Декларативное описание прав доступа в J2EE.
В данном разделе я расскажу "совсем кратко" КАК подключать и описывать права доступа в EJB компонентах и не утверждаю, что для Web ресурсов все "точно так же", хотя сам принцип - точно такой же. При этом я не собираюсь изложить "все тонкости" и возможности, которые присутствуют в J2EE дескрипторах бинов, я только описываю "простейший подход", который далек от совершенства, но все-таки дает представление о сути темы "контроля доступа".
Как правило EJB компоненты, прежде чем их поместить в EAR модуль-приложение, компоненты группируются в отдельные JAR модули. Каждому такому модулю соответствует файл-дескриптор внутри него - ejb-jar.xml, в котором описываются все возможные параметры, описывающие разные характеристики, в том числе и касаемые "контроля доступа". Группировать ли EJB по некоторым логическим соображениям или "свалить их в кучу", создав только один JAR файл - это ваше личное дело и предпочтение. Я всегда стараюсь как в коде, так и в сборках, разные логические части системы "содержать отдельно" друг от друга.
Что вообще такое "роль"? Это некоторая строка, значение которой обозначает "разрешение, право доступа". В качестве значения этому разрешению лучше давать "логически понятное" название, исходя из вашего проекта, смысла этой роли и т.д. По своей сути, роль - это название "разрешения" (permission) для доступа к описанному этой ролью сервису (методу, интерфейсу, бину). Поэтому я дальше так и буду называть - "роль-право доступа ", хотя это, наверное, и не совсем правильно с "научной" точки зрения.
Контроль доступа в J2EE серверах, а значит и в JBoss, выполняется при помощи простой проверки двух списков. С одной стороны - это список "ролей-прав", которые будут извлечены и кэшированы для вызывающего клиента, когда он будет идентифицирован в системе. Данный список "прав доступа" в литературе имеет еще названия: client identity, security identities. С другой стороны - это список "ролей-прав", назначенных у EJB компонент в ejb-jar.xml дескрипторном файле. В литературе он обычно называется security roles. При обращении клиента к методам EJB, отдельные строки ролей-разрешений из этих двух списков "проверяются на совпадение", и должны присутствовать в обоих для успешного вызова определенного метода клиентом с определенным именем.
Если вы еще НЕ настраивали ejb-jar.xml дескрипторы на работу с "контролем доступа", то скорее всего он выглядит приблизительно так:
<ejb-jar> ............. <enterprise-beans> ............. <!-- ЗДЕСЬ ОПИСАНЫ БИНЫ с именами:
EJB_1, EJB_2, EJB_3 --> </enterprise-beans> <assembly-descriptor> <container-transaction> ............... <!-- ЗДЕСЬ ОПИСАНЫ АТТРИБУТЫ
ТРАНЗАКЦИЙ --> </container-transaction> </assembly-descriptor><ejb-jar>
Т.к. нас интересует только часть <assembly-descriptor>, то остальную часть я приводить не буду.
ejb-jar.xml
................................. <assembly-descriptor> <security-role> <description>Права вызова ЛЮБЫХ методов
у EJB компонент модуля</description> <role-name>ManageObjects</role-name> </security-role> <security-role> <description> Права вызова методов поиска
(findAll, findByPK, getFullObject) EJB компонент </description> <role-name>ViewObjects</role-name> </security-role> ................................... </assembly-descriptor>
В дескрипторе мы определили две роли или два разрешения с названиями - ManageObjects и ViewObjects. Далее эти роли мы назначим методам бинов. В этом же дескрипторе появляется описание такого вида:
<assembly-descriptor> ........................ <method-permission> <role-name>ManageObjects<
/role-name> <method> <ejb-name>EJB_1</ejb-name> <method-name>*</method-name> </method> </method-permission>
<method-permission> <role-name>ManageObjects</role-name> <method> <ejb-name>EJB_2</ejb-name> <method-name>*</method-name> </method> </method-permission>
<method-permission> <role-name>ManageObjects</role-name> <method> <ejb-name>EJB_3</ejb-name> <method-name>*</method-name> </method> </method-permission> <!-- Пользователи имеющие у себя роль-разрешение
ManageObjects, получат доступ к ЛЮБОМУ методу на ЛЮБОМ интерфейсе
бинов EJB_1, EJB_2, EJB_3, что указывается символом (*) в названии метода -->
Использование простейшего логин-модуля для контроля доступа в JBoss.
Теперь, назначив роли, права доступа методам EJB в файле(ах) ejb-jar.xml, мы можем продолжить настройки контроля доступа. Здесь я расскажу, КАК можно использовать готовые логин-модули, которые имеются в JBoss. Одни из них будут использоваться на (GUI) клиенте, другие на сервере.
Модель контроля доступа в JBoss.
Сильно не хочется зарываться в эту тему "по теории", но все-таки придеться немного написать, хотя бы в простейшем и неполном виде.
Как правило , под "контролем доступа" понимаются ДВА процесса.
Первый процесс - это идентификация (authentication) пользователя, который как правило происходит один раз при начале работы клиента с сервером/сервисом. Это означает, что производиться проверка, что "вы - это вы". Обычно используется самый распространенный способ - "имя + пароль", хотя можно использовать и более "замысловатые варианты", например сертификаты. При этом сервер проверяет, что он "знает" о пользователе с предоставленным именем, и проверяет совпадает ли введенный пароль (или не сам пароль, а ХЭШ значения сравниваемых паролей) с тем, который известен ему в системе.
Второй процесс - это авторизация (authorization) или проверка полномочий или прав доступа пользователя к каждому ресурсу. Этот процесс происходит каждый раз при обращении клиента к сервисам/ресурсам, например методам бинов, сервлетам, JSP, очередям JMS у JBoss-а. Суть этого процесса заключается в том, что сервер все время проверяет, имеет ли данный клиент права доступа, которые описаны как "необходимые и достаточные" для доступа к сервису. Существует два типа авторизации - "программная" и "декларативная".
Рассматривать программный способ я не буду, только кратко скажу о его сути. Суть программного метода заключается в том, что в методе бина программист должен написать код, который проверяет - достаточно ли у пользователя прав для вызова этого метода, т.е. мы сами должны написать код проверки и выполнить ее.
Смысл декларативной авторизации в том, что в файле-дескрипторе описываются необходимые для доступа "роли-права доступа " и все проверки выполняются самим сервером без нашего вмешательства.
Согласно J2EE спецификации, JBoss реализует "контроль доступа" к своему контейнеру (в первую очередь EJB-контейнеру, но и к другим контейнерам тоже), используя технологию JAAS. Эта технология позволяет на ее основе писать "свои" модули контроля доступа (логин-модули) и "встраивать" их в сервер "как плагины". Назначение "логин-модуля" - проверка идентификации пользователя и получение для указанного имени пользователя "ролей-прав", которые сервер "кэширует", ассоциируя их с security context-ом пользователя. Что такое "роли", которые я называю "роли-права доступа " - см. дальше.
Каждый вызов, каждое обращение любого клиента к ресурсам сервера - методу(ам) EJB, обращение к сервелету, обращение к JSP, JMS, происходит через "специальные" в JBoss-е объекты - "security interceptor". "Security interceptor" - это специальные прокси-объекты JBoss, обращение к которым происходит ДО того, как клиент получит доступ к ресурсу и именно в них выполняется авторизация клиента, т.е. проверяется "разрешение" на доступ. Это выполняется самим сервером, с помощью сравнения списка "ролей-прав" клиента, извлеченных и кэшированных при первом входе клиента в систему, со списком "ролей-прав" описанных для "ресурса", к которому выполняется обращение.
Возможно, вам НЕ придеться писать самостоятельно ни объекты "security interceptor", ни "логин-модули", т.к. сервер имеет уже несколько готовых модулей и вы просто воспользуетесь ими. Это может быть простейший способ на основе двух файлов users.properties + roles.properties. Есть и другие модули - на основе обращения к СУБД, есть с использованием LDAP сервера. Подойдут ли они вам и работают ли они так как требуется вам - решать и проверять только вам.
Итак, объекты "security interceptor" управляются некоторым объектом "security-manager", который для своей работы, использует подключенные JAAS логин-модули. Такой "логин-модуль" определяет некоторый способ получения и извлечения информации об пользователе, обычно: имя, пароль + права доступа (роли) к ресурсам/сервисам. Всю эту кухню (вместе с другими security объетками) принятно называть "доменами контроля доступа", security domain, security realm.
Если вы ранее ни разу НЕ устанавливали и НЕ настраивали security JBoss-е, то скорее всего оба этих процесса идентификации и авторизации, происходили и происходят у вас совершенно "прозрачно" и незаметно, вы возможно даже НЕ думали, что они вообще происходят. Но на самом деле все проверки выполняются, но правила для проверки "не применяется", потому что вы НЕ указали ни одного "домена контроля доступа" в вашем J2EE приложении.
Настройка доменов контроля доступа в JBoss 3.х.х
Yuriy Larin aka Blandger
Оригинал статьи - на сайте
Частые обращения и вопросы на форуме , связанные с заголовком данной страницы, "сподвигли" меня на написание этой статьи. Все что написанно здесь - это мой личный опыт, какие-то детали связанные с темой я понимаю "вполне прилично" (век живи - век учись), какие-то почти нет, но описанный здесь подход "вообщем-то" рабочий и "почти правильный", хотя он НЕ единственный. Если у вас другие способы настроек, использования JAAS аутентификации, авторизации и/или дополнения - вносите свои предложения, замечания.
К сожалению, я не буду вдаваться в подробности и описание JAAS, ее реализацию в JBoss, потому что: 1. по причине нехватки времени, 2. вы наверное хотите сначала настроить JBoss, а потом уже разбираться в теории, 3. я не совсем уверен, что все объясню правильно согласно "науке-ботанике" J2EE. Так что, если мои рассуждения или объяснения будут неверными - можете смело меня "пинать", а лучше - напишите правильнее чем я. Этим вы сделаете приятное себе и полезное людям.
Исходные требования/данные в моей системе были таковы - JBoss 3.0.x (потом это был 3.2.x), используемый SQL сервер - FireBird 1.х (или Interbase), это также означает, что "пул соединений" (Connection Pool или DataSource) также необходимо настроить самостоятельно. По поводу настроек для других SQL серверов - все операции выполняются аналогично.
Ко всему прочему "контроль доступа" в моем случае должен был осуществляться с помощью "групп пользователей" и их "ролей", которые описаны и храняться ВНУТРИ СУБД, т.е. имеются отдельные таблицы (USERS, ROLES, GROUPS и т.д.), в которые это все заноситься и описывается. Еще замечание, данная статья описывает процесс настройки "доменов контроля доступа", который предназначен для доступа из GUI-приложения, хотя для WEB-приложения это будет "как-то похоже", но все-таки несколько отличается !!
Настройка пула соедиений.
Первое что для этого необходимо - сам JDBC драйвер для используемого вами SQL сервера. Также очень хорошо, если он специально написан в соответствии с одной из J2EE спецификаций, которая называется JCA (Java Connector Architecture).
Если вы не знаете, что это такое, то говоря кратко и очень упрощенно - это набор некоторых правил, по которым необходимо писать "встраиваемые" в "сервер-приложений" модули, через которые выполняется обращение в некоторым ресурсам, особенно внешним. Если высказывать мое личное мнение (поправьте, если ошибаюсь), то вся архитектура сервера JBoss - это некоторое "ядро" написанное с помощью другой технологии JMX (Java Management Extension), к которому через "адаптеры" (в том числе и JCA) подключаются все необходимые для работы модули/подсистемы - подсистема логирования (на основе библиотеки Log4J), EJB-контейнер, Web-контейнер (TomCat или Jetty), JAAS (Java Authentication and Authorization Service) модуль идентификации и авторизации, JMS (Java Message Service) и т.д. То есть, как видите - JBoss сам сделан "как конструктор " и широко использует JCA. Если именно JCA драйвера нет, то можно пользоваться "простым" или спросите чем пользуются другие люди.
Что касается JCA драйвера для FireBird, то последнюю версию надо брать там же где вы скачивали саму СУБД, а именно здесь - , в списке архивов для скачивания, нас в данном случае интересует пункт с названием - firebird-jca-jdbc-driver. Если говорить про драйвера других СУБД - ищите в инете и/или на сайтах "производителя" СУБД.
В первую очередь в архиве адаптера нас интересует "документация" (которую надо хотя бы просмотреть), и еще файл - firebirdsql.rar. Расширение RAR у данного файла - это на самом деле НЕ файл от архиватора "WinRAR", а "специальный" файл-архив, упакованный стандартным JAR-ом, но имеющий дополнительные данные внутри, там есть файл \META-INF\ra.xml . Он вообще-то кое-что значит, но "как правило" никаким настройкам (пока что) не подлежит.
Основные настройки производятся в другом XML файле, копию которого вы должны сначала взять как образец из каталога ...\jboss\docs\examples\jca\ (для более "старых или "новых" версий сервера название каталога может отличаться), затем поместить копию в каталог для "деплоймента" - это каталог: ...\jboss\server\default\deploy\ (если говорить о "конфигурации" по умолчанию), а затем - исправить внутри него настройки для вашего конкретного случая.
