Базовые классы для работы с файлами и потоками
Количество классов, созданных для работы с файлами, достаточно велико, чтобы привести начинающего программиста в растерянность. Прежде чем мы займемся конкретными классами и приведем примеры приложений, работающих с потоками и файлами, рассмотрим иерархию классов, предназначенных для орагнизации ввода и вывода.
Все основные классы, интересующие нас в этой главе, произошли от класса Object (рис. 1).
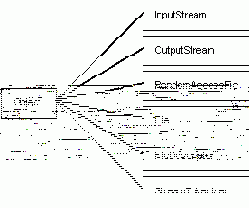
Рис. 1. Основные классы для работы с файлами и потоками
Добавление буферизации
А что, если нам нужен не простой выходной поток, а буферизованный?
Здесь нам может помочь класс BufferedOutputStream. Вот два конструктора, предусмотренных в этом классе:
public BufferedOutputStream( OutputStream out); public BufferedOutputStream( OutputStream out, int size);
Первый из них создает буферизованный выходной поток на базе потока класса OutputStream, а второй делает то же самое, но дополнительно позволяет указать размер буфера в байтах.
Если вам нужно создать выходной буферизованный поток для записи форматированных данных, создание потока выполняется в три приема:
создается поток, связанный с файлом, как объект класса FileOutputStream;
ссылка на этот поток передается конструктору класса BufferedOutputStream, в результате чего создается буферизованный поток, связанный с файлом;
ссылка на буферизованный поток, созданный на предыдущем шаге, передается конструктору класса DataOutputStream, который и создает нужный поток
Вот фрагмент исходного текста программы, который создает выходной буферизованный поток для записи форматированных данных в файл с именем output.txt:
DataOutputStream OutStream; OutStream = new DataOutputStream( new BufferedOutputStream( new FileOutputStream("output.txt")));
Аналогичным образом создается входной буферизованный поток для чтения форматированных данных из того же файла:
DataInputStream InStream; InStream = new DataInputStream( new BufferedInputStream( new FileInputStream("output.txt")));
Исходный текст приложения
Исходный текст приложения StreamToken представлен в листинге 1.
Листинг 1. Файл StreamToken.java
import java.io.*;
public class StreamToken { public static void main(String args[]) { DataOutputStream OutStream; DataInputStream InStream;
byte bKbdInput[] = new byte[256]; String sOut;
try { System.out.println( "Enter string to parse...");
System.in.read(bKbdInput);
sOut = new String(bKbdInput, 0);
OutStream = new DataOutputStream( new BufferedOutputStream( new FileOutputStream( "output.txt")));
OutStream.writeBytes(sOut); OutStream.close();
InStream = new DataInputStream( new BufferedInputStream( new FileInputStream( "output.txt")));
TokenizerOfStream tos = new TokenizerOfStream();
tos.TokenizeIt(InStream); InStream.close();
System.out.println( "Press <Enter> to terminate..."); System.in.read(bKbdInput); } catch(Exception ioe) { System.out.println(ioe.toString()); } } }
class TokenizerOfStream { public void TokenizeIt(InputStream is) { StreamTokenizer stok; String str;
try { stok = new StreamTokenizer(is); stok.slashSlashComments(true);
stok.ordinaryChar('.');
while(stok.nextToken() != StreamTokenizer.TT_EOF) { switch(stok.ttype) { case StreamTokenizer.TT_WORD: { str = new String( "\nTT_WORD >" + stok.sval); break; }
case StreamTokenizer.TT_NUMBER: { str = "\nTT_NUMBER >" + Double.toString(stok.nval); break; }
case StreamTokenizer.TT_EOL: { str = new String("> End of line"); break; }
default: { if((char)stok.ttype == '"') { str = new String( "\nTT_WORD >" + stok.sval); }
else str = "> " + String.valueOf( (char)stok.ttype); } }
System.out.println(str); } } catch(Exception ioe) { System.out.println(ioe.toString()); } } }
Исходный текст приложения DirectFile
Исходный текст приложения DirectFile представлен в листинге 2.
Листинг 2. Файл DirectFile.java
import java.awt.*; import java.io.*; import java.util.*;
public class DirectFile { public static void main(String args[]) { MainFrameWnd frame = new MainFrameWnd("MenuApp"); frame.setSize( frame.getInsets().left + frame.getInsets().right + 320, frame.getInsets().top + frame.getInsets().bottom + 240); frame.show(); } }
class MainFrameWnd extends Frame { MenuBar mbMainMenuBar; Menu mnFile; Menu mnHelp; boolean fDBEmpty = true;
public MainFrameWnd(String sTitle) { super(sTitle);
setSize(400, 200); setBackground(Color.yellow); setForeground(Color.black);
setLayout(new FlowLayout());
mbMainMenuBar = new MenuBar(); mnFile = new Menu("File");
mnFile.add("New..."); mnFile.add("View records..."); mnFile.add("-"); mnFile.add("Exit");
mnHelp = new Menu("Help");
mnHelp.add("Content"); mnHelp.add("-"); mnHelp.add("About");
mbMainMenuBar.add(mnFile); mbMainMenuBar.add(mnHelp);
setMenuBar(mbMainMenuBar); }
public void paint(Graphics g) { g.setFont(new Font("Helvetica", Font.PLAIN, 12)); g.drawString("Frame window", 10, 70); super.paint(g); }
public boolean handleEvent(Event evt) { if(evt.id == Event.WINDOW_DESTROY) { setVisible(false); System.exit(0); return true; } else return super.handleEvent(evt); }
public boolean action(Event evt, Object obj) { MenuItem mnItem; if(evt.target instanceof MenuItem) { mnItem = (MenuItem)evt.target;
if(obj.equals("Exit")) { System.exit(0); }
else if(obj.equals("New...")) { if(fDBEmpty) { SimpleDBMS db = new SimpleDBMS( "dbtest.idx", "dbtest.dat");
db.AddRecord("Ivanov", 1000); db.AddRecord("Petrov", 2000); db.AddRecord("Sidoroff", 3000);
db.close();
fDBEmpty = false;
MessageBox mbox; mbox = new MessageBox( "Database created", this, "Information", true); mbox.show(); } }
else if(obj.equals("View records...")) { SimpleDBMS db = new SimpleDBMS( "dbtest.idx", "dbtest.dat"); String szRecords;
szRecords = db.GetRecordByNumber(0) + db.GetRecordByNumber(1) + db.GetRecordByNumber(2);
db.close();
MessageBox mbox; mbox = new MessageBox(szRecords, this, "Database records", true); mbox.show(); }
else if(obj.equals("Content")) { MessageBox mbox; mbox = new MessageBox( "Item Content selected", this, "Dialog from Frame", true); mbox.show(); }
else if(obj.equals("About")) { MessageBox mbox; mbox = new MessageBox( "Item About selected", this, "Dialog from Frame", true); mbox.show(); } else return false; return true; } return false; } }
class MessageBox extends Dialog { Label lbMsg; Button btnOK;
public MessageBox(String sMsg, Frame parent, String sTitle, boolean modal) { super(parent, sTitle, modal); resize(300, 100); setLayout(new GridLayout(2, 1)); lbMsg = new Label(sMsg, Label.CENTER); add(lbMsg); btnOK = new Button("OK"); add(btnOK); }
public boolean handleEvent(Event evt) { if(evt.id == Event.WINDOW_DESTROY) { dispose(); return true; } else return super.handleEvent(evt); }
public boolean action(Event evt, Object obj) { Button btn; if(evt.target instanceof Button) { btn = (Button)evt.target;
if(evt.target.equals(btnOK)) { dispose(); } else return false; return true; } return false; } }
class SimpleDBMS { RandomAccessFile idx; RandomAccessFile dat;
long idxFilePointer = 0;
public SimpleDBMS(String IndexFile, String DataFile) { try { idx = new RandomAccessFile( IndexFile, "rw"); dat = new RandomAccessFile( DataFile, "rw"); } catch(Exception ioe) { System.out.println(ioe.toString()); } }
public void close() { try { idx.close(); dat.close(); } catch(Exception ioe) { System.out.println(ioe.toString()); } }
public void AddRecord(String name, int account) { try { idx.seek(idx.length()); dat.seek(dat.length());
idxFilePointer = dat.getFilePointer();
idx.writeLong(idxFilePointer);
dat.writeBytes(name+ "\r\n"); dat.writeInt(account); } catch(Exception ioe) { System.out.println(ioe.toString()); } }
public String GetRecordByNumber(long nRec) { String sRecord = "<empty>";
try { Integer account; String str = null;
idx.seek(nRec * 8); idxFilePointer = idx.readLong(); dat.seek(idxFilePointer);
str = dat.readLine(); account = new Integer(dat.readInt());
sRecord = new String("> " + account + ", " + str); } catch(Exception ioe) { System.out.println(ioe.toString()); } return sRecord; } }
Исключения при создании потоков
При создании потоков на базе классов FileOutputStream и FileInputStream могут возникать исключения FileNotFoundException, SecurityException, IOException.
