputStream is; OutputStream os;
В эти переменные будут записаны ссылки на входной и выходной поток данных, которые связаны с сокетом.
После отображения на консоли строки названия приложения, метод main создает объект класса ServerSocket, указывая конструктору номер порта 9999:
ss = new ServerSocket(9999);
Конструктор возвращает ссылку на объект, с использованием которого можно установить канал передачи данных с клиентом.
Канал устанавливается методом accept:
s = ss.accept();
Этот метод переводит приложение в состояние ожидания до тех пор, пока не будет установлен канал передачи данных.
Метод accept в случае успешного создания канала передачи данных возвращает ссылку на сокет, с применением которого нужно принимать и передавать данные.
На следующем этапе сервер создает входной и выходной потоки, вызывая для этого методы getInputStream и getOutputStream, соответственно:
is = s.getInputStream(); os = s.getOutputStream();
Далее приложение подготавливает буфер buf для приема данных и определяет переменную length, в которую будет записываться размер принятого блока данных:
byte buf[] = new byte[512]; int lenght;
Теперь все готово для запуска цикла приема и обработки строк от клиентского приложения.
Для чтения строки мы вызываем метод read применительно ко входному потоку:
lenght = is.read(buf);
Этот метод возвращает управление только после того, как все данные будут прочитаны, блокируя приложение на время своей работы. Если такая блокировка нежелательна, вам следует выполнять обмен данными через сокет в отдельной задаче.
Описание исходныех текстов аплета Form
При инициализации метод init создает все необходимые органы управления и добавляет их в окно аплета.
Когда пользователь заполняет форму и нажимает кнопку Send, обработчик соответствующего события вызывает метод startTransaction, запускающий процесс обмена данными с расширением сервера Web:
if(evt.target.equals(btnGetText)) { startTransaction(); }
Метод startTransaction, определенный в нашем приложении, создает и запускает на выполнение поток, который и будет взаимодействовать с программой CGI:
void startTransaction() { m_store = new Thread(this); m_store.start(); }
При этом в качестве отдельного потока, работающего одновременно с кодом аплета, выступает метод run. Именно в нем сосредоточена вся логика обмена данными с сервером Web.
Так как в процессе взаимодействия могут возникать различные исключения, мы предусмотрели их обработку при помощи блока try-catch:
URL u; URLConnection c; PrintStream ps; DataInputStream is;
try { . . . } catch (Exception ioe) { showStatus(ioe.toString()); stop(); }
Название возникшего исключения будет отображено в строке состояния браузера.
Теперь о том, что делает метод run после получения управления.
Первым делом он извлекает из однострочных текстовых полей имя и электронный адрес, объединяя их и записывая полученную текстовую строку в поле szSourceStr:
String szSourceStr = txtName.getText() + ", " + txtEMail.getText();
В строке szURL находится адрес URL программы CGI:
String szURL = "http://frolov/scripts/store.exe";
В реальном приложении этот адрес необходимо передавать аплету через параметр. Мы использовали непосредственное кодирование только для упрощения исходного текста.
На следующем этапе метод run создает для программы CGI объект класса URL и открывает с ним соединение:
u = new URL(szURL); c = u.openConnection();
Пользуясь этим соединением, метод run создает форматированный поток вывода, записывает в него строку имени и электронного адреса, а затем закрывает поток:
ps = new PrintStream(c.getOutputStream()); ps.println(szSourceStr); ps.close();
Переданные таким образом данные попадут в стандартный поток ввода программы CGI, откуда она их и прочитает.
Сделав это, программа CGI запишет в стандартный выходной поток строку ответа, которую необходимо прочитать в методе run нашего аплета. Для этого мы открываем входной поток, создаем на его основе форматированный входной поток данных, читаем одну строку текста и закрываем входной поток:
is = new DataInputStream(c.getInputStream()); String szReceived; szReceived = is.readLine(); is.close();
Сразу после этого программа CGI завершит свою работу и будет готова к обработке новых запросов на добавление записей. Что же касается метода run, то он добавит полученную от расширения сервера текстовую строку в многострочное окно редактирования, как это показано ниже, а затем инициирует перерисовку окна аплета:
txta.appendText(szReceived + "\r\n"); repaint();
Заметим, что использованный нами способ передачи данных подходит только для латинских символов. Если вам нужно передавать символы кириллицы, следует преобразовывать их из кодировки UNICODE, например, в гексадецимальную кодировку, а в программе CGI выполнять обратное преобразование. Аналогичную методику можно применять и для передачи произвольных двоичных данных.