Небольшое отступление...
Мне кажется не все знают, что JBoss "умеет" запускаться с "разными конфигурациями". Создание конфигурации в JBoss означает, что в каждой конфигурации, можно выполнить настройки так, чтобы загружать разное количество сервисов. Какими-то сервисами вы иногда наверняка не пользуетесь, например JMS, и поэтому можете исключить определенные сервисы из запуска в определенной конфигурации.
Например, в каталоге JBoss после его установки, по умолчанию имеются 3 конфигурации сервера:
...\jboss\server\all\ ...\jboss\server\default\ ...\jboss\server\minimal\
Если вы запускаете сервер простым стартом файла ...\jboss\bin\run.bat , то запускается "default" конфигурация. Но кроме этого всегда есть возможность создать, например на ее основе, СВОЮ конфигурацию и запускать ее "отдельным номером".
Я обычно предпочитаю взять "default" конфигурацию и скопировать все ее содержимое со всеми подкаталогами в "новую конфигурацию", с которой потом и работаю, ну например так:
...\jboss\server\my_configuration\...
При "обычном" запуске JBoss сервера с помощью "стандартного батника" ...\jboss\bin\run.bat , по умолчанию запускается "default" конфигурация, а чтобы запустить "свою конфигурацию", достаточно в этом же каталоге написать любой другой my_configation.bat файл, который содержит единственную строку запуска с параметром:
run.bat -c=my_configuration
или в последних версиях через пробел
run.bat -c my_configuration
где в "run.bat" передается дополнительный параметр -C со значением равным "названию конфигурации" =my_configuration , что приведет к запуску JBoss-а с указанной вами конфигурацией. Вот так все просто...
Продолжим дальше с настройкой пула. ...\jboss\docs\examples\jca\ - содержит образцы файлов "пула соединений" для всех самых распространенных СУБД. Для меня это был - firebird-service.xml (или firebird-ds.xml, для более свежих версии JBoss). По причине того, что файлы "пула соединений" от версии к версии JBoss-а немного отличаются, то я опишу только "ключевые" параметры, которые необходимо отредактировать.
Для версий JBoss 3.0.x firebird-service.xm обычно выглядит так:
....... <mbean code = "org.jboss.resource.connectionmanager.
RARDeployment" name = "jboss.jca:service=XaTxDS,name=FirebirdDS" > ................. <depends optional-attribute-name="
ManagedConnectionFactoryName"> <mbean code="org.jboss.resource.connectionmanager.
RARDeployment" name="jboss.jca:service=XaTxDS,name=
FirebirdDS" > .............. <config-property> <config-property-
name>Database</config-property-name> <config-property-type>java.lang.String<
/config-property-type> <config-property-value>localhost/3050:С:/DataBase/test.gdb</
config-property-value> </config-property> <config-property> <config-property-name>UserName<
/config-property-name> <config-property-type>java.lang.String<
/config-property-type> <config-property-value>sysdba<
/config-property-value> </config-property> <config-property> <config-property-name>Password<
/config-property-name> <config-property-type>java.lang.String<
/config-property-type> <config-property-value>masterkey<
/config-property-value> <config-property> <config-property-name>Encoding<
/config-property-name> <config-property-type>java.lang.String<
/config-property-type> <config-property-value>WIN1251<
/config-property-value>................
FirebirdDS - это JNDI имя вашего пула, это то как оно будет "привязываться" (binding - байндиться) в JNDI (Java Naming Directory Interface) сервера, и под каким именем (в виде - java:/FirebirdDS) вы его будете искать внутри кода. Во всех местах XML файла крайне желательно иметь это имя ОДИНАКОВЫМ, чтобы избежать лишних проблем. Лично я предпочитаю переименовать его с указанием "подветки", например так: jdbc/FirebirdDS (или по другому ), тогда java-код его поиска в JNDI будет осуществляться по имени - java:/jdbc/FirebirdDS. Почему пул соединений помещен "в подветку" с именем jdbc - объяснять не буду.
Необходимые настройки и код доступа клиента.
Прежде чем мы продолжим настройку контроля доступа на сервере, я хотел бы рассказать и показать ЧТО и КАК делается на стороне клиента (например GUI), для того чтобы выполнялась идентификация и авторизация, используя возможности JAAS.
Вот часть кода, который у меня используется для идентификации и авторизации клиента в JUnit тесте:
Hashtable props = new Hashtable(); props.put(Context.INITIAL_CONTEXT_FACTORY, "localhost:1099"); props.put(Context.PROVIDER_URL, "org.jnp.interfaces.NamingContextFactory"); props.put(Context.URL_PKG_PREFIXES, "
org.jboss.naming"); try { context = new InitialContext(props); // поиск бина с именем "MyEntityBean" Object ref = context.lookup("MyEntityBean"); home = (MyEntityBeanHome)
PortableRemoteObject.narrow( ref, MyEntityBeanHome.class); // имя пользователя и пароль доступа к серверу String userName = "test"; String password = "testpass"; // установка свойства, для указания файла
конфигурации // JAAS логин-модуля на клиентском приложении System.setProperty( "java.security.auth.login.config", "X:/.../jboss/client/auth.conf");
// используемый обработчик, которому передаются
вводимые имя и пароль org.jboss.security.auth.callback.
UsernamePasswordHandler handler = new org.jboss.security.auth.callback.
UsernamePasswordHandler( userName, password.toCharArray());
// создание логин-контекста на клиенте final javax.security.auth.login.LoginContext lc = new javax.security.auth.login.LoginContext
("simple", handler);
// логин в систему lc.login();
} catch (javax.security.auth.login.
LoginException e) { System.out.println("Login
Exception: " + e); e.printStackTrace(); } catch (NamingException e) { System.out.println("Naming
Exception: " + e); e.printStackTrace(); }
Интересной частью, является содержимое файла - auth.conf., который используется клиентом и должен поставляться вместе с клиентским приложением. А также название клиентского логин-модуля - "simple".
Файл auth.conf создан по образцу имеющегося в JBoss файла, только упрощен. Не вдаваясь в подробности, стоит сказать, что необходимо "точное" соблюдение формата данного файла, с учетом всех символов-разделителей (;).
Содержимое файла - auth.conf
simple { org.jboss.security.ClientLoginModule
required; };
Клиент использует файл конфигурации с указанным классом (org.jboss.security.ClientLoginModule) , который реализован как JAAS логин-модуль. Данный класс просто "делегирует", передает вводимые пользователем "имя и пароль" на сервер.
На этом можно закончить настройку клиента и его кода. Этого достаточно для работы клиента, хотя возможны варианты использования других классов "клиентского" логин-модуля. Для использования на клиентской стороне существует еще один класс для логин-модуля - SRPLoginModule, но мне не удалось его настроить.
Пример логин-модуля контроля доступа, использующий СУБД.
Теперь я расскажу, как настроить более удобный домен контроля доступа с использованием СУБД.
Обратимся с очередной раз к файлу настроек контроля доступа - ....\jboss\server\my_configuration\conf\login-config.xml . В данный файл мы поместим еще один серверный домен контроля доступа, который использует СУБД. Настроенный домен будет основан на использовании готового класса - org.jboss.security.auth.spi.DatabaseServerLoginModule. Пример описания домена и его параметры таковы:
login-config.xml
............... <application-policy name = "
databaseSecurityDomain"> <authentication> <login-module code = "org.jboss.
security.auth.spi.DatabaseServerLoginModule" flag = "required"> <module-option name = "dsJndiName">java:
/jdbc/FirebirdDS</module-option> <module-option name = "
principalsQuery"> select USER_PASSWORD from
USERS where NAME=? </module-option> <module-option name = "
rolesQuery"> select ROLE_NAME, 'Roles'
from USERS u ..... ................ and u.name=? </module-option> <module-option name = "
debug">true</module-option> </login-module> </authentication> </application-policy> ...........................
JNDI имя указанного домена контроля доступа - databaseSecurityDomain, вы можете указать любое другое имя, но именно это имя вы будете указывать в ejb-jar.xml в виде - java:/jaas/databaseSecurityDomain.
jboss.xml
<?xml version="1.0"?> <jboss> <security-domain>java:/jaas/
databaseSecurityDomain</security-domain>
<enterprise-beans> ................<!-- ЗДЕСЬ ОПИСАНЫ БИНЫ --> </enterprise-beans> ................ <jboss>
Данному модулю для корректной работы требуется три обязательных параметра. Если быть до конца точным, обязательный параметр один -JNDI имя пула, но тогда данные будут выбираться из таблиц с именами "по умолчанию" и с предопределенной структурой, а из каких именно - вы скорее всего не узнаете, пока не прочтете в документации.
Продолжим настройку серверной части JAAS, простейший серверный логин-модуль.
Для настройки домена контроля доступа на сервере, мы воспользуемся логин-модулем, реализованным классом org.jboss.security.auth.spi.UsersRolesLoginModule. Данным модулем удобно пользоваться в процессе разработки системы, в силу простоты его использования, но для "production" системы, вы скорее всего воспользуетесь более "продвинутым" вариантом, который описан в конце статьи.
Для работы он использует два файла. Первый файл должен иметь название - users.properties. Он используется для хранения на сервере имени пользователей и их пароли, которые будут проверяться сервером на "совпадение" с теми значениями, которые будут предоставлены клиентами.
Второй файл должен иметь название - roles.properties. Он используется для хранения на сервере "ролей-прав". Эти права назначаются (относятся) к именам пользователей, которые предварительно описаны в файле users.properties . Все подробности об этих файлах я напишу немного позже.
В запускаемой вами конфигурации есть уже готовая настройка логин-модуля, если вы загляните в файл:
........\jboss\server\my_configuration\conf\login-config.xml
Внутри данного файла вы должны увидеть несколько настроенных "доменов контроля доступа", один из них приблизительно такой:
login-config.xml
.......................... <application-policy name =
"other"> <authentication> <login-module code = "org.jboss.security.auth.spi.UsersRolesLoginModule" flag = "required" /> </authentication> </application-policy> .........................
Как видите данный контроллер имеет название "other" и использует JAAS логин-модуль, реализованный в классе org.jboss.security.auth.spi.UsersRolesLoginModule. Данный логин-модуль использует ДВА файла свойств для хранения имен пользователей, паролях и ролях-разрешениях.
Вы можете дать этому домену другое название в указанном XML файле, или использовать название указанное по умолчанию (other). Мы будем использовать указанное. Тогда наши JBoss файлы-дескрипторы для EJB модулей будут выглядеть так:
jboss.xml
<?xml version="1.0"?> <jboss> <security-domain>java:/jaas/other<
/security-domain> <enterprise-beans> ................<!-- ЗДЕСЬ ОПИСАНЫ БИНЫ -->
</enterprise-beans> ................ <jboss>
Теперь, если вы попробуете вызвать метод вашего бина из клиента, то скорее всего получите следующее сообщение об ошибке в лог-файле сервера:
server.log
2004-03-07 11:35:05,602 ERROR
[org.jboss.security.auth.spi.UsersRolesLoginModule] Failed to load users/passwords/
role files java.io.IOException: Properties file users.properties
not found at org.jboss.security.auth.spi.
UsersRolesLoginModule.loadProperties(
UsersRolesLoginModule.java) ..........................
Это говорит о том на клиенте мы воспользовались одним из JAAS логин-модулем. При этом клиент выполнял вход в систему с использованием JAAS логин-модуля на основе класса ClientLoginModule. Затем эта информация для идентификации пользователя была передана на сервер.
После чего была выполнена попытка инициализации "домена контроля доступа" при обращении к методам EJB, с использованием подключенного в ejb-jar.xml файле "другого" домена контроля доступа на основе JAAS. Этот серверный домен реализован в классе UsersRolesLoginModule. Но при попытке сервера считать информацию об "имени и пароле" для выполенения идентификации пользователя, на сервере произошла ошибка. Для устранения ошибки нам необходимо продолжить настройку и поместить данную информацию на сервер. Для этого в каталоге нашей конфигурации мы создаем файл ...\jboss\server\my_configuration\conf\users.properties со следующим содержимым:
test=testpass #также можно поместить имена других пользователей и их пароли user2=password2
Теперь, выполнив доступ к серверу, вы скорее всего получите следующую ошибку в логе сервера:
server.log
2004-03-07 11:35:53,000 ERROR [org.
jboss.security.auth.spi.UsersRolesLoginModule] Failed to load users/passwords/
role files java.io.IOException: Properties file roles.properties
not found at org.jboss.security.auth.spi.
UsersRolesLoginModule.loadProperties(
Сборка сервера JBoss 3.x из исходного кода
Yuriy Larin aka Blandger
Оригинал статьи - на сайте
Компиляция и сборка сервера JBoss выполняется довольно легко. Вы сами это увидите, когда прочтете эту статейку и попробуете сделать это самостоятельно.