Исключение FileNotFoundException возникает при попытке открыть входной поток данных для несуществующего файла, то есть когда файл не найден.
Исключение SecurityException возникает при попытке открыть файл, для которого запрещен доступ. Например, если файл можно только читать, а он открывается для записи, возникнет исключение SecurityException.
Если файл не может быть открыт для записи по каким-либо другим причинам, возникает исключение IOException.
Класс BufferedInputStream
Буферизация операций ввода и вывода в большинстве случаев значительно ускоряет работу приложений, так как при ее использовании сокращается количество обращений к системе для обмена данными с внешними устройствами.
Класс BufferedInputStream может быть использован приложениями Java для организации буферизованных потоков ввода. Заметим, что конструкторы этого класса в качестве параметра получают ссылку на объект класса InputStream. Таким образом, вы не можете просто создать объект класса BufferedInputStream, не создав перед этим объекта класса InputStream. Подробности мы обсудим позже.
Класс BufferedOutputStream
Класс BufferedOutputStream предназначен для создания буферизованных потоков вывода. Как мы уже говорили, буферизация ускоряет работу приложений с потоками.
Класс ByteArrayInputStream
При необходимости вы можете создать в приложениях Java входной поток данных не на базе локального или удаленного файла, а на базе массива, расположенного в оперативной памяти. Класс ByteArrayInputStream предназначен именно для этого - вы передаете конструктору класса ссылку на массив, и получаете входной поток данных, связанный с этим массивом.
Потоки в оперативной памяти могут быть использованы для временного хранения данных. Заметим, что так как аплеты Java не могут обращаться к локальным файлам, для создания временных файлов можно использовать потоки в оперативной памяти на базе класса ByteArrayInputStream. Другую возможность предоставляет класс StringBufferInputStream, рассмотренный ниже.
С помощью класса ByteArrayInputStream вы можете создать входной поток на базе массива байт, расположенного в оперативной памяти. В этом классе определено два конструктора:
public ByteArrayInputStream(byte buf[]); public ByteArrayInputStream( byte buf[], int offset, int length);
Первый конструктор получает через единственный параметр ссылку на массив, который будет использован для создания входного потока. Второй позволяет дополнительно указать смещение offset и размер области памяти length, которая будет использована для создания потока.
Вот несколько методов, определенных в классе ByteArrayInputStream:
public int available(); public int read(); public int read(byte b[],int off, int len); public void reset(); public long skip(long n);
Наиболее интересен из них метод available, с помощью которого можно определить, сколько байт имеется во входном потоке для чтения.
Обычно класс ByteArrayInputStream используется вместе с классом DataInputStream, что позволяет организовать форматный ввод данных.
Класс ByteArrayOutputStream
С помощью класса ByteArrayOutputStream можно создать поток вывода в оперативной памяти.
Класс ByteArrayOutputStream создан на базе класса OutputStream. В нем имеется два конструктора, прототипы которых представлены ниже:
public ByteArrayOutputStream(); public ByteArrayOutputStream( int size);
Первый из этих конструкторов создает выходной поток в оперативной памяти с начальным размером буфера, равным 32 байта. Второй позволяет указать необходимый размер буфера.
В классе ByteArrayOutputStream определено несколько достаточно полезных методов. Вот некоторые из них:
public void reset(); public int size(); public byte[] toByteArray(); public void writeTo(OutputStream out);
Метод reset сбрасывает счетчик байт, записанных в выходной поток. Если данные, записанные в поток вам больше не нужны, вы можете вызвать этот метод и использовать память, выделенную для потока, для записи других данных.
С помощью метода size можно определить количество байт данных, записанных в поток.
Метод toByteArray позволяет скопировать данные, записанные в поток, в массив байт. Этот метод возвращает адрес созданного для этой цели массива.
С помощью метода writeTo вы можете скопировать содержимое данного потока в другой выходной поток, ссылка на который передается методу через параметр.
Для выполнения форматированного вывода в поток, вы должны создать поток на базе класса DataOutputStream, передав соответствующему конструктору ссылку на поток класса ByteArrayOutputStream.
Класс DataInputStream
Составляя программы на языке программирования С, вы были вынуждены работать с потоками на уровне байт или, в лучшем случае, на уровне текстовых строк. Однако часто возникает необходимость записывать в потоки данных и читать оттуда объекты других типов, например, целые числа и числа типа double, числа в формате с плавающей десятичной точкой, массивы байт и символов и так далее.
Класс DataInputStream содержит методы, позволяющие извлекать из входного потока данные в перечисленных выше форматах или, как говорят, выполнять форматированный ввод данных. Он также реализует интерфейс DataInput, служащий для этой же цели. Поэтому класс DataInputStream очень удобен и часто применяется в приложениях для работы с потоками ввода.
Так же как и конструктор класса BufferedInputStream, конструктор класса DataInputStream должен получить через свои параметр ссылку на объект класса InputStream.
Класс DataOutputStream
С помощью класса DataOutputStream приложения Java могут выполнять форматированный вывод данных. Для ввода форматированных данных вы должны создать входной поток с использованием класса DataInputStream, о котором мы уже говорили. Класс DataOutputStream реализует интерфейс DataOutput.
Класс File
Класс File предназначен для работы с оглавлениями каталогов. С помощью этого класса можно получить список файлов и каталогов, расположенных в заданном каталоге, создать или удалить каталог, переименовать файл или каталог, а также выполнить некоторые другие операции.