Определение адреса IP
Метод getAddress возвращает массив из чеырех байт адреса IP объекта. Байт с нулевым индексом этого массива содержит старший байт адреса IP.
Метод toString возвращает текстовую строку, которая содержит имя узла, разделитель '/' и адрес IP в виде четырех десятичных чисел, разделенных точками.
Определение имени узла
С помощью метода getHostName вы можете определить имя узла, для которого был создан объект класса InetAddress.
Передача данных между клиентом и сервером
После того как серверное и клиентское приложения создали потоки для приема и передачи данных, оба этих приложения могут читать и писать в канал данных, вызывая методы read и write, определенные в классах InputStream и OutputStream.
Ниже мы представили фрагмент кода, в котором приложение вначале читает данные из входного потока в буфер buf, а затем записывает прочитанные данные в выходной поток:
byte buf[] = new byte[512]; int lenght; lenght = is.read(buf); os.write(buf, 0, lenght); os.flush();
На базе потоков класса InputStream и OutputStream вы можете создать буферизованные потоки и потоки для передачи форматированных данных, о которых мы рассказывали раньше.
Передача данных с использованием сокетов
Назад Вперед
В библиотеке классов Java есть очень удобное средство, с помощью которых можно организовать взаимодействие между приложениями Java и аплетами, работающими как на одном и том же, так и на разных узлах сети TCP/IP. Это средство, родившееся в мире операционной системы UNIX, - так называемые сокеты (sockets).
Что такое сокеты?
Вы можете представить себе сокеты в виде двух розеток, в которые включен кабель, предназначенный для передачи данных через сеть. Переходя к компьютерной терминологии, скажем, что сокеты - это программный интерфейс, предназначенный для передачи данных между приложениями.
Прежде чем приложение сможет выполнять передачу аили прием данных, оно должно создать сокет, указав при этом адрес узла IP, номер порта, через который будут передаваться данные, и тип сокета.
С адресом узла IP вы уже сталкивались. Номер порта служит для идентификации приложения. Заметим, что существуют так называемые "хорошо известные" (well known) номера портов, зарезервированные для различных приложений. Например, порт с номером 80 зарезервирован для использования серверами Web при обмене данными через протокол HTTP.
Что же касается типов сокетов, то их два - потоковые и датаграммные.
С помощью потоковых сокетов вы можете создавать каналы передачи данных между двумя приложениями Java в виде потоков, которые мы уже рассматривали во второй главе. Потоки могут быть входными или выходными, обычными или форматированными, с использованием или без использования буферизации. Скоро вы убедитесь, что организовать обмен данными между приложениями Java с использованием потоковых сокетов не труднее, чем работать через потоки с обычными файлами.
Заметим, что потоковые сокеты позволяют передавать данные только между двумя приложениями, так как они предполагают создание канала между этими приложениями. Однако иногда нужно обеспечить взаимодействие нескольких клиентских приложений с одним серверным или нескольких клиентских приложений с несколькими серверными приложениями. В этом случае вы можете либо создавать в серверном приложении отдельные задачи и отдельные каналы для каждого клиентского приложения, либо воспользоваться датаграммными сокетами. Последние позволяют передавать данные сразу всем узлам сети, хотя такая возможность редко используется и часто блокируется администраторами сети.
Для передачи данных через датаграммные сокеты вам не нужно создавать канал - данные посылаются непосредственно тому приложению, для которого они предназначены с использованием адреса этого приложения в виде сокета и номера порта. При этом одно клиентское приложение может обмениваться данными с несколькими серверными приложениями или наоборот, одно серверное приложение - с несколькими клиентскими.
К сожалению, датаграммные сокеты не гарантируют доставку передаваемых пакетов данных. Даже если пакеты данных, передаваемые через такие сокеты, дошли до адресата, не гарантируется, что они будут получены в той же самой последовательности, в которой были переданы. Потоковые сокеты, напротив, гарантируют доставку пакетов данных, причем в правильной последовательности.
Причина отстутствия гарантии доставки данных при использовании датаграммных сокетов заключается в использовании такими сокетами протокола UDP, который, в свою очередь, основан на протоколе с негарантированной доставкой IP. Потоковые сокеты работают через протокол гарантированной доставки TCP.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Поля класса ShowChart
В классе ShowChart определены пять полей.