Что касается любых версий сервера 3.x.x, то по информации от создателей (также проверено самостоятельно), он компилируется как на JDK 1.3.x, так и на JDK 1.4.x. При этом вы конечно же получаете либо один, либо другой код. Запускать его лучше на той же версии JDK, на которой он собирался, хотя это и не "железно". Код из 1.3 без проблем исполняется на 1.4, и можно попробовать кажется и наоборот (не помню, но кажется вполне получалось это делать с кодом JBoss-а). А вот что касается JBoss версии 4.x, то он "завязан" на определенные фичи JDK 1.4 и компилиться под 1.3 - НЕ БУДЕТ (думаю что это так, хотя сам не проверял).
Допустим вы уже скачали последний дистрибутив исходников сервера JBoss с sourceforge.org. Это должен быть архив, что-то типа jboss-3.x.x-src.zip , где x.x - подномера версии (или tar архив). Кроме этого на вашем ПК должен быть установлен какой-либо JDK, скорее всего это не меньше чем JDK 1.3 или 1.4. Пусть это будет каталог: D:\j2sdk1.4.2
Распаковываем исходники в удобный каталог.
Пусть это: D:\jboss-3.2.1-src\
После распаковки в каталоге D:\jboss-3.2.1-src\ у вас должно появиться масса подкаталогов, что-то типа такого вида:
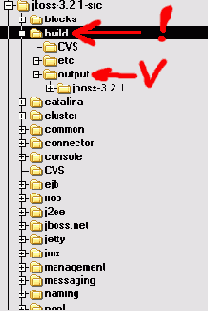
На картинке я дополнительно выделил пару каталогов.
Каталог ..\build\.. - обозначен ( ! ) Это место, где мы будем запускать сборку, а потом найдем собранный сервер.
Каталог ..\build\output\jboss-3.x.x\... - обозначен ( птичкой ), сначала НЕ существует, а после сборки в нем появляется готовый к применению "сервер". В данном случае это был ...\jboss-3.2.1\
Переходим к следующему важному шагу - настройка ANT-а.
Если вы не знаете, что это за инструмент, то для сборки J2EE проектов, особенно больших, я крайне рекомендую освоить его. Потратив на это время, вы его потом сэкономите в будущем.
Я предалагаю, на мой взгляд, самый простой и быстрый способ настройки ANT-а для сборки JBoss, хотя этот способ и НЕ единственный.
При работе на Windows наобходимо в каталоге, куда вы распаковали исходники JBoss, найти файл - D:\jboss-3.2.1-src\tools\bin\ant.bat
Для UNIX (Linux) - это будет скрип файл D:\jboss-3.2.1-src\tools\bin\ant , но КАК в нем настроить значение переменной указывающей на JDK - тут я пас, плохо знаком с Linux.
В его начало, перед выполением основных иструкций, поместите переменную со значением, где находиться требуемое для компиляции и сборки JDK:
set JAVA_HOME=D:\j2sdk1.4.2
Проверьте, чтобы в конце строки каталога НЕ БЫЛО ЛИШНИХ ПРОБЕЛОВ ! А то иначе вы можете быть сконфужены, фактом что "ничего не получилось".
Стоит еще сказать, что исходники сервера "внутри себя" содержат ВСЕ необходимые для его сборки сторонние библиотеки. Сам ANT скрипт написан "как правило" без ошибок, когда-то ошибки наверное и бывали, но мне встречаться с таким не приходилось. Приходилось встречать ошибку в одной из версий, когда при последующем запуске "свеженького" JBoss - "ТомКат" падал при загрузке сервера и поэтому Web-контейнер НЕ поднимался.
Сборка сервера.
Запускаем файл - D:\jboss-3.2.1-src\build\build.bat - Именно из этого каталога ! При этом НИЧЕГО в нем не меняем - оставляем его исходным.
После этого, если путь к JDK был настроен правильно, в консоль окна будут сыпаться лог-сообщения. Признак успешного завершения компиляции такой:
BUILD SUCCESSFUL Total time: 2 minutes 34 seconds
Из каталога D:\jboss-3.2.1-src\build\output - можно "забирать свежачок". Время компиляции зависит от процессора и памяти, указанное время получено при первой сборке (при повторной немного меньше) на: WinXP Pro, Atlon XP 1.7, 512 Мб.
Что делать, если сборка не удалась?
Первое - еще раз проверить : set JAVA_HOME=... , второе - то что переменная указана в "нужном файле", остальные файлы менять НЕ надо.
Что же делать, если НЕ помогло? - Скорее всего менять JDK.
У меня был печальный случай, когда готовый сервер версии 3.2.1, выкачанный с сайта, НЕ запускался под JDK 1.3 на FreeBSD 4.?.?. Выпадала совершенно глупейшая ошибка при загрузке сервера. По типу ошибки можно было только понять, что она происходит на уровне JVM. Обследование форума сайта показал, что очень похожую по симптомам ошибку получило еще пару человек на похожей конфигурации. Т.к. сервер нужен был версии 3.2.1, то была предпринята попытка "сборки" из исходников. Эта попытка НЕ увенчалась успехом, сборка тоже падала с глупейшей ошибкой компиляции, при этом прекрасно собираясь на Windows. Из этого был сделан вывод, что JDK "сырое" и с багами. А так как данная версия JDK для указанной версии FreeBSD была "заморожена" и ее апдейтов или пачей к ней не предвидиться, то стало ясно, что "не судьба" и от затеи пришлось отказаться до лучших времен.
Основные компоненты Java Desktop System
Оконное окружение JDS основано на оконном окружении GNOME, сопровождается массой приложений для офисной работы и отличается фирменным стилем Sun. Пользователи, знакомые с GNOME, обнаружат хорошо спланированный, насыщенный цветами и интуитивный графический пользовательский интерфейс, позволяющий легко находить документы, открывать файлы, управлять меню, запускать приложения, настраивать GUI под пользователя и даже попытаться создавать приложения на Java под Linux.
Чтобы оценить все преимущества Java-приложений, необходим производительный и современный веб-браузер, поэтому в JDS включен самый лучший из известных - Mozilla 1.4, который способен выполнять любые известные веб-приложения. В числе прочих важных свойств этого обозревателя - встроенная система защиты данных пользователя и сетевая безопасность, а также защита от нежелательной почты и pop-up окон. Кроме того, новая система открытия многих страниц в одном окне приложения может существенно повлиять на производительность работы.
Mozilla сопровождается средствами воспроизведения аплетов и Java Web Start, позволяющими разрабатывать, тестировать и запускать Java-аплеты и приложения. Java Web Start позволяет также запускать обычные desktop-приложения по сети. Это не только упрощает поставку новых версий программы (необходимость в ней фактически отпадает), но и гарантирует обновления самой операционной среды JRE.
Сюита офисных приложений StarOffice 7, также включенная в JDS, позволяет вводить форматированный текст, электронные таблицы, презентации, графики и подключаться к базам данных. Более того, новые открытые Java-интерфейсы позволяют обращаться к объектам StarOffice и автоматически генерировать или обрабатывать существующие документы. Сам StarOffice также может быть расширен посредством создания Java-модулей, а также благодаря технологии, известной как StarOffice SDK.
В качестве среды выполнения Java выступает J2SE v.1.4.2_02 - самый свежий на момент выхода системы стабильный релиз, позволяющий выполнять тысячи существующих приложений. Помимо стандартных модулей, в поставку Java входят опции в виде Java Media Framework (JMF), а также кодеков MP3 и Ogg Vorbis, не входящих в JMF.
Последняя версия J2SE имеет расширенную функциональность Swing GTK+, которая обеспечивает динамическое изменение внешнего вида окон и управляющих элементов приложений. Это позволяет разрабатывать приложения, адаптирующиеся к среде выполнения и принимающие естественный для операционного окружения вид. Кроме того, пользователь может изменять внешний вид приложений - на программном уровне это делается вызовом всего одного метода UIManager.setLookAndFeel ().
Как уже упоминалось выше, JDS содержит универсальный текстовый редактор разработчика jEdit, который настраивается и программируется в очень большом диапазоне, чем-то напоминая emacs. Возможности включают автоотступы, расцветку и выделение синтаксиса, встроенный макроязык и расширяемую на основе plug-in'ов архитектуру. Многие макросы и расширения уже включены в поставку. Поддерживаются многие кодировки, в том числе UTF8 и Юникод, а также "сворачивание" фрагментов текста для более продуктивной навигации по исходным текстам.
JDictionary - другой интересный продукт, идущий с JDS и сопровождаемый Open Source лицензией. Это английский словарь с возможностями перевода. Написанный на Java, JDictionary не зависит от платформы и имеет простой интуитивный интерфейс. Помимо прямой своей функциональности, приложение также может обновляться по сети и обновлять свои модули расширения (plug-ins).
JgraphPad - еще одно приложение с открытым кодом, оно предназначено для графического представления идей и программных архитектур. Графики представляются в виде XML-диаграмм, вы можете импортировать растровые изображения и создавать графики выполнения, UML-диаграммы, карты и добавлять снимки экрана к документации. Графические объекты автоматически располагаются в области видимости. Предусмотрена поддержка печати и отслеживание версий.
JDiskReport представляет собой утилиту для отслеживания дисковой памяти, занимаемой теми или иными файлами, папками и приложениями. Статистика по использованию диска представляется в виде наглядных графиков и таблиц.
Поддержка технологии Java
Поскольку мировые корпорации, в основном, уже определились с использованием Java в качестве основной операционной платформы для бизнес-приложений и, в частности, для веб-сервисов, то вполне естественно, что современная операционная среда штатно должна включать JRE как один из своих компонент. Встроенная в JDS исполнительная среда Java позволяет легко интегрировать в десктоп как существующие, так и новые Java-приложения, будь то фронт-энд-приложения для доступа к базам данных, системы вертикальных коммуникаций CRM или просто новые утилиты.
Многие возможности JDS уже одобрены и поддержаны многими неправительственными и государственными организациями мира, в частности Independent Software Vendors (ISV) - независимыми разработчиками ПО, в числе которых - China Standard Software Company, Macromedia, Real, Adobe и множество других. В связи с ростом рынка офисных инсталляций Linux многие компании получают редкий шанс выйти со своими продуктами из замкнутого круга разработок под Windwos и Macintosh на рынок открытых систем.
Sun на страже корпоративной безопасности
Поскольку безопасность в корпоративном секторе особенно важна, Sun уделила немалое внимание безопасности - как встроенной в механизмы Java, так и предоставляемой операционной средой Linux. Для приложений Java технология "песочницы" предохраняет пользователя от опасности вирусной атаки и других воздействий приложения на среду - в то время как Linux добавляет дополнительные механизмы защиты на уровне файловой системы, причем делает это значительно лучше, чем такие системы, как Windows. * * *
В результате новая коммерческая версия Java Desktop System включает все компоненты, необходимые для производительной и безопасной работы корпоративного пользователя в среде Linux. А специальная "вступительная" цена в $50 за полный пакет программного обеспечения на один компьютер (или $25 на каждого пользователя), плюс полная годовая поддержка от такого известного провайдера услуг, как Sun, выглядит как условно-бесплатное распространение.
Ставка на JDS может быть тем более интересной, если учесть, что в ближайшем будущем Sun в сотрудничестве с другими компаниями намеревается создать или адаптировать для JDS множество Java-приложений для обмена документами, сообщениями, медиа и идеями в открытом и безопасном окружении.
По материалам .
document.write('');
Новости мира IT:
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
Компания. Мы предлагаем: по выгодной цене. Услуги. |
Sun: от CDE к Java Desktop
Арсений Чеботарев,
Имя Sun широко известно благодаря значительному технологическому вкладу компании в мировой компьютинг - в том числе, благодаря оконной системе CDE, ставшей прототипом оболочки KDE. Новая инициатива Sun - создание программируемого графического интерфейса для Linux на основе Java - Java Desktop
Доступная с января 2004 года, Java Desktop System сразу же получила статус коммерческого продукта, предлагаемого по цене от $100 для одной рабочей станции или $50 долларов при покупке лицензии для каждого сотрудника компании. JDS использует открытый код и открытые технологии, тщательно подобранные Sun. В основе JDS - известная оболочка GNOME, но снабженная всем необходимым для выполнения Java-приложений, так что они могут выполняться наравне с традиционными программами.
Помимо последней версии исполнительной среды Java Runtime Engine и Java Web Start, JDS включает: браузер Mozilla версии 1.4; набор офисных приложений StarOffice 7; почтовый клиент и организатор Evolution 1.4.
В JDS включены дополнительные Java-приложения, призванные упростить выполнение типичных офисных задач.
В дополнение к весьма привлекательной цене компания предлагает один год поддержки с гарантией бесплатных обновлений, 60-дневную поддержку инсталляции, доступ к онлайновой knowledge base, онлайновые тренинги и другие программы поддержки. Эти меры, в первую очередь, призваны заинтересовать корпоративных пользователей и предложить достойную замену MS Windows / MS Office по значительно более выгодной цене и с хорошей корпоративной поддержкой.
Java наконец-то стала Mobile
Олег Ремизов,
Язык Java, как известно, изначально создавался для мобильных клиентов, работающих в гетерогенной среде. Проблема была в самой среде, точнее в ее отсутствии... но ситуация наконец-то изменилась.