Класс FileDescriptor
C помощью класса FileDescriptor вы можете проверить идентификатор открытого файла.
Класс FileInputStream
Этот класс позволяет создать поток ввода на базе класса File или FileDescriptor.
Класс FileOutputStream
Этот класс позволяет создать поток вывода на базе класса File или FileDescriptor.
Класс FilterInputStream
Класс FilterInputStream, который происходит непосредственно от класса InputStream, является абстрактным классом, на базе которого созданы классы BufferedInputStream, DataInputStream, LineNumberInputStream и PushBackInputStream. Непосредственно класс FilterInputStream не используется в приложениях Java, так как, во-первых, он является абстрактным и предназначен для переопределения методов базового класса InputStream, а во-вторых, наиболее полезные методы для работы с потоками ввода имеются в классах, созданных на базе класса FilterInputStream.
Класс FilterOutputStream
Абстрактный класс FilterOutputStream служит прослойкой между классом OutputStream и классами BufferedOutputStream, DataOutputStream, а также PrintStream. Он выполняет роль, аналогичную роли рассмотренного ранее класса FilterIntputStream.
Класс InputStream
Класс InputStream является базовым для большого количества классов, на основе которых создаются потоки ввода. Именно производные классы применяются программистами, так как в них имеются намного более мощные методы, чем в классе InputStream. Эти методы позволяют работать с потоком ввода не на уровне отдельных байт, а на уровне объектов различных классов, например, класса String и других.
Класс LineNumberInputStream
С помощью класса LineNumberInputStream вы можете работать с текстовыми потоками, состоящими из отдельных строк, разделенных символами возврата каретки \r и перехода на следующую строку \n. Методы этого класса позволяют следить за нумерацией строк в таких потоках.
Класс OutputStream
Аналогично, класс OutputStream служит в качестве базового для различных классов, имеющих отношение к потокам вывода.
Класс PipedInputStream
С помощью классов PipedInputStream и PipedOutputStream можно организовать двухстороннюю передачу данных между двумя одновременно работающими задачами мультизадачного аплета.
Класс PipedOutputStream
Как мы уже говорили, классы PipedInputStream и PipedOutputStream предназначены для организации двухсторонней передачи данных между двумя одновременно работающими задачами мультизадачного аплета.
Класс PrintStream
Потоки, созданные с использованием класса PrintStream, предназначены для форматного вывода данных различных типов с целью их визуального представления в виде текстовой строки. Аналогичная операция в языке программирования С выполнялась функцией printf.
Класс PushBackInputStream
Класс PushBackInputStream позволяет возвратить в поток ввода только что прочитанный оттуда символ, с тем чтобы после этого данный символ можно было прочитать снова.
Класс RandomAccesFile
С помощью класса RandomAccesFile можно организовать работу с файлами в режиме прямого доступа, когда программа указывает смещение и размер блока данных, над которым выполняется операция ввода или вывода. Заметим, кстати, что классы InputStream и OutputStream также можно использовать для обращения к файлам в режиме прямого доступа.
Класс SequenceInputStream
Класс SequenceInputStream позволяет объединить несколько входных потоков в один поток. Если в процессе чтения будет достигнут конец первого потока такого объединения, в дальнейшем чтение будет выполняться из второго потока и так далее.
Класс SimpleDBMS
Рассмотрим теперь класс SimpleDBMS.
В этом классе определено три поля с именами idx, dat и idxFilePointer, а также три метода.
Класс StreamTokenizer
Очень удобен класс StreamTokenizer. Он позволяет организовать выделение из входного потока данных элементов, отделенных друг от друга заданными разделителями, такими, например, как запятая, пробел, символы возврата каретки и перевода строки.
Класс StreamTokenizer для разбора входных потоков
Если вы создаете приложение, предназначенное для обработки текстов (например, транслятор или просто разборщик файла конфигурации, содержащего значения различных параметров), вам может пригодиться класс StreamTokenizer. Создав объект этого класса для входного потока, вы можете легко решить задачу выделения из этого потока отдельных слов, символов, чисел и строк комментариев.
Класс StringBufferInputStream
Класс StringBufferInputStream позволяет создавать потоки ввода на базе строк класса String, используя при этом только младшие байты хранящихся в такой строке символов. Этот класс может служить дополнением для класса ByteArrayInputStream, который также предназначен для создания потоков на базе данных из оперативной памяти.
Класс StringBufferInputStream предназначен для создания входного потока на базе текстовой строки класса String. Ссылка на эту строку передается конструктору класса StringBufferInputStream через параметр:
public StringBufferInputStream(String s);
В классе StringBufferInputStream определены те же методы, что и в только что рассмотренном классе ByteArrayInputStream. Для более удобной работы вы, вероятно, создадите на базе потока класса StringBufferInputStream поток класса DataInputStream.
Класс StringTokenizer
Рассказывая о классе StreamTokenizer, нельзя не упомянуть о другом классе с похожим названием и назначением, а именно о классе StringTokenizer.
Определение этого класса достаточно компактно.
Конструкторы
public StringTokenizer(String str); public StringTokenizer(String str, String delim); public StringTokenizer(String str, String delim, boolean returnTokens);
Методы
public String nextToken(); public String nextToken(String delim); public int countTokenss(); public boolean hasMoreElements(); public boolean hasMoreTokenss(); public Object nextElement(); }
Класс StringTokenizer не имеет никакого отношения к потокам, так как предназначен для выделения отдельных элементов из строк типа String.
Конструкторы класса получают в качетсве первого параметра str ссылку на разбираемую строку. Второй параметр delim, если он есть, задает разделители, с испльзованием которых в строке будут выделяться элементы. Параметр returnTokens определяет, надо ли вовзвращать обнаруженные разделители как элементы разбираемой строки.
Рассмотрим кратко методы класса StringTokenizer.
Для разбора строки приложение должно организовать цикл, вызывая в нем метод nextToken. Условием завершения цикла может быть либо возникновение исключения NoSuchElementException, либо возврат значения false методами hasMoreElements или hasMoreTokens.
Метод countTokens позволяет определить, сколько раз был вызван метод nextToken перед возникновением исключения NoSuchElementException.
Классы Java для работы с потоками
Программист, создающий автономное приложение Java, может работать с потоками нескольких типов:
стандартные потоки ввода и вывода;
потоки, связанные с локальными файлами;
потоки, связанные с файлами в оперативной памяти;
потоки, связанные с удаленными файлами
Рассмотрим кратко классы, связанные с потоками.
Конструктор класса SimpleDBMS
Конструктор класса SimpleDBMS выглядит достаточно просто. Все, что он делает, - это создает два объекта класса RandomAccessFile, соответственно, для индекса и данных:
idx = new RandomAccessFile(IndexFile, "rw"); dat = new RandomAccessFile(DataFile, "rw");
Так как в качестве второго параметра конструктору класа RandomAccessFile передается строка "rw", файлы открываются и для чтения, и для записи.
Конструктор класса StreamTokenizer
Для создание объектов класса StreamTokenizer предусмотрен всего один конструктор:
public StreamTokenizer(InputStream istream);
В качестве параметра этому конструктору необходимо передать ссылку на заранее созданный входной поток.