URL SrcURL; Object URLContent; int errno = 0; String str; byte buf[] = new byte[200];
Поле SrcURL класса URL хранит адрес URL файла исходных данных для круговой диаграммы. В поле URLContent типа Object будет переписано содержимое этого файла. В поле errno хранится текущий код ошибки, если она возникла, или нулевое значение, если все операции были выполнены без ошибок.
Поле str хранит принятую строку, которая предварительно записывается во временный буфер buf.
Приложения SocketServ и SocketClient
Назад Вперед
В качестве примера мы приведем исходные тексты двух приложений Java, работающих с потоковыми сокетами. Одно из этих приложений называется SocketServ и выполняет роль сервера, второе называется SocketClient и служит клиентом.
Приложение SocketServ выводит на консоль строку "Socket Server Application" и затем переходит в состояние ожидания соединения с клиентским приложением SocketClient.
Приложение SocketClient устанавливает соединение с сервером SocketServ, используя потоковый сокет с номером 9999 (этот номер выбран нами произвольно). Далее клиентское приложение выводит на свою консоль приглашение для ввода строк. Введенные строки отображаются на консоли и передаются серверному приложению. Сервер, получив строку, отображает ее в своем окне и посылает обратно клиенту. Клиент выводит полученную от сервера строку на консоли.
Когда пользователь вводит строку "quit", цикл ввода и передачи строк завершается.
Весь процесс показан на рис. 3 и 4.
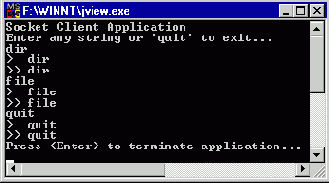
Рис. 3. Окно клиентского приложения

Рис. 4. Окно серверного приложения
Здесь в окне клиентского приложения мы ввели несколько строк, причем последняя строка была строкой "quit", завершившая работу приложений.
Работа с потоковыми сокетами
Назад Вперед
Как мы уже говорили, интерфейс сокетов позволяет передавать данные между двумя приложениями, работающими на одном или разных узлах сети. В процессе создания канала передачи данных одно из этих приложений выполняет роль сервера, а другое - роль клиента. После того как канал будет создан, приложения становятся равноправными - они могут передавать друг другу данные симметричным образом.
Рассмотрим этот процесс в деталях.
Работа с приоритетами
Рассмотрим, как в Java можно назначать потокам приоритеты. Для этого в классе Thread существуют методы getPriority() и setPriority(), а также объявлены три константы:
MIN_PRIORITY MAX_PRIORITY NORM_PRIORITY
Из названия понятно, что их значения описывают минимальное, максимальное и нормальное (по умолчанию) значения приоритета.
Рассмотрим следующий пример:
public class ThreadTest implements Runnable { public void run() { double calc; for (int i=0; i<50000; i++) { calc=Math.sin(i*i); if (i%10000==0) { System.out.println(getName()+ " counts " + i/10000); } } }
public String getName() { return Thread.currentThread().getName(); }
public static void main(String s[]) { // Подготовка потоков Thread t[] = new Thread[3]; for (int i=0; i<t.length; i++) { t[i]=new Thread(new ThreadTest(), "Thread "+i); } // Запуск потоков for (int i=0; i<t.length; i++) { t[i].start(); System.out.println(t[i].getName()+ " started"); } } }
В примере используется несколько новых методов класса Thread:
getName()
Обратите внимание, что конструктору класса Thread передается два параметра. К реализации Runnable добавляется строка. Это имя потока, которое используется только для упрощения его идентификации. Имена нескольких потоков могут совпадать. Если его не задать, то Java генерирует простую строку вида "Thread-" и номер потока (вычисляется простым счетчиком). Именно это имя возвращается методом getName(). Его можно сменить с помощью метода setName().
currentThread()
Этот статический метод позволяет в любом месте кода получить ссылку на объект класса Thread, представляющий текущий поток исполнения.