В последнее время появилось огромное количество моделей мобильных телефонов, оснащаемых новыми модными возможностями. Если рассмотреть хронологию появления этих функций, можно отметить, что первым (ну, первым вряд ли, но главным — это точно. Прим. ред.) стало то, что практически все телефоны, стали оснащаться JVM, точнее сказать ее урезанной версией (J2ME). Таким образом производители этих устройств заявили, что телефон перестал быть ограниченным в своих возможностях устройством с жестко заданной функциональностью — пользователь может самостоятельно добавить то программное обеспечение, которое сочтет необходимым.
На практике это было больше похоже на PR-акцию. Мало кому приходило в голову искать дополнительные игры для своего мобильного устройства — слишком уж некрасивой и угловатой была графика на черно-белом экране телефона.
Вторым шагом в этом направлении было добавление GPRS-модема и широкое распространение этого стандарта в мире. Таким образом мобильные телефоны получили возможность выхода во всемирную паутину по сравнительно дешевым тарифам.
Последним — и, пожалуй, самым желанным для потребителей — стало появление моделей с цветными экранами с разрешением 128х128 пикселей и улучшенным звуком (так называемой полифонией). Несмотря на внушительные цены этих устройств, они пользуются фантастической популярностью у потребителей. Для них появилось великое множество новых java-игр и полезных программ.
Словом, с появлением такого рода устройств с уверенностью можно говорить о рождении нового рынка для программного обеспечения.
Последним шагом стало скрещивание классического PDA с мобильным телефоном. То есть теперь внутри мобилки находится полноценная операционная система Symbian — и программисты, естественно, не ограничены больше java-«песочницей», а могут писать для этих устройств C++ приложения. Эта ОС так же пришла из мира PDA.
Инициатором рождения смартфонов (так окрестили новые устройства), как и внедрения Symbian в свои мобильные устройства, стала компания Nokia. Сейчас еще несколько производителей лицензировали это новшество. Не остается в стороне и Microsoft — инженеры этой фирмы, хоть и с некоторым запозданием, предложили собственную платформу для мобильных устройств. Однако, несмотря на все усилия гиганта софтверной индустрии, инициатива была потеряна — доминирующие производители уже выбрали Symbian в качестве стандарта де-факто.
Несмотря на появление возможности написания C++ приложений для отдельных hi-end моделей, Java остается и останется основной платформой. Для такого положения вещей существует несколько причин. Java-приложения являются более переносимыми с устройства на устройство, чем приложения, реализованные с помощью С++. Если вы не будете использовать специальные расширения Java API, выходящие за стандарт, и будете так кодировать ваши приложения, чтобы они были независимы от разрешения экрана, то переносить их не потребуется вообще. Что касается практики создания коммерческих приложений, то такие условия невыполнимы. Так что при переносе с платформы на платформу, как правило, придется потрудится. Устройства с отсутствием встроенных операционных систем будут существовать, поскольку большинству потребителей вполне достаточно уже реализованных возможностей, и они не собираются переплачивать за ненужную функциональность. То есть Java-приложения остаются единственным способом расширить функциональность таких телефонов. Последний стандарт MIDP2.0 значительно расширяет возможности Java-приложений, и практически возможности при написании таких приложений ничем не отличаются от возможностей для написания приложений с помощью C++. К сожалению, устройств, которые поддерживают этот стандарт, пока еще очень мало. Мне известно всего две модели: Nokia 6600 (последняя из 60-й серии) и Ericsson P800/P900. Кстати, на форумах было много нареканий относительно качества реализации стандарта MIDP2.0 в этих устройствах. Цены на такие телефоны просто фантастические. Но постепенно парк таких устройств будет расширяться, все дефекты будут устранены, а цены упадут до приемлемого уровня. Вследствие специфики мобильных устройств нет значительной разницы в скорости выполнения java- и native-приложений. Не зря большинство игр для мобильных устройств hi-end класса (где возможно использование C++ приложений) все же выполнены в виде java-приложений.
Программа для выполнения под управлением JVM мобильного телефона или другого мобильного устройства, называется Midlet. Для разработки таких программ нам также потребуется специальный инструментарий. Следуя ссылкам на Java Developer Connection с адреса , вы можете скачать J2ME Wireless Toolkit, там же вы найдете полную API-документацию для CDC, профиля Foundation Profile и CLDC/MIDP. Это все что вам потребуется для разработки своих приложений.
Существует достаточно много SDK, ориентированных на разработку приложений конкретно для той или иной мобильной платформы. Отличаются они, главным образом, разрешением экрана эмулятора, а также поддержкой дополнительного Java API, характерного для той или иной платформы. Прежде чем скачивать инструментарий, проверьте, нет ли в вашей среде разработки предустановленного J2ME Wireless Toolkit. Кроме того, некоторые среды разработки имеют plug-ins для работы с J2ME Wireless Toolkit. К примеру, все последние версии JBuilder обладают такой функциональностью — и, следовательно, скачивать вам ничего не придется. Просто создайте новое приложение на базе заготовки, входящей в среду разработки, и приступайте к работе.
В поставке с J2ME Wireless Toolkit идет несколько демонстрационных приложений, что значительно упрощает ознакомление с принципами разработки подобных приложений. Мы рассмотрим создание собственного приложения классической игры «крестики-нолики». Вообще-то, реализация этой игры уже присутствует в Nokia SDK, но я решил сделать собственную, оригинальную версию. Тем более что и алгоритм несложен, и реализация его не займет много времени.
Минимальное Midlet-приложение состоит из двух классов. Первый — это класс, наследующий функциональность класса MIDlet. Главный класс, в котором присутствует точка входа в приложение. Второй — это экран приложения. Класс, поддерживающий интерфейс Displayable.
На практике в любом приложении существует несколько экранов. Например, в нашем случае — два: экран игры и экран about. Все, что необходимо сделать для реализации приложения, это рисовать на экране, реагировать на нажатия клавиш и меню, а также при необходимости переключать экраны.
Классы, реализующие интерфейс Displayable, могут быть двух типов: форма — предназначена для расположения на ней немногочисленных, но, тем не менее, весьма полезных контролов; Canvas.
В этом примере мы используем два класса унаследованных от Canvas. Как следует из названия, этот класс предназначен для рисования на нем. Класс, наследующий свою функциональность от MIDlet, приведен ниже:
public class MIDletHello extends MIDlet {
public void startApp() {
// В момент старта приложения нужно произвести
// определенные действия
}
public void pauseApp() {
// Пользователь переключился на другое приложение и
// работа временно приостановлена
}
public void destroyApp(boolean unconditional) {
// Завершение работы приложения, в том числе
// обусловленное каким-либо непредвиденным событием
}
public static void quitApp() {
// Пользователь нажал команду Exit
}
}
Как можно видеть присутствуют все методы необходимые для реализации жизненного цикла приложения. Правда, реализацию методов я оставил пустой, для того чтобы не путать читателя и дать общую картину. В реальном приложении естественно этого делать не следует. Я думаю, что описывать предназначение каждого из методов и когда он вызывается более подробно, не имеет смысла. Для того чтобы получить более детальную информацию обратитесь к исходному коду приложения на компакт-диске.
Типичный класс Canvas выглядит так:
pr
public class MyCanvas extends Canvas implements CommandListener {
public MyCanvas() {
// Инициализация необходимых переменных происходит
// здесь. Например, мы хотим создать еще одну команду
// меню:
addCommand(new Command("Exit", Command.EXIT, 1));
}
public void commandAction(Command command, Displayable displayable) {
// Здесь происходит обработка команд меню.
}
protected synchronized void keyPressed(int keyCode) {
// Здесь происходит перехват нажатий клавиш управления
// телефона
}
otected void paint(Graphics g) {
// Рисуем здесь
}
} // end of class
Для получения более детальной информации обратитесь к исходному коду приложения на компакт-диске. Для того чтобы помочь вам разобраться с исходным кодом, ниже мы разместили некоторые комментарии.
Логика игры реализована в классе Engine. Алгоритм игры достаточно прост, мы обходим все варианты комбинаций в двумерном массиве, отражающем текущее состояние игрового поля. При этом, анализируя массив из трех полей — сечение (две диагонали, три вертикали и три горизонтали), мы расставляем приоритеты. Если приоритет встретившейся комбинации выше приоритета текущей комбинации, то встретившаяся комбинация становится текущей.
Ниже, c краткими пояснениями, приведено тело функции, которая является сердцем алгоритма:
protected boolean analaize()
{
// считаем,сколько в одном ряду крестиков, ноликов, пустых мест:
int x_counter = 0;
int o_counter = 0;
int e_counter = 0;
for (int i = 0; i < buffer.size(); i++)
{
Cell cell = (Cell)buffer.elementAt(i);
if (cell.value == STATE.E)
{
e_counter++;
}
if (cell.value == STATE.O)
{
o_counter++;
}
if (cell.value == STATE.X)
{
x_counter++;
}
}
// В зависимости от количества крестиков, ноликов или пустых
// мест определяем комбинацию (тип состояния) — searchState
int _searchState = SEARCH_STATE.ANY;
// user win
if (x_counter == 3)
{
_searchState = SEARCH_STATE.X_X_X;
this.gameState = GAMESTATE.USERWIN;
return true;
}
// engine can win :
if ((o_counter == 2)&&(e_counter == 1))
{
_searchState = SEARCH_STATE.O_O_E;
}
// danger - user can win :
if ((x_counter == 2)&&(e_counter == 1))
{
_searchState = SEARCH_STATE.X_X_E;
}
// good combination :
if ((o_counter == 1)&&(e_counter == 2))
{
_searchState = SEARCH_STATE.O_E_E;
}
// also good combination :
if (e_counter == 3)
{
_searchState = SEARCH_STATE.E_E_E;
}
// Если приоритет новой комбинации больше приоритета
// текущей комбинации,определяем новую комбинацию как
// текущую и запоминаем ее в переменных класса:
if (this.searchState < _searchState)
{
this.searchState = _searchState;
this.searchBuffer = new Vector();
// copy vector:
for (int i = 0; i < this.buffer.size(); i++)
{
this.searchBuffer.addElement(this.buffer.elementAt(i));
}
}
return false;
}
После завершения обхода ставим нолик в последней запомнившейся комбинации с наивысшим приоритетом. Логика сделана с тем расчетом, чтобы при желании ее можно было использовать в более сложной игре Go. Класс Fields отвечает за рисование игрового поля и содержит экземпляр класса Engine. Класс MyCanvas отвечает за перехват событий клавиатуры и меню, всю логику прорисовки экрана он делегирует экземпляру класса Fields. Вот так выглядит запущенное приложение на эмуляторе из состава J2ME Wireless Toolkit.

Работающее приложение, запущенное на эмуляторе из состава J2ME Wireless Toolkit
document.write('');
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
Выбор компании для деньгами |
NET vs. Java
Олег Ремизов,
Что бы там ни говорили, но сегодняшний мир вычислений ориентирован в основном на сетевые приложения. В основе этих приложений лежит модифицированная архитектура клиент-сервер - так называемая трехуровневая архитектура. Отличительная ее черта - наличие на стороне сервера приложения, которое, собственно, и реализует бизнес-логику в среде сервера приложений. Приложение взаимодействует с сервером баз данных с одной стороны и с удаленной клиентской частью, которая обычно выполняется в среде веб-браузера или приложения с GUI-интерфейсом.
Распространение трехуровневой архитектуры повлекло за собой создание двух конкурирующих технологий - J2EE и COM+. И та, и другая представляют собой серверы приложений, где реализована большая часть логики, необходимой для обеспечения связки КЛИЕНТ-СУБД. Каждый из этих серверов предоставляет в распоряжение программиста набор правил, которым он должен следовать при реализации логики приложения. Другими словами, современный сервер приложений является хранилищем компонентов, реализованных в соответствии с определенными правилами.
Для чего вообще нужен сервер приложений и почему нельзя обеспечить прямой доступ пользователя к данным? Тому есть, по меньшей мере, три причины.
Прежде всего, для кэширования данных, которое позволяет значительно уменьшить нагрузку на сервер баз данных - и, соответственно, на компьютер, являющийся физическим хранилищем ваших данных. Конечно, это работает при условии, что сервер приложений установлен на другом компьютере.
Вторая причина, по которой эта технология сегодня столь популярна, это возможность как изоляции бизнес-логики от приложения-клиента, так и избежания написания сложных хранимых процедур на серверной стороне. Конечно, сегодня различные диалекты SQL, реализованные на серверах баз данных, позволяют делать с данными все или почти все. Практически это достаточно мощные процедурные языки, построенные на основе ANSI SQL92.
Но существуют, как минимум, три недостатка реализации логики с помощью хранимых процедур.
Первый и основной недостаток заключается в том, что необходим программист, который знаком с тем или иным диалектом SQL, для того чтобы держать бизнес-логику вашего приложения под контролем. Кроме всего прочего, SQL-скрипты достаточно сложны для понимания - даже если вы их сами написали всего пару дней назад. Как известно, SQL-код слабо структурирован и очень ограниченно поддерживает повторное использование кода, поэтому проще писать и сопровождать бизнес-логику на более мощном современном объектно-ориентированном языке.