Метод AddRecord
Метод AddRecord добавляет новую запись в конец файла данных, а смещение этой записи - в конец файла индекса. Поэтому перед началом своей работы текущая позиция обоих указанных файлов устанавливается на конец файла.
Для установки мы применили метод seek из класса RandomAccessFile, передав ему в качестве параметра значение длины файла в байтах, определенное при помощи метода length из того же класса:
idx.seek(idx.length()); dat.seek(dat.length());
Перед тем как добавлять новую запись в файл данных, метод AddRecord определяет текущую позицию в файле данных (в данном случае это позиция конца файла) и записывает эту позицию в файл индекса:
idxFilePointer = dat.getFilePointer(); idx.writeLong(idxFilePointer);
Далее метод AddRecord выполняет сохранение полей записи в файле данных. Для записи строки вызывается метод writeBytes, а для записи численного значения типа int - метод writeInt:
dat.writeBytes(name + "\r\n"); dat.writeInt(account);
Обратите внимение, что к строке мы добавляем символы возврата каретки и перевода строки. Это сделано исключительно для того чтобы обозначить конец строки текстового поля.
Метод close
Метод close закрывает файлы индекса и данных, вызывая метод close из класса RandomAccessFile:
idx.close(); dat.close();
Метод GetRecordByNumber
Метод GetRecordByNumber позволяет извлечь произвольную запись из файла данных по ее порядковому номеру.
Напомним, что смещения всех записей хранятся в файле индексов и имеют одинаковую длину 8 байт. Пользуясь этим, метод GetRecordByNumber вычисляет смещение в файле индекса простым умножением порядкового номера записи на длину переменной типа long, то есть на 8 байт, а затем выполняет позиционирование:
idx.seek(nRec * 8);
После этого метод GetRecordByNumber извлекает из файла индексов смещение нужной записи в файле данных, вызывая для этого метод readLong, а затем выполняет позиционирование в файле данных:
idxFilePointer = idx.readLong(); dat.seek(idxFilePointer);
Поля записи читаются из файла данных в два приема. Вначале читается строка текстового поля, а затем - численное значение, для чего вызываются, соответственно, методы readLine и readInt:
str = dat.readLine(); account = new Integer(dat.readInt());
Полученные значения полей объединяются в текстовой строке и записываются в переменную sRecord:
sRecord = new String("> " + account + ", " + str);
Содержимое этой переменной метод GetRecordByNumber возвращает в качестве извлеченной строки записи базы данных.
Методы для чтения и записи форматированных данных
Вместо того чтобы записывать в потоки и читать оттуда отдельные байты или массивы байт, программисты обычно предпочитают пользоваться намного более удобными методами классов DataOutputStream и DataInputStream, допускающими форматированный ввод и вывод данных.
Вот, например, какой набор методов можно использовать для записи форматированных данных в поток класса DataOutputStream:
public final void writeBoolean(boolean v); public final void writeByte(int v); public final void writeBytes(String s); public final void writeChar(int v); public final void writeChars(String s); public final void writeDouble(double v); public final void writeFloat(float v); public final void writeInt(int v); public final void writeLong(long v); public final void writeShort(int v); public final void writeUTF(String s);
Хотя имена методов говорят сами за себя, сделаем замечания относительно применения некоторых из них.
Метод writeByte записывает в поток один байт. Это младший байт слова, которое передается методу через параметр v. В отличие от метода writeByte, метод writeChar записывает в поток двухбайтовое символьное значение (напомним, что в Java символы хранятся с использованием кодировки Unicode и занимают два байта).
Если вам нужно записать в выходной поток текстовую строку, то это можно сделать с помощью методов writeBytes, writeChars или writeUTF. Первый из этих методов записывает в выходной поток только младшие байты символов, а второй - двухбайтовые символы в кодировке Unicode. Метод writeUTF предназначен для записи строки в машинно-независимой кодировке UTF-8.
Все перечисленные выше методы в случае возникновения ошибки создают исключение IOException, которое вы должны обработать.
В классе DataInputStream определены следующие методы, предназначенные для чтения форматированных данных из входного потока:
public final boolean readBoolean(); public final byte readByte(); public final char readChar(); public final double readDouble(); public final float readFloat(); public final void readFully(byte b[]); public final void readFully(byte b[], int off, int len); public final int readInt(); public final String readLine(); public final long readLong(); public final short readShort(); public final int readUnsignedByte(); public final int readUnsignedShort(); public final String readUTF(); public final static String readUTF( DataInput in); public final int skipBytes(int n);
Обратите внимание, что среди этих методов нет тех, что специально предназначены для четния данных, записанных из строк методами writeBytes и writeChars класса DataOutputStream.
Тем не менее, если входной поток состоит из отдельных строк, разделенных символами возврата каретки и перевода строки, то такие строки можно получить методом readLine. Вы также можете воспользоваться методом readFully, который заполняет прочитанными данными массив байт. Этот массив потом будет нетрудно преобразовать в строку типа String, так как в классе String предусмотрен соответствующий конструктор.
Для чтения строк, записанных методом writeUTF вы должны обязательно пользоваться методом readUTF.
Метод skipBytes позволяет пропустить из входного потока заданное количество байт.
Методы класса DataInputStream, предназначенные для чтения данных, могут создавать исключения IOException и EOFException. Первое из них возникает в случае ошибки, а второе - при достижении конца входного потока в процессе чтения.
Методы для настройки параметров разборщика
Ниже мы привели прототипы методов, предназначенных для настройки параметров разборщика:
public void commentChar(int ch); public void slashSlashComments(boolean flag); public void slashStarComments(boolean flag); public void quoteChar(int ch);
public void eolIsSignificant(boolean flag); public void lowerCaseMode(boolean fl);
public void ordinaryChar(int ch); public void ordinaryChars(int low,int hi); public void resetSyntax();
public void parseNumbers(); public void whitespaceChars(int low, int hi); public void wordChars(int low, int hi);
Несколько методов определяют, будет ли разборщик выделять во входном потоке строки комментария и если будет, то какми образом.
С помощью метода commentChar вы можете указать символ комментария. Если в строке входного потока попадется такой символ, то он и все следующие за ним до конца текущей строки символы будут проигнорированы.
Методы SlashSlashComments и slashStarComments позволяют указать, что для входного текста используются разделители комментариев в виде двойного символа '/' и '/* … */', соответственно. Это соответствует способу указания комментариев в программах, составленных на языках программирования С++ и С. Для включения режима выделения комментариев обоим методам в качетстве параметра необходимо передать значение true, а для отключения - false.
Метод quoteChar позволяет задать символ, который будет использован в качестве кавычек. Когда при разборе потока встречаются слова, взятые в кавычки, они возвращаются программе разбора без кавычек.
Если передать методу eolIsSignificant значение true, разделители строк будут интерпретироваться как отдельные элементы. Если же этому методу передать значение false, разделители строк будут использоваться аналогично пробелам для разделения элементов входного потока.
Метод lowerCaseMode позволяет включить режим, при котором все выделенные элементы будут перекодированы в строчные символы.