Результат работы такой программы будет иметь следующий вид:
Thread 0 started Thread 1 started Thread 2 started Thread 0 counts 0 Thread 1 counts 0 Thread 2 counts 0 Thread 0 counts 1 Thread 1 counts 1 Thread 2 counts 1 Thread 0 counts 2 Thread 2 counts 2 Thread 1 counts 2 Thread 2 counts 3 Thread 0 counts 3 Thread 1 counts 3 Thread 2 counts 4 Thread 0 counts 4 Thread 1 counts 4
Мы видим, что все три потока были запущены один за другим и начали проводить вычисления. Видно также, что потоки исполняются без определенного порядка, случайным образом. Тем не менее, в среднем они движутся с одной скоростью, никто не отстает и не догоняет.
Введем в программу работу с приоритетами, расставим разные значения для разных потоков и посмотрим, как это скажется на выполнении. Изменяется только метод main().
public static void main(String s[]) { // Подготовка потоков Thread t[] = new Thread[3]; for (int i=0; i<t.length; i++) { t[i]=new Thread(new ThreadTest(), "Thread "+i); t[i].setPriority(Thread.MIN_PRIORITY + (Thread.MAX_PRIORITY - Thread.MIN_PRIORITY)/t.length*i); }
// Запуск потоков for (int i=0; i<t.length; i++) { t[i].start(); System.out.println(t[i].getName()+ " started"); } }
Формула вычисления приоритетов позволяет равномерно распределить все допустимые значения для всех запускаемых потоков. На самом деле, константа минимального приоритета имеет значение 1, максимального 10, нормального 5. Так что в простых программах можно явно пользоваться этими величинами и указывать в качестве, например, пониженного приоритета значение 3.
Результатом работы будет:
Thread 0 started Thread 1 started Thread 2 started Thread 2 counts 0 Thread 2 counts 1 Thread 2 counts 2 Thread 2 counts 3 Thread 2 counts 4 Thread 0 counts 0 Thread 1 counts 0 Thread 1 counts 1 Thread 1 counts 2 Thread 1 counts 3 Thread 1 counts 4 Thread 0 counts 1 Thread 0 counts 2 Thread 0 counts 3 Thread 0 counts 4
Потоки, как и раньше, стартуют последовательно. Но затем мы видим, что чем выше приоритет, тем быстрее отрабатывает поток. Тем не менее, весьма показательно, что поток с минимальным приоритетом (Thread 0) все же получил возможность выполнить одно действие раньше, чем отработал поток с более высоким приоритетом (Thread 1). Это говорит о том, что приоритеты не делают систему однопоточной, выполняющей единовременно лишь один поток с наивысшим приоритетом. Напротив, приоритеты позволяют одновременно работать над несколькими задачами с учетом их важности.
Если увеличить параметры метода (выполнять 500000 вычислений, а не 50000, и выводить сообщение каждое 1000-е вычисление, а не 10000-е), то можно будет наглядно увидеть, что все три потока имеют возможность выполнять свои действия одновременно, просто более высокий приоритет позволяет выполнять их чаще.
Синхронизация
При многопоточной архитектуре приложения возможны ситуации, когда несколько потоков будут одновременно работать с одними и теми же данными, используя их значения и присваивая новые. В таком случае результат работы программы становится невозможно предугадать, глядя только на исходный код. Финальные значения переменных будут зависеть от случайных факторов, исходя из того, какой поток какое действие успел сделать первым или последним.
Рассмотрим пример:
Пример 12.3.
(html, txt)
В этом примере два потока исполнения одновременно обращаются к одному и тому же объекту, вызывая у него два разных метода, one() и two(). Эти методы пытаются приравнять два поля класса a и b друг другу, но в разном порядке. Учитывая, что исходные значения полей равны 1 и 2, соответственно, можно было ожидать, что после того, как потоки завершат свою работу, поля будут иметь одинаковое значение. Однако понять, какое из двух возможных значений они примут, уже невозможно. Посмотрим на результат программы:
135 864 1
Первое число показывает, сколько раз из тысячи обе переменные приняли значение 1. Второе число соответствует значению 2. Такое сильное преобладание одного из значений обусловлено последовательностью запусков потоков. Если ее изменить, то и количества случаев с 1 и 2 также меняются местами. Третье же число сообщает, что на тысячу случаев произошел один, когда поля вообще обменялись значениями!
При количестве итераций, равном 10000, были получены следующие данные, которые подтверждают сделанные выводы:
494 9498 8
А если убрать задержку перед анализом результатов, то получаемые данные радикально меняются:
0 3 997
Видимо, потоки просто не успевают отработать.