Вторая причина: каким бы мощным ни был диалект SQL, реализованная на нем логика все равно будет работать в десятки, а то и в сотни раз медленнее, чем логика, реализованная на Java, C++ или C#.
Еще одна причина: слабая переносимость нестандартного SQL-кода. Написанием бизнес-логики на северной стороне вы фактически отрезаете себе путь к использованию других баз данных или делаете его очень дорогостоящим. Гораздо проще потом убедить клиента в том, что СУБД, которая используется в вашем приложении, лучше той, которая у него уже есть (хорошо, если у него вообще ничего нет), чем переписывать вашу логику для другого сервера баз данных. Иногда это просто невозможно.
То есть, говоря проще, приложение, построенное по современной архитектуре, должно использовать базу данных в режиме ANSI SELECT/UPDATE и не иметь значительной логики на стороне клиента. Вся логика должна быть реализована в промежуточном слое, называемом сервером приложений.
Когда принимается решение о применении трехуровневой архитектуры, следующим вопросом, который приходится решать, является вопрос о том, какой сервер приложений использовать. Можно вообще реализовывать свой сервер приложений - и такой подход в последнее время становится все более применяемым. Автор этой статьи знает, по крайней мере, два случая реализации таких серверов киевскими софтверными компаниями. В любом случае, решение в пользу использования того или иного сервера приложений или же реализации своего собственного ставит следующий вопрос: какой язык - а точнее, платформу - выбрать для реализации компонентов логики сервера приложений или самого сервера приложений?
Естественно, если существует жесткая привязка к платформе UNIX, то выбор сервера приложений или платформы для его реализации на сегодняшний день можно считать уже предопределенным - это Java2. В случае принятия решения об использовании готового сервера приложений будет выбран сервер стандарта J2EE - очевидно, что реализация компонентов внутренней бизнес-логики будет выполнена с использованием Java2.
Если вы собираетесь развернуть ваш сервер приложений на платформе Windows, то у вас есть альтернатива в виде C# и COM+. То, что COM+ работает в 2-4 раза быстрее, чем его аналоги, реализованные в соответствии с J2EE-стандартом, подтверждают многочисленные тесты, проделанные как сторонними фирмами, так и самой Microsoft. Объясняется это соотношением нейтив- и интерпретируемого кода: сервера приложений стандарта J2EE сами реализованы с использованием Java2, в то время как С#, напротив, служит только диспетчером, главная задача которого - вызов сравнительно быстродействующего исполнимого нейтив-кода COM+.
В случае принятия решения о создании своего сервера приложений, вы получаете возможность создать именно то, что вам нужно, после чего можете оптимизировать свое творение для нужных вам целей для каждого конкретного случая. Такой подход дает много преимуществ - но, в то же время, он не лишен недостатков.
Иногда программисты и вовсе отказываются от базы данных в пользу создания бизнес-классов и их последующей сериализации на диск. В случае не очень большого объема данных такой подход позволяет сэкономить на стоимости иногда не очень дешевого сервера баз данных. К тому же, такое приложение в некоторых случаях быстрее, чем приложение, использующее сервер баз данных или локальную СУБД в качестве хранилища данных.
Описание тестового приложения и условий тестирования
Для сравнения двух основных платформ для создания серверных приложений автор создал идентичные тестовые приложения на C# и Java. Для компиляции и запуска C# приложения использовалась майкрософтовская реализация DOT.NET машины Rotor версии 1.0. Для компиляции и запуска Java2-приложения использовалась Java-машина и компилятор, входящие в состав JDK 1.3.
Основные характеристики компьютера, на котором происходило тестирование: Pentium II 366, 256 RAM. Операционная система - Windows 2000 SP2 Workstation.
Тестирование проводилось для ста тысяч объектов. Бизнес-класс Man имеет в своем составе три поля: Name, Sex и Age. Два из них имеют тип String, а последнее - тип Integer. Инициализация всех трех полей происходит в конструкторе объекта.
Также определены две функции сравнения объекта - по имени и возрасту.
В первом цикле приложения происходит создание всех бизнес-объектов и их сохранение внутри коллекции ArrayList. Во втором цикле происходят итерации по этой коллекции с вызовом функции сравнения объекта по имени. Когда пятидесятитысячный объект найден, происходит выход из цикла. Третий цикл делает то же, что и второй,- с той лишь разницей, что сравнение проводится по возрасту. В общей сложности происходит сто тысяч итераций по коллекции. Затем - запись всех объектов на диск. ArrayList очищается посредством вызова метода Clear (), после чего происходит чтение всех объектов с диска и сохранение их в ArrayList.
Для оценки общей потенциальной производительности вашего серверного приложения вам необходимо оценить скорость таких критичных операций: создания бизнес-объектов, скорость работы со строками, скорость сохранения бизнес-объектов в коллекции, а также поиска бизнес-объекта с соответствующими данными внутри этой коллекции.
Вторая часть теста должна тестировать встроенную сериализацию и десериализацию бизнес-объектов, которая будет происходить при старте вашего сервера, в течение его работы, а также при ее завершении. Конечно, стандартная сериализация - это не самый быстрый и надежный способ сохранения объектов на диск, поскольку при этом интенсивно используются рекурсивные алгоритмы и информация времени выполнения. Использование рекурсивного алгоритма может привести к переполнению стека виртуальной машины. Доступ к информации времени выполнения для определения типа данных тоже является достаточно медленной операцией, связанной с обработкой строк. Но в большинстве случаев, если сериализуемыми являются только бизнес-объекты, а не хранящие их структуры данных (то есть обход коллекции, хранящей бизнес-объекты, происходит посредством циклов), этот механизм дает вполне приемлемые результаты при достаточно простой логике процесса.
и не требует особых пояснений
Код приложений практически идентичен и не требует особых пояснений - за исключением одного момента, а именно: как сделать класс сериализуемым (то есть, говоря русским языком,- записываемым на диск).
Для того чтобы сделать объект записываемым в Java2, необходимо пометить его как объект, реализующий интерфейс implements Serializable. Это указывает компилятору, что необходимо встроить в байт-код объекта байт-код, отвечающий за сохранение объекта этого типа на диск. В C# код сохраняемого объекта должен быть помечен с помощью атрибута [Serializable] перед определением класса - то есть принцип остается тем же, но сам механизм сохранения выглядит немного иначе. Дело в том, что в C# вы сами можете определить свой форматер - класс, который отвечает за формат хранения данных на диске. Так, кроме стандартного бинарного форматера, в C# также предусмотрен форматер, сохраняющий данные в XML-формате, что может быть весьма наглядным, но далеко не быстрым способом представления данных. По умолчанию, в Java2 данные сохраняются в бинарном виде - других форматов хранения данных не предусмотрено.
Результаты тестирования
Для ста тысяч объектов были получены следующие результаты.
Для работы с объектами в памяти мы получили приблизительно 700 мс для C# приложения и 2400 мс - для Java2-приложения. Получается, что DOT.NET-машина при данном количестве объектов работает с объектами в памяти втрое быстрее, чем Java-машина. Возможно, если бы бизнес-класс в C# был описан как структура, мы получили бы еще большую разницу в скорости.
Тестирование скорости при сохранении/чтении данных на диск, напротив, дало не лучшие результаты для C#-приложения. Оно записывало на диск и читало с диска 100000 объектов в течение приблизительно 42-х секунд. Java-приложение справилось с этой же задачей за промежуток времени, равный всего 18-ти секундам,- то есть более чем вдвое быстрей.
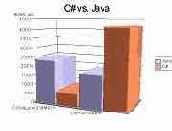
Также имеет смысл отметить разницу в размере файлов, созданных приложениями. Для приложения Java2 этот показатель составил 2688961 байт, а для приложения C# - 16188890 байт. Компания Sun Microsystems очень хорошо оптимизировала эту часть своей технологии. Хотя надо отметить, что эти результаты нельзя считать вполне корректными, поскольку в наших объектах было очень много повторяющихся данных. В реальных объектах вашего приложения степень корреляции межу ними будет гораздо ниже - тем не менее, она не исчезнет совсем. Поэтому можно предположить, что весьма значительная разница в скорости все равно останется. Для иллюстрации сказанного ниже приводится диаграмма временных соотношений (см. рисунок).
Приведенные ниже выводы носят самый
Приведенные ниже выводы носят самый общий характер и для того, чтобы принять правильное решение относительно выбора платформы, вам необходимо будет сделать свои собственные заключения. Воспользуйтесь результатами этого теста, модифицируйте его так, чтобы он более точно отражал вашу предметную область. Не забывайте также и о трудоемкости того или иного решения. Если серверное приложение должно отвечать требованию повышенной отказоустойчивости, то вам необходимо будет обеспечить механизм сохранения данных бизнес-объектов на диск через некоторые постоянные интервалы времени. Чем выше интенсивность этого процесса, тем надежнее ваше приложение будет заботиться о сохранении данных клиента.
Если учесть, что затраты времени на поиск данных в коллекции можно сократить, используя связку "сортировка - бинарный поиск", а также то, что затраты времени при сохранении данных на диск значительно выше затрат времени при осуществлении работы с объектами в памяти,- то для большинства серверных приложений более предпочтительным выбором будет использование платформы Java2.
Однако автор при этом не исключает возможности реализации своих собственных механизмов сохранения данных на диск для приложений, реализованных с использованием C#. В конечном счете, все зависит от бюджета вашего проекта. Если вам нужно построить real-time приложение, где необходима, прежде всего, скорость реакции на сигналы, а устойчивость данных не имеет большого значения, то тут лучшим выбором будет использование C#. Конечно, в этом случае разработка приложения на C++ даст лучшие результаты, если у вас достаточно денег и времени. Еще один плюс в пользу C# - это то, что в месте, где у вас возникают проблемы с быстродействием системы C#, код может быть с легкостью заменен кодом С++. Конечно, это возможно и в Java, однако при этом трудозатраты будут неизмеримо выше.
При тестировании не был учтен такой важный аспект разработки серверного приложения, как скорость передачи объектов через сеть, что объясняется простым отсутствием у автора условий для такого тестирования.
В идеальном случае необходима локальная сеть с полным отсутствием всякой активности в ней. Но, учитывая данные эксперимента с сериализацией данных на диск, можно предположить, что здесь Java2 тоже покажет лучшие результаты.
Недавно Microsoft выпустила новую версию DOT.NET-машины 1.1 - возможно, при тестировании приложения с ее помощью мы бы получили лучшие результаты. Кроме того, сегодня существует JDK 1.4, включающий более оптимальную версию Java2-машины. Вы можете произвести дополнительное тестирование самостоятельно, воспользовавшись кодом приложений, приведенных на диске. Проекты тестовых приложений выполнены с использованием сред разработки JBuilder7 и Visual Studio.NET соответственно.
document.write('');
Если при программировании Windows-приложений чаще применяется платформа .NET, то для мобильных устройств Java вне досягаемости.
02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
Здесь есть Вас приятно удивят магазин SUNLENS.RU. |
Сортировка таблицы средствами JavaScript
,
Достаточно часто пользователям интернет приходится сталкиваться с большим объемом информации, представленным в виде таблицы. Не менее часто требуется получить результаты в ином порядке, чем они представлены первоначально. Большинство web-мастеров решает эту проблему применением сортировки на сервере, для чего используется перезагрузка страницы. Действительно, серверные языки предоставляют гораздо больше возможностей отсортировать многомерный массив по определенному значению, чем скриптовые языки, выполняющиеся непосредственно на стороне клиента. Решение сортировать данные на стороне сервера вполне оправданно с точки зрения трудозатрат программиста, так как многие серверные языки имеют встроенные функции сортировки многомерных массивов, и поэтому не требуется вдумываться в алгоритмы сортировки, что-то изобретать или перестраивать алгоритм под свои нужды. Но все-таки такое решение не оправдано, если подходить к этой проблеме с точки зрения пользователя. Вначале посетителю сайта требуется дождаться достаточно длительной загрузки страницы, просмотреть результаты, нажать на кнопку "Отсортировать" и... опять дожидаться, пока сервер закончит работу и вернет результат. Такие множественные перезагрузки страницы никак не способствуют популярности сайта у посетителя. В конце-концов, устав дожидаться очередной загрузки страницы, или испугавшись лишнего траффика, он покинет сайт в поисках более лояльного к нему web-мастера. Решением данной проблемы, а именно эффективной сортировки данных и формирования результирующей таблицы, я и предлагаю заняться в этой статье. А в качестве примера данных будет выступать информация о книгах: дата написания, название книги и ее автор.