Методы ordinaryChar и ordinaryChars позволяют указать символы, которые должны интерпретироваться как обычные, из которых составляются слова или цифры. Например, если передать методу ordinaryChar символ '.', то слово java.io будет восприниматься как один элемент. Если же этого не сделать, то разборщик выделит из него три элемента - слово java, точку '.' и слово io. Метод ordinaryChars позволяет указать диапазон значений символов, которые должны интерпретироваться как обычные.
С помощью метода resetSyntax вы можете указать, что все символы будут рассматриваться, как обычные.
Метод parseNumbers включает режим разбора чисел, при котором распознаются и преобразуются числа в формате с плавающей десятичной точкой.
Метод whitespaceChars задает диапазон значений для символов-разделителей отдельных слов в потоке.
Метод wordChars позволяет указать символы, которые являются составными частями слов.
Методы для разбора входного потока
После того как вы создали разборщик входного потока на базе класса StreamTokenizer и установили его параметры с помощью описанных выше методов, можно приступать собственно к разборке потока. Обычно для этого организуется цикл, в котором вызывается метод nextToken:
public int nextToken();
Этот метод может вернуть одно из следующих значений:
| Значение | Описание |
| TT_WORDTT_WORD | Из потока было извлечено слово |
| TT_NUMBERTT_NUMBER | Из потока было извлечено численное значение |
| TT_EOLTT_EOL | Обнаружен конец строки. Это значение возвращается только в том случае, если при настройке параметров разборщика был вызван метод eolIsSignficant |
| TT_EOFTT_EOF | Обнаружен конец файла |
Если метод nextToken вернул значение TT_EOF, следует завершить цикл разбора входного потока.
Как извлечь считанные элементы потока?
В классе StreamTokenizer определено три поля:
public String sval; public double nval; public int ttype;
Если метод nextToken вернул значение TT_WORD, в поле sval содержится извлеченный элемент в виде текстовой строки. В том случае, когда из входного потока было извлечено числовое значение, оно будет храниться в поле nval типа double. Обычные символы записываются в поле ttype.
Заметим, что если в потоке обнаружены слова, взятые в кавычки, то символ кавычки записывается в поле ttype, а слова - в поле sval. По умолчанию используется символ кавычек '"', однако с помощью метода quoteChar вы можете задать любой другой символ.
При необходимости в процессе разбора вы можете определить номер текущей строки, вызвав для этого метод lineno:
public int lineno();
После вызова метода pushBack следующий вызов метода nextToken приведет к тому, что в поле ttype будет записано текущее значение, а содержимое полей sval и nval не изменится. Прототип метода pushBack приведен ниже:
public void pushBack();
Метод toString возвращает текстовую строку, представляющую текущий элемент, выделенный из потока:
public String toString();
Методы класса StreamTokenizer
Для настройки параметров разборщика StreamTokenizer и получения отдельных элементов входного потока вы должны пользоваться методами, определенными в классе StreamTokenizer. Рассмотрим самые важние из них.
Описание исходного текста приложения
После ввода строки с клавиатуры и записи ее в файл через поток наше приложение создает входной буферизованный поток, как это показано ниже:
InStream = new DataInputStream( new BufferedInputStream( new FileInputStream("output.txt")));
Далее для этого потока создается разборщик, который оформлен в отдельном классе TokenizerOfStream, определенном в нашем приложении:
TokenizerOfStream tos = new TokenizerOfStream();
Вслед за этим мы вызываем метод TokenizeIt, определенный в классе TokenizerOfStream, передавая ему в качестве параметра ссылку на входной поток:
tos.TokenizeIt(InStream);
Метод TokenizeIt выполняет разбор входного потока, отображая результаты разбора на консоли. После выполнения разбора входной поток закрывается методом close:
InStream.close();
Самое интересное в нашем приложении связано, очевидно, с классом TokenizerOfStream, поэтому перейдем к его описанию.
В этом классе определен только один метод TokenizeIt:
public void TokenizeIt(InputStream is) { . . . }
Получая в качестве параметра ссылку на входной поток, он прежде всего создает для него разборщик класса StreamTokenizer:
StreamTokenizer stok; stok = new StreamTokenizer(is);
Настройка параметров разборщика очень проста и сводится к вызовам всего двух методов:
stok.slashSlashComments(true); stok.ordinaryChar('.');
Метод slashSlashComments включает режим распознавания комментариев в стиле языка программирования С++, а метод ordinaryChar объявляет символ '.' обычным символом.
После настройки запускается цикл разбора входного потока, причем условием завершения цикла является достижение конца этого потока:
while(stok.nextToken() != StreamTokenizer.TT_EOF) { . . . }
В цикле анализируется содержимое поля ttype, которое зависит от типа элемента, обнаруженного во входном потоке:
switch(stok.ttype) { case StreamTokenizer.TT_WORD: { str = new String("\nTT_WORD >" + stok.sval); break; } case StreamTokenizer.TT_NUMBER: { str = "\nTT_NUMBER >" + Double.toString(stok.nval); break; } case StreamTokenizer.TT_EOL: { str = new String("> End of line"); break; } default: { if((char)stok.ttype == '"') str = new String( "\nTT_WORD >" + stok.sval); else str = "> " + String.valueOf( (char)stok.ttype); } }
На слова и численные значения мы реагируем очень просто - записываем их текстовое представление в рабочую переменную str типа String. При обнаружении конца строки в эту переменную записывается строка End of line.
Если же обнаружен обычный символ, мы сравниваем его с символом кавычки. При совпадении в переменную str записывается содержимое поля sval, в котором находятся слова, обнаруженные внутри кавычек. Если же обнаруженный символ не является символом кавычки, он преобразуется в строку и записывается в переменную str.
В заключении метод выводит строку str в стандартный поток вывода, отображая на консоли выделенный элемент потока:
System.out.println(str);
Описание исходного текста приложения DirectFile
Для работы с базой данных мы создали класс SimpleDBMS, определив в нем конструктор, методы для добавления записей, извлечения записей по их порядковому номеру, а также метод для закрытия базы данных.
Определение атрибутов файлов и каталогов
После того как вы создали объект класса File, нетрудно определить атрибуты этого объекта, воспользовавшись соответствующими методами класса File.
Определение длины файла в байтах
Длину файла в байтах можно определить с помощью метода length:
public long length();
Определение пути к файлу или каталогу
Метод getPath позволяет определить машинно-независимый путь файла или каталога:
public String getPath();
Определение родительского каталога
Если вам нужно определить родительский каталог для объекта класса File, то это можно сделать методом getParent:
public String getParent();
Определение типа объекта - файл или каталог
С помощью методов isDirectory и isFile вы можете проверить, чему соответствует созданный объект класса File - каталогу или файлу:
public boolean isDirectory(); public boolean isFile();
Определение типа указанного пути - абсолютный или относительный
С помощью метода isAbsolute вы можете определить, соответствует ли данный объект класса File файлу или каталогу, заданному абсолютным (полным) путем, либо относительным путем:
public boolean isAbsolute();
Определение времени последней модификации файла или каталога
Для определения времени последней модификации файла или каталога вы можете вызвать метод lastModified:
public long lastModified();
Заметим, однако, что этот метод возвращает время в относительных единицах с момента запуска системы, поэтому его удобно использовать только для относительных сравнений.