Итак, наглядно показано, сколь сильно и непредсказуемо может меняться результат работы одной и той же программы, применяющей многопоточную архитектуру. Необходимо учитывать, что в приведенном простом примере задержки создавались вручную методом Thread.sleep(). В реальных сложных системах задержки могут возникать в местах проведения сложных операций, их длина непредсказуема и оценить их последствия невозможно.
Для более глубокого понимания принципов многопоточной работы в Java рассмотрим организацию памяти в виртуальной машине для нескольких потоков.
Создание объекта класса InetAddress для локального узла
Метод getLocalHost создает объект класса InetAddress для локального узла, то есть для той рабочей станции, на которой выполняется приложение Java. Так как этот метод статический, вы можете вызывать его, ссылаясь на имя класса InetAddress:
InetAddress iaLocal; iaLocal = InetAddress.getLocalHost();
Создание объекта класса InetAddress для удаленного узла
В том случае, если вас интересует удаленный узел сети Internet или корпоративной сети Intranet, вы можете создать для него объект класса InetAddress с помощью методов getByName или getAllByName. Первый из них возвращает адрес узла, а второй - массив всех адресов IP, связанных с данным узлом. Если узел с указанным именем не существует, при выполнении методов getByName и getAllByName возникает исключение UnknownHostException.
Заметим, что методам getByName и getAllByName можно передавать не только имя узла, такое как, например, "sun.com", но и строку адреса IP в виде четырех десятичных чисел, разделенных точками.
После создания объекта класса InetAddress для локального или удаленного узла вы можете использовать другие методы этого класса.
Создание сетевых приложений
Назад Вперед
Когда мы начинали разговор про язык программирования Java, то отмечали, что он специально ориентирован на глобальные сети, такие как Internet. В этой главе мы начнем знакомство с конкретными классами Java, разработанными для сетевого программирования. На примере наших приложений вы сможете убедиться, что классы Java действительно очень удобны для создания сетевых приложений.
В этой главе мы рассмотрим два аспекта сетевого программирования. Первый из них касается доступа из приложений Java к файлам, расположенным на сервере Web, второй - создания серверных и клиентских приложений с использованием сокетов.
Напомним, что из соображений безопасности алпетам полностью запрещен доступ к локальным файлам рабочей станции, подключенной к сети. Тем не менее, аплет может работать с файлами, расположенными на серверах Web. При этом можно использовать входные и выходные потоки, описанные нами в предыдущей главе.
Для чего аплетам обращаться к файлам сервера Web?
Таким аплетам можно найти множество применений.
Представьте себе, например, что вам нужно отображать у пользователя диаграмму, исходные данные для построения которой находятся на сервере Web. Эту задачу можно решить, грубо говоря, двумя способами.
Первый заключается в том, что вы создаете расширение сервера Web в виде приложения CGI или ISAPI, которое на основании исходных данных динамически формирует графическое изображение диаграммы в виде файла GIF и посылает его пользователю.
Однако на пути решения задачи с помощью расширения сервера Web вас поджидают две неприятности. Во-первых, создать из программы красивый цветной графический файл в стандарте GIF не так-то просто - вы должны разобраться с форматом этого файла и создать все необходимые заголовки. Во-вторых, графический файл занимает много места и передается по каналам Internet достаточно медленно - средняя скорость передачи данных в Internet составляет 1 Кбайт в секунду.
В то же время файл с исходными данными может быть очень компактным. Возникает вопрос - нельзя ли передавать через Internet только исходные данные, а построение графической диаграммы выполнять на рабочей станции пользователя?
В этом заключается второй способ, который предполагает применение аплетов. Ваше приложение может, например, получать через сеть файл исходных данных, а затем на основании содержимого этого файла рисовать в своем окне цветную круговую диаграмму. Объем передаваемых данных при этом по сравнению с использованием расширения сервера Web сокращается в десятки и сотни раз.
Помимо работы с файлами, расположенными на сервере Web, мы расскажем о создании каналов между приложениями Java, работающими на различных компьютерах в сети, с использованием сокетов.
Сокеты позволяют организовать тесное взаимодействие аплетов и полноценных приложений Java, при котором аплеты могут предавать друг другу данные через сеть Internet. Это открывает широкие возможности для обработки информации по схеме клиент-сервер, причем в роли серверов здесь может выступать любой компьютер, подключенный к сети, а не только сервер Web. Каждая рабочая станция может выступать одновременно и в роли сервера, и в роли клиента.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Сравнение адресов IP
И, наконец, метод equals предназначен для сравнения адресов IP как объектов класса InetAddress.