Начнем с функции fillArray, которая и будет эмулировать многомерный массив, а вернее создать класс-объект с членами - данными многомерного массива. Приведем ее код:
Листинг 1:
1 function fillArray( years, books, authors ) { 2 authors = upCs( authors, " " ); 3 authors = upCs( authors, "-" ); 4 books = upCs( books, "" ); 5 6 this.years = years; 7 this.yweight = weight( years ); 8 this.books = books; 9 this.bweight = weight( books ); 10 this.authors = authors; 11 this.aweight = weight( authors ); 12 }
Разберем данные по строкам. Во второй строке вызывается функция upCs с параметром authors и пробелом в качестве второго параметра. Функция upCs создает заглавные буквы в начале строки и перед каждым вхождением второго аргумента. Эта функция была написана исключительно потому, что не все обрабатывают данные должным образом и вполне могут написать имя писателя, например, с маленькой буквы. Применение такой функции устраняет возможную ошибку программиста в заполнении массива данными, а также позволяет быть уверенным, что в функции сортировки не будет неверного сравнения заглавных букв со строчными. Впрочем, если вы уверены в том, что данные будут занесены верно, можете убрать вызовы этой функции:
Листинг 2:
1 function upCs( str, param ) { 2 var tmpStr = str.substring( 0, 1 ).toUpperCase() + str.substring( 1 ); 3 if( !param ) 4 return tmpStr; 5 var separator = tmpStr.indexOf( param ); 6 var retStr = tmpStr; 7 if( separator != -1 ) 8 retStr = tmpStr.substring( 0, separator ); 9 10 while( separator != -1 ) { 11 tmpStr = tmpStr.substr( separator + 1, 1 ).toUpperCase() + tmpStr.substring( separator + 2 ); 12 separator = tmpStr.indexOf( param ); 13 if( separator != -1 ) 14 retStr += param + tmpStr.substring( 0, separator ); 15 else 16 retStr += param + tmpStr; 17 } 18 19 return retStr; 20 }
Эта же функция, вызванная с пустым вторым аргументом, возвращает результат с заглавной буквой только в начале строки. Теперь обратимся к строке 7, листинга 1. Здесь вызывается функция weight, которая возвращает числовые значения каждого символа аргумента в виде массива. Для чего я ее написал? Дело в том, что коды символов русского алфавита в браузере идут последовательно, кроме кода символа буквы "ё". Код этого символа больше кодов символов остального алфавита, поэтому приходится присваивать такое "весовое" значение этому символу, которое соответствовало бы его позиции в алфавите. Вот код этой функции:
Листинг 3:
1 function weight( str ) { 2 var retArray = new Array(); 3 4 for( var i = 0; i < str.length; i++ ) { 5 var tmp = str.charCodeAt( i ); 6 if( tmp >= 1046 && tmp < 1078 ) 7 tmp++; 8 else if( tmp == 1025 ) 9 tmp = 1046; 10 else if( tmp >= 1078 ) 11 tmp++; 12 else if( tmp == 1105 ) 13 tmp = 1078; 14 retArray[ i ] = tmp; 15 } 16 17 return retArray; 18 }
Ну что же, функции, необходимые для создания нашего многомерного массива готовы. Осталось создать массив и заполнить его данными:
Листинг 4:
1 var txt = []; 2 txt[ 0 ] = new fillArray( "1959", "фрейд", "сартр жан-поль" ); 3 txt[ 1 ] = new fillArray( "1940", "подростки", "сэлинджер джером" ); 4 txt[ 2 ] = new fillArray( "1946", "пена дней", "виан борис" ); 5 txt[ 3 ] = new fillArray( "1948", "осадное положение", "камю альбер" ); 6 txt[ 4 ] = new fillArray( "1899", "об иноческой жизни", "рильке райнер мария" ); 7 txt[ 5 ] = new fillArray( "1849", "аннабель Ли", "по эдгар" ); 8 txt[ 6 ] = new fillArray( "1917", "дагон", "лавкрафт говард" ); 9 txt[ 7 ] = new fillArray( "1915", "процесс", "кафка франц" ); 10 txt[ 8 ] = new fillArray( "1989", "египет Рамсесов", "монтэ пьер" ); 11 txt[ 9 ] = new fillArray( "1932", "мастер и Маргарита", "булгаков михаил" );
Обратить внимание стоит лишь на то, что года, когда были написаны книги, я передаю в функцию в качестве строкового параметра, а не числового. Делается это для того, чтобы не писать несколько функций сортировки.
Насколько быстр такой метод заполнения массива? На компьютере со средней производительностью загрузка 1000 элементов происходит за 450 - 800 миллисекунд. Но поскольку пользователь будет получать массив такого размера не сразу, а по частям, и размер этих частей будет сильно зависеть от скорости его соединения с интернет, то время, затрачиваемое на создание элемента массива и определение весовых значений его данных, будет незаметно пользователю.
Я подошел к самой интересной части данной статьи, а именно - к непосредственной работе с данными. В качестве функции сортировки данных я выбрал сортировку Хоара, которая, как мне кажется, наиболее соответствует поставленной задаче в начале статьи. Вот ее код, нюансы которого рассмотрю несколько более подробно.
Листинг 5 :
1 function quickSort( l, h, type ) { 2 var low = l; 3 var high = h; 4 var rt = eval( "txt[ " + Math.round( ( l + h ) / 2 ) + " ]" ); 5 var middle = new fillArray( rt.years, rt.books, rt.authors ); 6 7 do { 8 9 while( isLow( eval( "txt[ " + low + " ]" ), middle, type ) ) 10 low++; 11 12 while( isLow( middle, eval( "txt[ " + high + " ]" ), type ) ) 13 high--; 14 15 if( low <= high ) { 16 var temp = txt[ low ]; 17 txt[ low++ ] = txt[ high ] 18 txt[ high-- ] = temp; 19 } 20 } while( low <= high ); 21 22 if( l < high ) 23 quickSort( l, high, type ); 24 if( low < h ) 25 quickSort( low, h, type ); 26 }
В листинге 5 приведена классическая сортировка Хоара, но с небольшими модификациями. На этих модификациях я и хочу обратить внимание прежде всего. ИтаК, посмотрим на строки 4-5. Здесь создается новый элемент на основании данных элемента массива, который берется как среднее значение между границами цикла сортировки. Почему пришлось внести такую модификацию? Почему нельзя было написать классически, как и положено в сортировке Хоара: var middle = eval( "txt[ " + Math.round( ( l + h ) / 2 ) + " ]" );? Дело в том, что здесь не получено значения элемента массива, как в классической сортировке, а есть только ссылка на него (хотя слово ссылка здесь не совсем уместно). При таком подходе дальнейшие действия теряют смысл. Немного отклонюсь от темы моей статьи и разъясню этот момент. Приведу следующий листинг:
Листинг 6 :
1 function cls() { 2 this.member = "value"; 3 } 4 5 var x = new cls(); 6 var y = x; 7 alert( "x.member = " + x.member + ", y.member = " + y.member ); 8 x.member = "new value"; 9 alert( "x.member = " + x.member + ", y.member = " + y.member );
Что происходит после того, как на восьмой строке было присвоено члену класса новое значение? Изменится ли только значение в переменной x? Нет, изменится значение в обеих переменных. Дело в том, что присваивания значения созданного пользовательского класса не происходит. Попробую провести похожую аналогию со ссылками в языке С++. Я не получу автономного значения, которое было бы независимо от оригинала. А получу своего рода ссылку на значение, которое подвержено изменениям из оригинальной переменной. Такая ссылка разрушает всю семантику сортировки Хоара, поскольку алгоритм требует сравнения в процессе сортировки с опорным значением середины диапазона элементов, а сам алгоритм в процессе работы может заменять значение, находящееся по адресу опорного элемента другим значением. Именно поэтому мне пришлось создать отдельное значение через оператор new. Конечно, это влечет дополнительные затраты процессорного времени на повторное определение "весовых" значений данных, но эти затраты достаточно минимальны. Впрочем, если у вас есть желание, вы можете модифицировать функцию fillArray так, чтобы она принимала шесть аргументов. В качестве трех последних аргументов можно заносить уже полученные ранее данные о "весовом" значении членов массива.
Итак, я выяснил зачем требуется создавать новый элемент в сортировке Хоара. Перейду теперь к строкам 9 и 12. Здесь в качестве сравнения значений элементов вызывается функция isLow, которая принимает в качестве аргументов два объекта для сравнения и третий аргумент - имя члена класса, по которому производится сортировка (внимательный читатель уже заметил этот третий непонятный аргумент в алгоритме Хоара). Приведу эту функцию сравнения:
Листинг 7 :
1 function isLow( low, high, type ) { 2 var len1 = low[ type ].length; 3 var len2 = high[ type ].length; 4 var length = len1 < len2 ? len1 : len2; 5 6 for( var i = 0; i < length; i++ ) { 7 var str1 = low[ type ][ i ]; 8 var str2 = high[ type ][ i ]; 9 if( str1 < str2 ) 10 return true; 11 if( str1 > str2 ) 12 return false; 13 } 14 15 if( len1 < len2 ) 16 return true; 17 return false; 18 }
Как видите, кроме принципа работы с самими элементами, ничего необычного не происходит. Здесь для обращения к членам класса используются квадратные скобки, как в массиве. Подробнее о таком способе работы с пользовательскими объектами можно прочитать у Дмитрия Котерова на http://dklab.ru в статье "Маленькие хитрости JavaScript". Упомяну лишь то, что касается непосредственно работы нашей функции. Следует обратить внимание на строки 7 - 8. Здесь используется необычный способ адресации элемента. Предположу, что значение аргумента type равно "yweight", то есть хочу отсортировать по годам и обращаюсь к массиву-члену класса, который содержит данные о "весовом" значении строки с числом года. То есть фактически я буду обращаться так: low.yweight[ i ]. В этой функции больше никаких сложностей не вижу, поэтому пойду дальше.
Во всем остальном функция сортировки полностью соответствует своему классическому варианту, о реализации которого написано большое количество статей, поэтому больше никаких вопросов, касающихся этой функции, здесь рассматриваться не будет. Я же перейду к заключающей части своей статьи и рассмотрю функцию создания таблицы на основе DOM (Document Object Model), а также функции выбора сортировки. Сразу возьму код, который должен быть между тегами body:
Листинг 8 :
1 <table id="table"> 2 <tr> 3 <td><a href="javascript:allocator( 'yweight' )">Год</a></td> 4 <td><a href="javascript:allocator( 'bweight' )">Книга</a></td> 5 <td><a href="javascript:allocator( 'aweight' )">Автор</a></td> 6 </tr> 7 <tbody id="tablebody"></tbody> 8 </table>
Здесь нет ничего сложного: в таблице присутствует аттрибут id = "table", чтобы из функции можно было обратиться к этому узлу. Также присутствуют строка с именами колонок и вызовом функции выбора сортировки и tbody с id = "tablebody". Зачем необходим tbody? Netscape Navigator 7.1 и вообще все браузеры на движке Gecko, а также Opera, не требуют этого элемента при динамическом создании таблицы. Но только вот этот элемент жизненно необходим, если вы хотите увидеть результат в браузере Internet Explorer. Если, создавая таблицу функциями DOM, вы пропустите создание такого элемента, то результата не увидите. Как создается таблица? Вот эта функция: Листинг 9 :
1 function createTable( cStart, cType, cSize, cChange ) { 2 var tabbd = document.getElementById( "tablebody" ); 3 4 if( !tabbd ) { 5 var table = document.getElementById( "table" ); 6 var tbody = document.createElement( "tbody" ); 7 tbody.id = "tablebody"; 8 table.appendChild( tbody ); 9 tabbd = document.getElementById( "tablebody" ); 10 } 11 12 while( tabbd.hasChildNodes() ) { 13 var tmp = tabbd.childNodes[ 0 ]; 14 tabbd.removeChild( tmp ); 15 } 16 17 for( var counter = cStart; eval( counter + cType + cSize ); eval( "counter" + cChange ) ) { 18 var tr = document.createElement( "tr" ); 19 20 var td = document.createElement( "td" ); 21 var tdtxt = document.createTextNode( txt[ counter ].years ); 22 td.appendChild( tdtxt ); 23 tr.appendChild( td ); 24 td = document.createElement( "td" ); 25 tdtxt = document.createTextNode( txt[ counter ].books ); 26 td.appendChild( tdtxt ); 27 tr.appendChild( td ); 28 td = document.createElement( "td" ); 29 tdtxt = document.createTextNode( txt[ counter ].authors ); 30 td.appendChild( tdtxt ); 31 tr.appendChild( td ); 32 tabbd.appendChild( tr ); 33 } 34 }
Целью этой статьи не является объяснение основ DOM. Поэтому я остановлюсь только на наиболее важном моменте - необычном условии цикла for. Итак, createTable принимает четыре аргумента. Первый из них (cStart) - определяет значение счетчика в цикле for. Второй (cType) - тип сравнения, то есть значения ">", "<" и т.д. Третий аргумент ( cSize ) определяет значение, при сравнении с которым прекращается цикл. Четвертое же значение (cChange) может становиться инкрементом или декрементом, в зависимости от требования сортировки. Желательно подробно разобраться в этой строке кода, она достаточно важна. Без этих четырех аргументов пришлось бы писать несколько отдельных функций, которые бы различались только в этой строке. Этот прием достаточно удобный для общего применения, и я не исключаю возможности, что вы захотите его использовать в своих функциях.