Переименование файлов и каталогов
Для переименования файла или каталога вы должны создать два объекта класса File, один из которых соответствует старому имени, а второй - новому. Затем для перовго из этих объектов нужно вызвать метод renameTo, указав ему в качестве параметра ссылку на второй объект:
public boolean renameTo(File dest);
В случае успеха метод возвращает значение true, при возникновении ошибки - false. Может также возникать исключение SecurityException.
Поля класса SimpleDBMS
Поля idx и dat являются объектами класса RandomAccessFile и представляют собой, соответственно, ссылки на файл индекса и файл данных. Поле idxFilePointer типа long используется как рабочее и хранит текущее смещение в файле.
Получение абсолютного пути к каталогу
Метод getAbsolutePath возвращает абсолютный путь к файлу или каталогу, который может быть машинно-зависимым:
public String getAbsolutePath();
Получение имени файла или каталога
Метод getName возвращает имя файла или каталога для заданного объекта класса File (имя выделяется из пути):
public String getName();
Получение списка содержимого каталога
С помощью метода list вы можете получить список содержимого каталога, соответствующего данному объекту класса File. В классе File предусмотрено два варианта этого метода - без параметра и с параметром:
public String[] list(); public String[] list(FilenameFilter filter);
Первый из этих методв возвращает массив строк с именами содержимого каталога, не включая текущий каталог и родительский каталог. Второй позволяет получить список не всех объектов, хранящихся в каталоге, а только тех, что удовлетворяют условиям, определенным в фильтре filter класса FilenameFilter.
Получение текстового представления объекта
Метод toString возвращает текстовую строку, представляющую объект класса File:
public String toString();
Получение значения хэш-кода
Метод hashCode возвращает значение хэш-кода, соответствующего объекту File:
public int hashCode();
Потоки в оперативной памяти
Операционные системы Windows 95 и Windows NT предоставляют возможность для программиста работать с оперативной памятью как с файлом. Это очень удобно во многих случаях. В частности, файлы, отображаемые на память, можно использовать для передачи данных между одновременно работающими задачами и процессами.
При создании приложений и аплетов Java вы также можете работать с объектами оперативной памяти, как с файлами, а точнее говоря, как с потоками. Так как аплетам запрещено обращаться к файлам, расположенным на локальном диске компьютера, при небходимости создания временных потоков ввода или вывода последние могут быть размещены в оперативной памяти.
Ранее мы отмечали, что в библиотеке классов Java есть три класса, специально предназначенных для создания потоков в оперативной памяти. Это классы ByteArrayOutputStream, ByteArrayInputStream и StringBufferInputStream.
Приложение DirectFile
Для иллюстрации способов работы с классом RandomAccessFile мы подготовили приложение DirectFile, в котором создается небольшая база данных. Эта база данных состоит из двух файлов: файла данных и файла индекса.
В файле данных хранятся записи, сосотящие из двух полей - текстового и числового. Текстовое поле с названием name хранит строки, закрытые смиволами конца строки "\r\n", а числовое с названием account - значения типа int.
В меню File нашего приложения есть строки New и View records (рис. 5).

Рис. 5. Строки меню File
С помощью строки New вы можете создать базу данных, состоящую из трех записей. Если выбрать из меню File строку View records, на экране появится диалоговая панель с содержимым этих записей (рис. 6).

Рис. 6. Содержимое трех первых полей базы данных
Вместо символа перевода строки в диалоговой панели отображается маленький квадратик.
Дамп создаваемого файла данных приведен на рис. 7.

Рис. 7. Дамп файла данных
Из этого дампа видно, что после первого запуска приложения в файле данных имеются следующие записи:
| Номер записи | Смещение в файле данных | Поле name | Поле account |
| 0 | 0 | Ivanov | 1000 |
| 1 | 12 | Petrov | 2000 |
| 2 | 24 | Sidoroff | 3000 |
При последующих запусках каждый раз в файл данных будут добавляться приведенные выше записи.
Так как поле name имеет переменную длину, для обеспечения возможности прямого доступа к записи по ее номеру необходимо где-то хранить смещения всех записей. Мы это делаем в файле индексов, дамп которого представлен на рис.8.
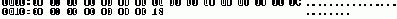
Рис. 8. Дамп файла индекса
Файл индексов хранит 8-байтовые смещения записей файла данных в формате long. Зная номер записи, можнор легко вычислить смещение в файле индексов, по которому хранится смещение нужной записи в файле данных. Если извлечь это смещение, то можно выполнить позиционирование в файле данных с целью чтения нужной записи, что и делает наше приложение.
Приложение StreamToken
В приложении StreamToken мы демонстрируем использование класса StreamTokenizer для разбора входного потока.
Вначале приложение запрашивает у пользователя строку для разбора, записывая ее в файл. Затем этот файл открывается для чтения буферизованным потоком и разбирается на составные элементы. Каждый такой элемент выводится в отдельной строке, как это показано на рис. 4.

Рис. 4. Разбор входного потока в приложении StreamToken
Обратите внимание, что в процессе разбора значение 3.14 было воспринято как числовое, а 3,14 - нет. Это потому, что при настройке разборщика мы указали, что символ '.' является обычным.
Принудительный сброс буферов
Еще один важный момент связан с буферизованными потоками. Как мы уже говорили, буферизация ускоряет работу приложений с потоками, так как при ее использовании сокращается количество обращений к системе ввода/вывода. Вы можете постепенно в течении дня добавлять в поток данные по одному байту, и только к вечеру эти данные будут физически записаны в файл на диске.
Во многих случаях, однако, приложение должно, не отказываясь совсем от буферизации, выполнять принудительную запись буферов в файл. Это можно сделать с помощью метода flush.
Производные от класса InputStream
От класса InputStream производится много других классов, как это показано на рис. 2.
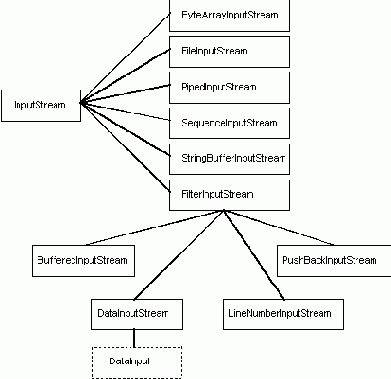
Рис. 2. Классы, производные от класса InputStream
Производные от класса OutputStream
Класс OutputStream предназначен для создания потоков вывода. Приложения, как правило, непосредственно не используют этот класс для операций вывода, так же как и класс InputStream для операций ввода. Вместо этого применяются классы, иерархия которых показана на рис. 3.

Рис. 3. Классы, производные от класса OutputtStream
Рассмотрим кратко назначение этих классов.
Произвольный доступ к файлам
В ряде случаев, например, при создании системы управления базой данных, требуется обеспечить произвольный доступ к файлу. Рассмотренные нами ранее потоки ввода и вывода пригодны лишь для последовательного доступа, так как в соответствующих классах нет средств позиционирования внутри файла.
Между тем библиотека классов Java содержит класс RandomAccessFile, который предназначен специально для организации прямого доступа к файлам как для чтения, так и для записи.