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
Связь приложений Java с расширениями сервера Web
Назад Вперед
Итак, мы расказали вам, как приложения Java могут получать с сервера Web для обработки произвольные файлы, а также как они могут передавать данные друг другу с применением потоковых или датаграммных сокетов.
Однако наиболее впечатляющие возможности открываются, если организовать взаимодействие между приложением Java и расширением сервера Web, таким как CGI или ISAPI. В этом случае приложения или аплеты Java могли бы посылать произвольные данные расширению сервера Web для обработки, а затем получать результат этой обработки в виде файла.
Универсальный адрес ресурсов URL
Назад Вперед
Адрес IP позволяет идентифицировать узел, однако его недостаточно для идентификации ресурсов, имеющихся на этом узле, таких как работающие приложения или файлы. Причина очевидна - на узле, имеющем один адрес IP, может существовать много различных ресурсов.
Для ссылки на ресурсы сети Internet применяется так называемый универсальный адрес ресуросв URL (Universal Resource Locator). В общем виде этот адрес выглядит следующим образом:
[protocol]://host[:port][path]
Строка адреса начинаетс с протокола protocol, который должен быть использован для доступа к ресурсу. Документы HTML, например, передаются из сервера Web удаленным пользователям с помощью протокола HTTP. Файловые серверы в сети Internet работают с протоколом FTP.
Для ссылки на сетевые ресурсы через протокол HTTP используется следующая форма универсального адреса ресурсов URL:
http://host[:port][path]
Параметр host обязательный. Он должен быть указан как доменный адрес или как адрес IP (в виде четырех десятичных чисел). Например:
http://www.sun.com http://157.23.12.101
Необязательный параметр port задает номер порта для работы с сервером. По умолчанию для протокола HTTP используется порт с номером 80, однако для специализированных серверов Web это может быть и не так.
Номер порта идентифицирует программу, работающую в узле сети TCP/IP и взаимодействующую с другими программами, расположенными на том же или на другом узле сети. Если вы разрабатываете программу, передающую данные через сеть TCP/IP с использованием, например, интерфейса сокетов Windows Sockets, то при создании канала связи с уделенным компьютером вы должны указать не только адрес IP, но и номер порта, который будет использован для передачи данных.
Ниже мы показали, как нужно указывать в адресе URL номер порта:
http://www.myspecial.srv/:82
Теперь займемся параметром path, определяющем путь к объекту.
Обычно любой сервер Web или FTP имеет корневой каталог, в котором расположены подкаталоги. Как в корневом каталоге, так и в подкаталогах сервера Web могут находиться документы HTML, двоичные файлы, файлы с графическими изображениями, звуковые и видео-файлы, расширения сервера в виде программ CGI или библиотек динамической компоновки, дополняющих возможности сервера.
Если в качестве адреса URL указать навигатору только доменное имя сервера, сервер перешлет навигатору свою главную страницу. Имя файла этой страницы зависит от сервера. Большинство серверов на базе операционной системы UNIX посылают по умолчанию файл документа с именем index.html. Другие серверы Web могут использовать для этой цели имя default.htm или какое-нибудь еще, определенное при установке сервера, например, home.html или home.htm.
Для ссылки на конкретный документ HTML или на файл любого другого объекта необходимо указать в адресе URL его путь, включающий имя файла, например:
http://www.glasnet.ru/~frolov/index.html http://www.dials.ccas.ru/frolov/home.htm
Корневой каталог сервера Web обозначается символом /. В спецификации протокола HTTP сказано, что если путь не задан, то используется корневой каталог.
Назад Вперед

О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все
До сих пор во всех
До сих пор во всех рассматриваемых примерах подразумевалось, что в один момент времени исполняется лишь одно выражение или действие. Однако начиная с самых первых версий, виртуальные машины Java поддерживают многопоточность, т.е. поддержку нескольких потоков исполнения (threads) одновременно.
В данной лекции сначала рассматриваются преимущества такого подхода, способы реализации и возможные недостатки.
Затем описываются базовые классы Java, которые позволяют запускать потоки исполнения и управлять ими. При одновременном обращении нескольких потоков к одним и тем же данным может возникнуть ситуация, когда результат программы будет зависеть от случайных факторов, таких как временное чередование исполнения операций несколькими потоками. В такой ситуации становятся необходимым механизмы синхронизации, обеспечивающие последовательный, или монопольный, доступ. В Java этой цели служит ключевое слово synchronized. Предварительно будет рассмотрен подход к организации хранения данных в виртуальной машине.