Осталась последняя функции - allocator, которая, собственно, и управляет всеми сортировками и созданием таблицы. Листинг 10 :
Владимир Дригалкин
Сколько ни блуждал я просторами интернета - ни на чьем сайте не видел всплывающих окон, созданных с помощью метода TextPopup HTML Help ActiveX control. А ведь это самый простой, корректный и эффективный способ для вывода небольших комментариев, разъяснительной информации:
Синтаксис метода TextPopup таков:
TextPopup (pszText, pszFont, horzMargins, vertMargins, clrForeground, clrBackground)
Теперь давайте рассмотрим атрибуты данного метода:
PszText - текст, который будет отображен во всплывающем окне;
PszFont - атрибуты шрифта, которые указываются через запятую в следующем порядке:
название шрифта (например, Tahoma, Arial и т.п.); размер шрифта (числовое значение); кодировка символов шрифта (числовое значение - если не указывать, будет использована кодировка текущей страницы); начертание шрифта (может иметь элементы: PLAIN - обычный текст, BOLD - жирный, ITALIC - курсив, UNDERLINE - подчеркнутый).
Вот, например, способ применения атрибута PszFont - "Verdana,8,,BOLD";
HorzMargins - размер окна по горизонтали;
VertMargins - размер окна по вертикали;
ClrForeground - цвет текста в RRGGBB формате. По умолчанию - черный (-1);
ClrBackground - цвет фона всплывающего окна. По умолчанию - ярко-желтый (-1).
Итак, атрибуты мы рассмотрели, теперь можно приступить к созданию всплывающего окна. Для этого нам нужно вставить в HTML файл - объект HTML Help ActiveX:
<OBJECT id=test type="application/x-oleobject" classid="clsid:adb880a6-d8ff-11cf-9377-00aa003b7a11"> </OBJECT>
При этом совершенно не важно, где именно будет помещен он в HTML-странице. Заметьте, что идентификатору id присвоено имя test - оно может быть любым, но обязательно должно совпадать с именем при вызове JavaScript.
Добавление поддержки новых MIME типов в Apache TomCat.
Мы выполним данную настройку "глобально" для всего TomCat, чтобы этот MIME тип был описан для всех Web-приложений контейнера, но такого же эффекта можно добиться, если добавить дополнительные MIME типы ТОЛЬКО в web.xml отдельного web-приложения, которое будет вами сделано на сервере для деплоймента клиенского ПО. Для добавления новых MIME типов, мы находим в каталоге JBoss, подкаталог в котором установлен TomCat. В случае JBoss 3.x - это скорее всего каталог: ...\jboss\catalina\
Находим конфигурационный файл - ...\jboss\catalina\conf\web.xml.
В последних версиях JBoss 3.2.x данный файл необходимо искать в каталоге:
...\jboss-3.2.3\server\default\deploy\jbossweb-tomcat41.sar\web.xml
В данном файле находим раздел, где описаны MIME типы, проверяем есть ли они уже в списке описанных. jnlp, jar - обычно уже есть, а вот jardiff - скорее всего необходимо добавить. При их полном отсутствии добавляем, например в начало списка, еще три дополнительных типа:
web.xml ....... <!-- ========= Default MIME Type Mappings ========== --> <mime-mapping> <extension>jnlp</extension> <mime-type>application/
x-java-jnlp-file</mime-type> </mime-mapping> <mime-mapping> <extension>jar</extension> <mime-type>application/
x-java-archive</mime-type> </mime-mapping> <mime-mapping> <extension>jardiff</extension> <mime-type>application/x-java-archive-diff</mime-type> </mime-mapping>.............................
Если дать "грубое пояснение", то этими действиями мы указали Web-контейнеру выполнять "специальную интерпретацию" файлов с расширениями - jnlp, jar, jardiff. После HTTP запроса (request) клиентом у контейнера файла-ресурса с одним из указанных расширений, контейнер должен поставить в заголовке HTTP ответа (response) соответствующий "Content-Type", равный - application/x-java-jnlp-file, application/x-java-archive, application/x-java-archive-diff. При этом указанное "Content-Type" значение в HTTP ответе, позволит Java Web Start на стороне клиента, обработать данный поток данных "специальным образом".
Замечание: Будьте внимательны с тем, что можно легко перепутать расширение файлов *.jnlp, ошибочно назвав *.jnpl, как в настройках Web-контейнера, так и в названиях файлов.
Добавление необходимых параметров в web.xml файл WAR-приложения.
Кроме этого необходимо, описать необходимые настроечные параметры у нашего Web-приложения в файле ...\jboss-3.2.1\server\default\deploy\application.war\WEB-INF\web.xml. Согласно документации в него нужно дописать следующие настройки, которые выделены красным цветом:
<?xml version="1.0"?><!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd"> <web-app> <servlet> <servlet-name>JnlpDownloadServlet</
servlet-name> <servlet-class>com.sun.javaws.servlet.
JnlpDownloadServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>JnlpDownloadServlet</servlet-name> <url-pattern>*.jnlp</url-pattern> </servlet-mapping>
<welcome-file-list> <welcome-file>index.html</welcome-file> </welcome-file-list> <web-app>
Еще одно из требований для корректной работы JNLP сервлета, описанного в примере настройки - это наличие XML парсера. Для этого необходимо, что либо сам Web-контейнер был запущен с помощью JRE 1.4 , в которой парсер интегрирован, или чтобы парсер был доступен серверу как библиотека. В нашем случае, т.к. JBoss имеет в поставке XML парсер (Xerces), никаких дополнительных действий делать НЕ НАДО. В случае если ваша ситуация отличается, то добавьте парсер в Web-приложение - каталог где хранятся библиотеки приложения ...\application.war\WEB-INF\lib\
Теперь опишем КАК выглядит индексная страница, с которой осуществляется установка и запуск наших клиентских приложений на локальных ПК пользователей. Простейший вид страницы index.html :
index.html
<html><head><title>
Клиентские приложения</title>
<meta http-equiv="content-type"
content="text/html; charset=Windows-1251"></head>
<body><h3><center> Внутренние корпоративные клиентские
приложения. </center></h3><ul><li>Клиентское приложение 1.0.x : <a href="application.jnlp">
Клиент 1.0</a></ul>
</body> </html>
Страница имеет ссылку, указывающую на JNLP файл нашего приложения. По нажанию ссылки в броузере, будет происходит загрузка и запуск Java-приложения на клиентском ПК.
Настройка поддержки JNLP (Java
К сожалению, мне пока не приходилось настраивать JNLP на сервере JBoss, который использует в качестве Web-контейнера Mortbay Jetty, а только Apache TomCat. Но посмотрев внутренности Jetty, могу сказать, что это тоже вполне возможно сделать аналогичным способом. Нужно только внимательно посмотреть и найти файлы настроек в JAR архивах данного Web-контейнера, в которые понадобиться внести аналогичные добавления.
Итак, какие изменения вносят на сервере...
Как настроить броузер Opera 7.x для корректной работы с JNLP файлами.
Если вы попробуете запустить Java-приложение в броузере Opera кликнув на ссылке http://localhost:8080/application/application.jnlp , то скорее всего увидите следующее окно, в котором Opera предлагает сохранить или открыть файл.
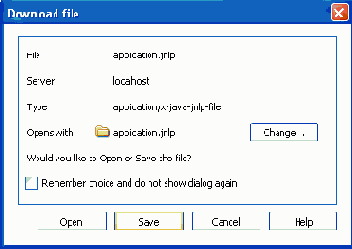
Можно открыть файл, нажав кнопку "Open". А можно нажать кнопку "Change..." и установить обработку данного MIME-типа и расширения файлов "по умолчанию".
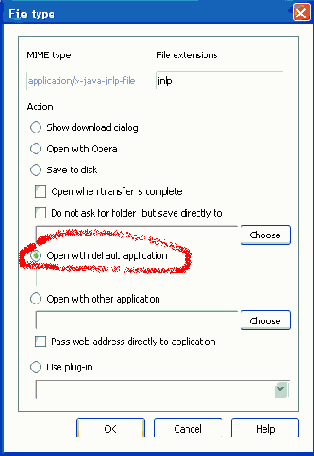
Отметьте пунк "Open with default application" и Opera будет всегда открывать JNLP файлы с помощью Java Web Start.
Пробуем запустить.
Все готово к первому запуску Java-приложения. Запускаем JBoss, сначала WAR-приложение должно успешно задеплоиться. В логах вы должны увидеть приблизительно следующее:
server.log
INFO [org.jboss.deployment.MainDeployer]
Starting deployment of package: file:/....../jboss/server/default/
deploy/application.war/INFO [org.jboss.web.catalina.EmbeddedCatalinaServiceSX]
deploy, ctxPath=/application, warUrl=file:/...../jboss/server/default/
deploy/application.war/ ............................................ ............................................ INFO [org.jboss.deployment.MainDeployer]
Successfully completed deployment of package: file:/......./jboss/server/default/
deploy/application.war/
Если этого не произошло - проверяйте все настройки и параметры Web-приложения.
Заходим с помощью IE на страницу нашего Web-приложения по адресу, например, http://localhost:8080/application/
На странице мы должны увидеть нашу ссылку на JNLP файл в виде - http://localhost:8080/application/application.jnlp
Щелкнув на ней мы должны увидеть Splash-скрин запуска Java Web Start. Для версии JDK 1.4.2 он выглядить примерно так:
После этого на сервере в логе должны появиться записи об обращении к JNLP-сервлету примерно такого вида:
server.log
INFO [org.jboss.web.localhost.Engine]
JnlpDownloadServlet: initINFO [org.jboss.web.localhost.Engine] InitializingINFO [org.jboss.web.localhost.Engine]
Request: /application/application.jnlpINFO [org.jboss.web.localhost.Engine]
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;
.NET CLR 1.1.4322) INFO [org.jboss.web.localhost.Engine]
DownloadRequest[path=/application.jnlp isPlatformRequest=false] INFO [org.jboss.web.localhost.Engine]
Basic Protocol lookupINFO [org.jboss.web.localhost.Engine] JnlpResource: JnlpResource
[WAR Path: /application.jnlp lastModified=........ EET 2004]]INFO [org.jboss.web.localhost.Engine]
Resource returned: /application.jnlpINFO [org.jboss.web.localhost.Engine]
lastModified: ....... EET 2004
Если все происходит нормально, то после этого вы увидите как на ваш ПК в локальный кэш загружаются JAR библиотеки приложения, после чего приложение будет запущено. Но скорее всего в первый раз вы можете получить окно с сообщением о какой-либо ошибке. Я внес в свой JNLP файл небольшую ошибку, нарушив структуру application.jnlp XML файла. Сообщение об ошибке обычно выглядит, например, так :
Также если ваше приложение загружается в этаком "бесконечном цикле", типа "вроде бы грузиться и вроде бы совсем НЕ грузиться", а подождав некоторое время, вы получаете сообщение об "невозможности загрузить приложение" - проверьте настройки прокси-сервера, их скорее всего необходимо изменить.
Теперь мы можем посмотреть на причину данной ошибки, нажав кнопку - Details. В моем случае оно выглядело так:
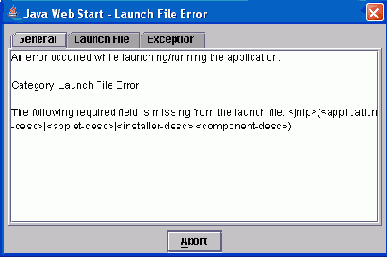
Другие закладки дают дополнительную информацию о причине и характере ошибки:
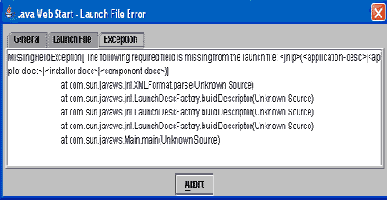
Ошибка указывает на то, что наш JNLP файл имеет не совсем корректную структуру. В вашем конкретном случае, ошибка может оказаться совсем не такой, потому что сделать ошибки всегда "хватает возможностей"...
Исправив ошибку в application.jnlp, который находиться на сервере, мы сразу выполняем повторный запуск Java-приложения. Если все получилось, что вы увидите окно показывающее загрузку библиотек:
После чего будет предложено выполнить интеграцию вашего Java-приложения с Windows, создав "ярлык запуска" приложения на рабочем столе.
Если вы ответите на вопрос положительно на рабочем столе появиться ярлык для запуска клиентского Java-приложения, которым можно пользоваться "напрямую", НЕ запуская броузер.
После этого должен произойти запуск вашего GUI приложения. Если этого НЕ происходит, то это означает, что клиентское приложение выполнилось с какой-то ошибкой. Способ обнаружения, отображения и записи ошибок в клиентском Java-приложении полностью зависит от вашей реализации. Если вы захотите логировать ошибки и/или сообщения в локальный файл, то будет необходимо выполнить дополнительне действия по настройке и подписыванию библиотек сертификатом, о которых я расскажу в другой статье. Вы также можете самостоятельно прочитать, как и что для этого нужно сделать, в документации Java Web Start.
Также после успешной установки Java-приложения на клиентский ПК в JWS Application Manager появиться ссылка на ваше приложение, с указанием источника. Там же с помощью иконок в правом нижнем углу JWS сообщает об доступности новых версий библиотек данного приложения.