В классе RandomAccessFile определено два конструктора, прототипы которых показаны ниже:
public RandomAccessFile( String name, String mode); public RandomAccessFile( File file, String mode);
Первый из них позволяет указывать имя файла, и режим mode, в котором открывается файл. Второй конструктор вместо имени предполагает использование объекта класса File.
Если файл открывается только для чтения, вы должны передать конструктору текстовую строку режима "r". Если же файл открывается и для чтения, и для записи, конструктору передается строка "rw".
Позиционирование внутри файла обеспечивается методом seek, в качестве параметра pos которому передается абсолютное смещение файла:
public void seek(long pos);
После вызова этого метода текущая позиция в файле устанавливается в соответствии со значением параметра pos.
В любой момент времени вы можете определить текущую позицию внутри файла, вызвав метод getFilePointer:
public long getFilePointer();
Еще один метод, который имеет отношение к позиционированию, называется skipBytes:
public int skipBytes(int n);
Он работает так же, как и одноименный метод для потоков - продвигает текущую позицию в файле на заданное количество байт.
С помощью метода close вы должны закрывать файл, после того как работа с им завершена:
public void close();
Метод getFD позволяет получить дескриптор файла:
public final FileDescriptor getFD();
С помощью метода length вы можете определить текущую длину файла:
public long length();
Ряд методов предназначен для выполнения как обычного, так и форматированного ввода из файла. Этот набор аналогичен методам, определенным для потоков:
public int read(); public int read(byte b[]); public int read(byte b[],int off,int len); public final boolean readBoolean(); public final byte readByte(); public final char readChar(); public final double readDouble(); public final float readFloat(); public final void readFully(byte b[]); public final void readFully(byte b[], int off, int len); public final int readInt(); public final String readLine(); public final long readLong(); public final short readShort(); public final int readUnsignedBytee(); public final int readUnsignedShort(); public final String readUTF();
Существуют также методы, позволяющие выполнять обычную или форматированную запись в файл с прямым доступом:
public void write(byte b[]); public void write(byte b[],int off,int len); public void write(int b); public final void writeBoolean(boolean v); public final void writeBytee(int v); public final void writeBytes(String s); public final void writeChar(int v); public final void writeChars(String s); public final void writeDouble(double v); public final void writeFloat(float v); public final void writeInt(int v); public final void writeLong(long v); public final void writeShort(int v); public final void writeUTF(String str);
Имена приведенных методов говорят сами за себя, поэтому мы не будем их описывать.
Просмотр записей базы данных
При выборе строки View records из меню File приложение открывает файл базы данных:
SimpleDBMS db = new SimpleDBMS( "dbtest.idx", "dbtest.dat");
Затем оно извлекает три записи с номерами 0, 1 и 2, вызывая для этого метод GetRecordByNumber, также определенный в классе SimpleDBMS:
String szRecords;
szRecords = db.GetRecordByNumber(0) + db.GetRecordByNumber(1) + db.GetRecordByNumber(2);
Записи объединяются и сохраняются в переменной szRecords типа String. После этого база данных закрывается:
db.close();
Для отображения содержимого записей мы создаем диалоговую панель на базе определенного нами класса MessageBox:
MessageBox mbox; mbox = new MessageBox(szRecords, this, "Database records", true); mbox.show();
Простейшие методы
Создав выходной поток на базе класса FileOutputStream, вы можете использовать для записи в него данных три разновидности метода write, прототипы которых представлены ниже:
public void write(byte b[]); public void write(byte b[], int off, int len); public void write(int b);
Первый из этих методов записывает в поток содержимое массива, ссылка на который передается через параметр, начиная с текущей позиции в потоке. После выполнения записи текущая позиция продвигается вперед на число записанных байт, которое при успешном завершении операции равно длине массива (b.length).
Второй метод позволяет дополнительно указать начальное смещение off записываемого блока данных в массиве и количество записываемых байт len.
Третий метод просто записывает в поток один байт данных.
Если в процессе записи происходит ошибка, возникает исключение IOException.
Для входного потока, созданного на базе класса FileInputStream, определены три разновидности метода read, выполняющего чтение данных:
public int read(); public int read(byte b[]); public int read(byte b[], int off, int len);
Первая разновидность просто читает из потока один байт данных. Если достигнут конец файла, возвращается значение -1.
Вторая разновидность метода read читает данные в массив, причем количество прочитанных данных определяется размером массива. Метод возвращает количество прочитанных байт данных или значение -1, если в процессе чтения был достигнут конец файла.
И, наконец, третий метод позволяет прочитать данные в область массива, заданную своим смещением и длиной.
Если при чтении происходит ошибка, возникает исключение IOException.
Проверка существования файла или каталога
С помощью метода exists вы можете проверить существование файла или катлога, для которого был создан объект класса File:
public boolean exists();
Этот метод можно применять перед созданием потока на базе класса FileOutputStream, если вам нужно избежать случайной перезаписи существующего файла. В этом случае перед созданием выходного потока класса FileOutputStream следует создать объект класса File, указав конструктору путь к файлу, а затем проверить сущестование файла методом exists.
Проверка возможности чтения и записи
Методы canRead и canWrite позволяют проверить возможность чтения из файла и записи в файл, соответственно:
public boolean canRead(); public boolean canWrite();
Их полезно применять перед созданием соответствующих потоков, если нужно избежать возникновение исключений, связанных с попыткой выполнения доступа неразрешенного типа. Если доступ разрешен, эти методы возвращают значение true, а если запрещен - false.
Работа с файлами
Библиотека классов языка программирования Java содержит многочисленные средства, предназначенные для работы с файлами. И хотя аплеты не имеют доступа к локальным файлам, расположенным на компьютере пользователя, они могут обращаться к файлам, которые находятся в каталоге сервера Web. Автономные приложения Java могут работать как с локальными, так и с удаленными файлами (через сеть Internet или Intranet).
В любом случае, будете ли вы создавать автономные приложения Java или аплеты, взаимодействующие с сервером Web через сеть, вы должны познакомиться с классами, предназначенными для организации ввода и вывода.
Работа с файлами и каталогами при помощи класса File
В предыдущих разделах мы рассмотрели классы, предназначенные для чтения и записи потоков. Однако часто возникает необходимость выполнения и таких операций, как определение атрибутов файла, создание или удаление каталогов, удаление файлов, получение списка всех файлов в каталоге и так далее. Для выполнения всех этих операций в приложениях Java используется класс с именем File.
Работа со стандартными потоками
Приложению Java доступны три стандратных потока, которые всегда открыты: стандартный поток ввода, стандартный поток вывода и стандартный поток вывода сообщений об ошибках.
Все перечисленные выше потоки определены в классе System как статические поля с именами, соответственно, in, out и err:
public static PrintStream err; public static InputStream in; public static PrintStream out;
Заметим, что стандратные потоки, как правило, не используются аплетами, так как браузеры общаются с пользователем через окно аплета и извещения от мыши и клавиатуры, а не через консоль.