В заключение рассматриваются методы wait(), notify(), notifyAll() класса Object.
Взаимодействие приложения Java и расширения сервера Web
Методика организации взаимодействия приложений Java и расширений сервера Web основана на применении классов URL и URLConnection.
Приложение Java, желающее работать с расширением сервера Web, создает объект класса URL для программы расширения (то есть для исполняемого модуля расширения CGI или библиотеки динамической компоновки DLL расширения ISAPI).
Далее приложение получает ссылку на канал передачи данных с этим расширением как объекта класса URLConnection. Затем, пользуясь методами getOutputStream и getInputStream из класса URLConnection, приложение создает с расширением сервера Web выходной и входной канал передачи данных.
Когда данные передаются приложением в выходной канал, созданный подобным образом, он попадает в стандартный поток ввода приложения CGI, как будто бы данные пришли методом POST из формы, определенной в документе HTML.
Обработав полученные данные, расширение CGI записывает их в свой стандартный выходной поток, после чего эти данные становятся доступны приложению Java через входной поток, открытый методом getInputStream класса URLConnection.
На рис. 1 показаны потоки данных для описанной выше схемы взаимодействия приложения Java и расширения сервреа Web с интерфейсом CGI.

Рис. 1. Взаимодействие приложения Java с расширением сервера Web на базе интерфейса CGI
Расширения ISAPI работают аналогично, однако они получают данные не из стандратного входного потока, а с помощью вызова специально предназначенной для этого функции интерфейса ISAPI. Вместо стандартного потока вывода также применяется специальная функция.
В этой лекции были рассмотрены
В этой лекции были рассмотрены принципы построения многопоточного приложения. В начале разбирались достоинства и недостатки такой архитектуры – как правило ОС не выделяет отдельный процессор под каждый процесс, а значит применяется процедура time slicing. Было выделено три признака, указывающие на целесообразность запуска нескольких потоков в рамках программы.
Основу работы с потоками в Java составляют интерфейс Runnable и класс Thread. С их помощью можно запускать и останавливать потоки, менять их свойства, среди которых основные: приоритет и свойство daemon. Главная проблема, возникающая в таких программах - одновременный доступ нескольких потоков к одним и тем же данным, в первую очередь -– к полям объектов. Для понимания, как в Java решается эта задача, был сделан краткий обзор по организации памяти в JVM, работы с переменными и блокировками. Блокировки, несмотря на название, сами по себе не ограничивают доступ к переменной. Программист использует их через ключевое слово synchronized, которое может быть указано в сигнатуре метода или в начале блока. В результате выполнение не будет продолжено, пока блокировка не освободится.
Новый механизм порождает новую проблему - взаимные блокировки (deadlock), к которой программист всегда должен быть готов, тем более, что Java не имеет встроенных средств для определения такой ситуации. В лекции разбирался пример, как организовать работу программы без "зависания" ожидающих потоков.
В завершение рассматривались специализированные методы базового класса Object, которые также позволяют управлять последовательностью работы потоков.
Завершение работы сервера и клиента
После завершения передачи данных вы должны закрыть потоки, вызвав метод close:
is.close(); os.close();
Когда канал передачи данных больше не нужен, сервер и клиент должны закрыть сокет, вызвав метод close, определенный в классе Socket:
s.close();
Серверное приложение, кроме того, должно закрыть соединение, вызвав метод close для объекта класса ServerSocket:
ss.close();
Назад Вперед

Контакты
О компании
Новости
Вакансии
Правовые аспекты
Условия использования
Торговые марки
Copyright 1994-2005 Sun Microsystems, Inc.

printmenus();
Рабочие станции и тонкие клиенты
Серверы
Системы хранения данных
Посмотреть все
Java 2 Standard Edition
Developer Tools
Top Downloads
New Downloads
Патчи и обновления
Посмотреть все
Истории успеха
The Sun Grid
Партнерские программы
Посмотреть все
Программы SunSpectrum
Консалтинг
Услуги инсталляции
Поддержка ПО
Посмотреть все
Сертификация
Авторизованные учебные центры
Посмотреть все
События
Lab Downloads
Посмотреть все