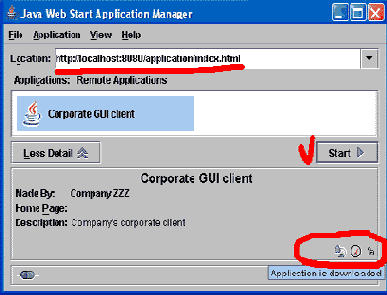
Что еще можно увидеть в настройках JWS. Например кэш, в котором храняться Java-приложения, установленные с помощью JWS расположен в каталоге настроек пользователя:
На закладке "Advanced" можно увидеть каталог кэшированного приложения, в моем случае это был D:\Documents and Settings\Blandger\Application Data\Java\....... При этом также указывается текущий размер занимаемый приложением - 3110 Кб, в любое время вы можете легко очистить кэш, используя кнопку - "Clear Folder".
Теперь, если вы дочитали до этого места и все-таки не совсем поняли что происходит. Как вы думаете, что теперь необходимо сделать для обновления Java-приложения на локальных ПК пользователей после того, как мы собрали новую версию GUI приложения, или например решили использовать более свежую версию какой-то сторонней библиотеки ?
Мы должны всего лишь скопировать новые версии библиотек в каталог сервера ...\jboss-3.2.1\server\default\deploy\application.war\ , у меня это файлы: main_gui.jar, main_gui_lib.jar (или например библиотеки - xercesImpl.jar, xmlParserAPIs.jar). При последующем запуске GUI приложения на клиентском ПК с помощью Java Web Start данные JAR файлы будут скачены на ПК, после чего приложение будет запущено с новыми версиями библиотек. Вот и все действия для обновления !
Развертывание приложения с помощью Java Web Start.
Yuriy Larin aka Blandger
Оригинал статьи - на сайте
В данной статье я хочу рассказать о своем опыте по развертыванию и последующему "автоматическому" обновлению версий GUI клиента с помощью использования технологии Java Web Start в среде Windows. Java Web Start может быть использован в оперционных системах: Windows(95, 98, ME, NT, W2K, XP), Linux, Unix (Solaris) и не так давно в Macintosh OS X. Для развертывания приложений используется HTTP протокол, поэтому можно воспользоваться любым HTTP сервером. Но для того, чтобы использовать ВСЕ возможности, предоставляемые технологией Java Web Start, такие как "версионность" Java-приложений и "наращивающихся обновлений" (incremental update), необходимо использовать Web-сервер, поддерживающий сервлеты (Servlets) или CGI-скрипты. Мы воспользуемся сервером приложений, в нашем случае это JBoss 3.x.x, и обычно "встроенным" в него Web-контейнером - Apache TomCat. В статье я расскажу, ЧТО необходимо сделать для настройки поддержки JNPL протокола на сервере JBoss 3.x.x , использующим в качестве Web-контейнера именно Apache TomCat, поставляемый вместе с JBoss.
Создание архива Web-приложения
В каталоге JBoss, предназначенного для деплоймента J2EE приложений, создадим новое Web-приложение. Его можно создать любым удобным способом, я предлагаю сделать так: пусть это будет "default" конфигурация. Внутри деплоймент каталога, создаем каталог web-приложения с названием, указанным в JNLP файле, это будет - ..\application.war
...\jboss-3.2.1\server\default\deploy\application.war\
В моем случае содержимое WAR приложения выглядит так:
\application.war\ index.html
<-- Файл содержащий URL-ссылку на JNLP файл клиентского Java-приложения application.jnlp
<- специально написанный XML файл с раширением jnlp, описывающий состав и параметры
клиентского приложения
main_gui.jar
<- главные архивы классов клиентского приложения main_gui_lib.jar
jboss-client.jar
<- библиотеки необходимые для выполнения jboss-common-client.jar
приложения на ПК пользователя jboss-j2ee.jar jbossmq.jar jbosssx-client.jar jnp-client.jar xercesImpl.jar xmlParserAPIs.jar
\application.war\WEB-INF\ jboss-web.xml web.xml
<- файл дескриптор Web-приложения
\application.war\WEB-INF\lib\ jardiff.jar
<- библиотеки, содержащие классы, jnlp-servlet.jar
необходимые для поддержки JNLP сервером, которые jnlp.jar
доступны из "JNLP пакета разработчика"
Создание JNLP файла, описывающего ваше клиентское приложение, его библиотеки и другие параметры.
Для того, чтобы Java Web Start мог знать какие именно файлы необходимы для запуска и работы вашего клиентского приложенния, необходимо создать специальный JNLP файл, имеющий XML формат. Данный файл будет помещен на сервере JBoss в Web-приложение, предназначенное для выполнения деплоймента GUI.
Я приведу здесь краткий и простейший пример JNLP файла, использованного для деплоймента, и дам небольшие пояснения о тегах файла и их значениях. Для более детального описания всех параметров и всех возможностей данной технологии, я очень рекомендую вам обратиться к документации разработчика на сайте Sun Microsystems.
<?xml version="1.0"
encoding="Windows-1251"?> ...............<jnlp spec="1.0+"
<!-- Номер JNLP спецификации -->
codebase="http://localhost:8080/application" <!--URL по которому находиться JNLP
файл, можно написать в виде codebase="$$codebase" -->
href="application.jnlp" > <!--название JNLP файла-дескриптора
нашего приложения можно написать в виде href="$$name" -->
<information> <title>Corporate GUI client</title> <vendor>Company ZZZ</vendor> <description>Company's
corporate client</description> </information> <resources> <j2se version="1.3+"/>
<!--Указание необходимой версии JDK приложения--> <jar href="main_gui.jar"
main="true"/><!--Файлы нашего клиентского приложения--> <jar href="main_gui_lib.jar" />
<jar href="jboss-client.jar"/> <jar href="jboss-common-client.jar"
/> <!--Перечисление всех файлов сторонних--> <jar href="jboss-j2ee.jar"/>
<!--библиотек, необходимых для запуска--> <jar href="jbossmq.jar"/>
<!--нашего приложения --> <jar href="jbosssx-client.jar"/> <jar href="jnp-client.jar"/> <jar href="xercesImpl.jar"/> <jar href="xmlParserAPIs.jar"/> <property name="java.naming.
provider.url" value="localhost:1099"/> <!-- Указание свойства, которое
используется нашим приложением --> </resources> <application-desc main-class="
com.my_company_name.client.Application" /> <-- Название класса с main()
точкой запуска --></jnlp>
codebase="http://localhost:8080/application" - указывает на параметр " базы кода" по которому мы будем хранить все необходимые библиотеки, как JAR файлы нашего приложения, так и JAR файлы "сторонних библиотек". Данный параметр можно заменить "специальной переменной", фактическое значение которой jnlp-сервлет поставит самостоятельно при обработке запроса. codebase="$$codebase"
href="application.jnlp" - название JNLP файла-дескриптора, который описывает наше приложение. Данный параметр также можно заменить "специальной переменой", фактическое значение которой jnlp-сервлет поставит при обработке запроса. href="$$name"
В разделе ресурсов, есть указание использования JRE версии 1.3 и более новых - <j2se version="1.3+"/>. А вообще, элемент <resources> может содержать 6 различных подэлементов, таких как: jar, nativelib, j2se, property, package и extension. Подробности и правила можно найти в документации.
<jar href="main_gui.jar" main="true"/> - Указание библиотеки, в которой находятся классы нашего приложения, при этом параметр main="true", указывает что данный JAR архив содержит запускаемый класс GUI приложения.
<jar href="jboss-client.jar"/> - далее перечислены все наобходимые библиотеки, которые будут получены с сервера и кэшированы на клиенте
<property name="java.naming.provider.url" value="localhost:1099"/> - так мы можем перечислить все, передаваемые в качестве параметров запуска приложению свойства, которые получаются вызовом System.getProperty(....)
<application-desc main-class="com.my_company_name.client.Application" /> - указание полного запускаемого класса. JWS также поддерживает запуск Applet-ов. В этом случае вместо тэга <application-desc> используется тэг <applet-desc>. Принцип написания и параметры - смотрите в документации.
Что касается элемента <information> JNLP файла. В данном тэге значения подэлементов <title> и другие, наверное, пока что лучше указывать на английском языке. В последней версии Java Web Start (1.2) из версии JDK 1.4.2_04-b05 название на русском языке в JNLP файле, вызвали ошибку при конвертировании русских букв. Ошибка наблюдалась в логе JBoss (server.log):
Требования к Java-приложениям и настройки на клиентском ПК.
Так как работа Java Web Start основана на использовании JNLP-протокола, то выполнить настройки необходимо как на стороне СЕРВЕРА, так и на стороне КЛИЕНТА.
Для установки Java-приложений на локальном ПК нам понадобиться установленный Java Web Start (Application Manager) и веб-броузер. Броузер требуется только для первоначального запуска Java-приложения и после запуска может быть закрыт, в то время как приложение будет продолжать работать. В качестве броузера лучше сначала использовать IE, т.к. он работает корректно сразу. Также можно воспользоваться и другими броузерами (Mozilla, Opera 7.x), но для этого необходимо выполнить в них небольшие настройки. Как настроить Opera 7.x для правильной работы с JNLP файлами, я написал в самом конце этой статьи, аналогичным образом должны настраиваться и другие броузеры.
Если Java-приложение запускается часто, то в среде Windows можно с помощью Java Web Start, создать стандартный "ярлык приложения" на рабочем столе и запускать Java-приложение НЕ ИСПОЛЬЗУЯ броузер, а пользуясь только ярлыком. Также можно запускать Java-приложение из командной строки.
Как уже было сказано, Java Web Start, всегда доступен как при установке JRE 1.4.x, так и при установке JDK 1.4.x, поэтому нам ничего не остается сделать как воспользоваться его возможностями. К сожалению для версии JDK/JRE 1.3 его нужно устанавливать отдельно. Но я бы НЕ советовал этого делать, т.к. на мой взгляд он сыроват и лучше всего перевести код вашего приложения на версию JDK 1.4, тем более что GUI клиент прекрасно взаимодействует с сервером под JDK 1.3. Проблем с передачей сериализированных объектов между версиями JDK 1.3 <-> 1.4 замечено не было.
Кроме этого Java Web Start предъявляет определенные требования к написанному клиентскому Java-приложению. Приложение должно поставляться как набор JAR-файлов, все ресурсы приложения, такие как изображения, конфигурационные файлы, Native библиоткуи (DLL, SO), необходимо включать в JAR-файлы. Ресурсы в коде должны получаться с помощью ClassLoader getResource или подобных методов. Приложение запускается на клиентском ПК с правами доступа, выданных для "стандартной песочницы" (sandbox), со всеми вытекающими последствиями. Поэтому если вам необходим неограниченный доступ к локальным файлам - потребуются дополнительные настройки и подписывание библиотек кода с помощью сертификата. Также для хранения локальных клиентских настроек в JWS имеется специальное PersistenceService API, которое чем-то похоже на "cookies" и позволяет безопасным способом хранить локальные настройки на ПК. Кроме этого, есть еще другие API - BasicService, ClipboardService, DownloadService, FileOpenService, FileSaveService, PrintService.
Что такое Java Web Start?
Что такое Java Web Start? Это небольшая, бесплатно распространяемая программа на клиентском ПК ассоциированная с веб-броузером. Когда пользователь щелкает в броузере на HTML странице ссылку, указывающую на специальный JNLP (Java Network Launching Protocol) файл запуска Java-приложения, это приводит к запуску Java Web Start, который в свою очередь автоматически скачивает файлы приложения с Web-сервера, кэширует их и запускает описанное Java-приложение. Java Web Start идет в стандартной инсталляции как JRE 1.4.х так и и JDK 1.4.x. Стоит сказать, что Java Web Start - это кроме того и набор технологий + API, который позволяет очень легко решить вопрос установки Java-приложений (также и Applet-ов) и их последующего "автоматического" обновления на любом ПК в корпоративной (и не только корпоративной) среде. После "единичной" настройки самого Java Web Start на клиентском ПК и установки вашего Java-приложения, все необходимые для работы JAR библиотеки кэшируются на клиентском ПК. Последующие обновления приложения (при обновлении функциональности приложения, при устранении в коде ошибок) на клиентском ПК выполняются при запуске приложения АВТОМАТИЧЕСКИ. Т.е. Java Web Start позволит вам не заботиться об обновлении Java-приложения на локальных ПК, и выполнит это "самостоятельно и автоматически", проверяя и скачивая новые версии НЕ ТОЛЬКО написанных ВАМИ модулей, но также и обновленные версии используемых клиентским приложением сторонних библиотек. При этом на клиенте происходит обновление только тех файлов библиотек, которые изменились на сервере. Когда код вашего клиентского приложения обновился и вам требуется обновить его на локальных ПК, вам потребуется ВСЕГО ЛИШЬ положить новые версии JAR-библиотек приложения на сервер приложений (в WAR-приложение). При запуске установленного и кэшированного на клиенте приложения, Java Web Start выполняет сравнение локальных версий файлов и файлов на сервере. При изменении файлов на сервере, выполняется выборочное скачивание ТОЛЬКО изменившихся JAR файлов.