Создание базы данных
Когда пользователь выбирает из меню File строку New, соответствующий обработчик события создает базу данных, передавая конструктору имена файла индекса dbtest.idx и файла данных dbtest.dat:
SimpleDBMS db = new SimpleDBMS( "dbtest.idx", "dbtest.dat");
После этого с помощью метода AddRecord, определенного в классе SimpleDBMS, в базу добавляются три записи, состоящие из текстового и числового полей:
db.AddRecord("Ivanov", 1000); db.AddRecord("Petrov", 2000); db.AddRecord("Sidoroff", 3000);
После завершения работы с базой данных она закрывается методом close из класса SimpleDBMS:
db.close();
Создание каталогов
С помощью методов mkdir и mkdirs можно создавать новые каталоги:
public boolean mkdir(); public boolean mkdirs();
Первый из этих методов создает один каталог, второй - все подкаталоги, ведущие к создаваемому каталогу (то есть полный путь).
Создание объекта класса File
У вас есть три возможности создать объект класса File, вызвав для этого один из трех конструкторов:
public File(String path); public File(File dir, String name); public File(String path, String name);
Первый из этих конструкторов имеет единственный параметр - ссылку на строку пути к файлу или каталогу. С помощью второго конструктора вы можете указать отдельно каталог dir и имя файла, для которого создается объект в текущем каталоге. И, наконец, третий конструктор позволяет указать полный путь к каталогу и имя файла.
Если первому из перечисленных конструкторов передать ссылку со значением null, возникнет исключение NullPointerException.
Пользоваться конструкторам очень просто. Вот, например, как создать объект класса File для файла c:\autoexec.bat и каталога d:\winnt:
f1 = new File("c:\\autoexec.bat"); f2 = new File("d:\\winnt");
Создание потока для форматированного обмена данными
Оказывается, создание потоков, связанных с файлами и предназначенных для форматированного ввода или вывода, необходимо выполнять в несколько приемов. При этом вначале необходимо создать потоки на базе класса FileOutputStream или FileInputStream, а затем передать ссылку на созданный поток констркутору класса DataOutputStream или DataInputStream.
В классах FileOutputStream и FileInputStream предусмотрены конструкторы, которым в качестве параметра передается либо ссылка на объект класса File, либо ссылка на объект класса FileDescriptor, либо, наконец, текстовая строка пути к файлу:
public FileOutputStream(File file); public FileOutputStream( FileDescriptor fdObj); public FileOutputStream(String name);
Таким образом, если вам нужен выходной поток для записи форматированных данных, вначале вы создаете поток как объект класса FileOutputStream. Затем ссылку на этот объект следует передать конструктору класса DataOutputStream. Полученный таким образом объект класса DataOutputStream можно использовать как выходной поток, записывая в него форматированные данные.
Создание потоков, связанных с файлами
Если вам нужно создать входной или выходной поток, связанный с локальным файлом, следует воспользоваться классами из библиотеки Java, созданными на базе классов InputStream и OutputStream. Мы уже кратко рассказывали об этих классах в разделе "". Однако методика использования перечисленных в этом разделе классов может показаться довольно странной.
В чем эта странность?
Говоря кратко, странность заключается в том, что для создания потока вам необходимо воспользоваться сразу несколькими классами, а не одним, наиболее подходящим для решения поставленной задачи, как это можно было бы предположить.
Поясним сказанное на примере.
Пусть, например, нам нужен выходной поток для записи форматированных данных (скажем, текстовых строк класса String). Казалось бы, достаточно создать объект класса DataOutputStream, - и дело сделано. Однако не все так просто.
В классе DataOutputStream предусмотрен только один конструктор, которому в качестве параметра необходимо передать ссылку на объект класса OutputStream:
public DataOutputStream(OutputStream out);
Что же касается конструктора класса OutputStream, то он выглядит следующим образом:
public OutputStream();
Так как ни в том, ни в другом конструкторе не предусмотрено никаких ссылок на файлы, то непонятно, как с использованием только одних классов OutputStream и DataOutputStream можно создать выходной поток, связанный с файлом.
Что же делать?
Сравнение объектов класса File
Для сравнения объектов класса File вы должны использовать метод equals:
public boolean equals(Object obj);
Заметим, что этот метод сравнивает пути к файлам и каталогам, но не сами файли или каталоги.
Стандартные потоки
Для работы со стандартными потоками в классе System имеется три статических объекта: System.in, System.out и System.err. По своему назначению эти потоки больше всего напоминают стандартные потоки ввода, вывода и вывода сообщений об ошибках операционной системы MS-DOS.
Поток System.in связан с клавиатурой, поток System.out и System.err - с консолью приложения Java.
Стандартный поток ввода
Стандартный поток ввода in определен как статический объект класса InputStream, который содержит только простейшие методы для ввода данных. Нужнее всего вам будет метод read:
public int read(byte b[]);
Этот метод читает данные из потока в массив, ссылка на который передается через единственный параметр. Количество считанных данных определяется размером массива, то есть значением b.length.
Метод read возвращает количество прочитанных байт данных или -1, если достигнут конец потока. При возникновении ошибок создается исключение IOException, обработку которого необходимо предусмотреть.
Стандартный поток вывода
Стандартный поток вывода out создан на базе класса PrintStream, предназначенного, как мы это отмечали раньше, для форматированного вывода данных различного типа с целью их визуального отображения в виде текстовой строки.
Для работы со стандартным потоком вывода вы будете использовать главным образом методы print и println, хотя метод write также доступен.
В классе PrintStream определено несколько реализаций метода print с параметрами различных типов:
public void print(boolean b); public void print(char c); public void print(char s[]); public void print(double d); public void print(float f); public void print(int i); public void print(long l); public void print(Object obj); public void print(String s);
Как видите, вы можете записать в стандартный поток вывода текстовое представление данных различного типа, в том числе и класса Object.
Метод println аналогичен методу print, отличаясь лишь тем, что он добавляет к записываемой в поток строке символ перехода на следующую строку:
public void println(); public void println(boolean b); public void println(char c); public void println(char s[]); public void println(double d); public void println(float f); public void println(int i); public void println(long l); public void println(Object obj); public void println(String s);
Реализация метода println без параметров записывает только символ перехода на следующую строку.
Стандртный поток вывода сообщений об ошибках
Стандртный поток вывода сообщений об ошибках err так же, как и стадартный поток вывода out, создан на базе класса PrintStream. Поэтому для записи сообщений об ошибках вы можете использовать только что описанные методы print и println.
Удаление файлов и каталогов
Для удаления ненужного файла или каталога вы должны создать соответствующий объект File и затем вызвать метод delete:
public boolean delete();
Закрывание потоков
Работая с файлами в среде MS-DOS или Windows средствами языка программирования С вы должны были закрывать ненужные более файлы. Так как в системе интерпертации приложений Java есть процесс сборки мусора, возникает вопрос - выполняет ли он автоматическое закрывание потоков, с которыми приложение завершило работу?
Оказывается, процесс сборки мусора не делает ничего подобного!
Сборка мусора выполняется только для объектов, размещенных в оперативной памяти. Потоки вы должны закрывать явным образом, вызывая для этого метод close.
Запись данных в поток и чтение данных из потока
Для обмена данными с потоками можно использовать как простейшие методы write и read, так и методы, допускающие ввод или вывод форматированных данных. В зависимости от того, на базе какого класса создан поток, зависит набор доступных методов, предназначенных для чтения или записи данных.